 1142
1142 
Содержание
Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache Kafka и Spark.
Зачем анализировать сетевой трафик и как это сделать в реальном времени
Анализ сетевого трафика позволяет обнаружить паразитный, вирусный и закольцованный трафик, чтобы снизить загрузку сетевого оборудования и каналов связи. Также это помогает выявить в сети вредоносное и несанкционированное ПО (сетевые сканеры, флудеры, троянские программы, клиенты пиринговых сетей и пр.), локализовать неисправность сети или ошибку конфигурации сетевых агентов. Раньше эта важная задача системного администратора чаще всего решалась с помощью метода захвата пакетов (package capture). Но на практике это слишком дорого, т.к. для большинства аналитических кейсов достаточно лишь метаданных сетевого пакета, без полного содержимого его полезной нагрузки [1].
Сегодня одним из популярных протоколов учёта сетевого трафика является сетевой протокол NetFlow, разработанный компанией Cisco Systems. Он стал промышленным стандартом де-факто и поддерживается не только оборудованием Cisco, но и многими другими устройствами. Для сбора информации о трафике по протоколу NetFlow требуются следующие компоненты [2]:
- сенсор, который собирает статистику по проходящему через него трафику — L3-коммутатор или маршрутизатор. Также можно использовать и отдельно стоящие сенсоры, которые получают данные от зеркалирования порта коммутатора.
- Коллектор для сбора данных от сенсора данные и помещения их в хранилище.
- Анализатор для анализа собранных коллектором данных и формирования отчетов в виде графиков и таблиц.
Современные устройства анализа сетевого трафика объединяют все эти компоненты. Например, NetFlow-коллектор nProbe от итальянской компании NTOP² может проверять пакеты и извлекать их метаданные с 4-го уровня на уровень 7 модели OSI в виде сетевых потоков со скоростью до 100 Гбит на штатном оборудовании. Помимо сбора входящих пакетов и вычисления NetFlow-показателей, он подходит для классификации трафика через DPI (Deep Packet Inspection). Также он может выполнять дополнительные действия с выбранными пакетами/потоками при перенаправлении трафика в сочетании с другими приложениями, такими как IPS / IDS, регистраторы трафика и т.д. [3].
Таким образом, задача анализа трафика в реальном времени сводится к организации конвейера сбора и аналитики метаданных сетевых пакетов. Как это сделать с помощью технологий Big Data, в частности, Apache Kafka и Spark на платформе Databricks, мы рассмотрим далее.
Apache Kafka и Spark для real-time анализа сетевого трафика
Самая простая, но весьма эффективная архитектура системы аналитики сетевого трафика в реальном времени с помощью технологий Big Data и многофункциональных NetFlow-коллекторов выглядит следующим образом [1]:
- один или несколько коллекторов nProbe постоянно собирают сетевые потоки;
- NetFlow-данные передаются в Apache Kafka в режиме реального времени;
- Сам процесс потоковой аналитики больших данных выполняется в кластере Apache Он может быть развернут на платформе Databricks или в Amazon EMR.
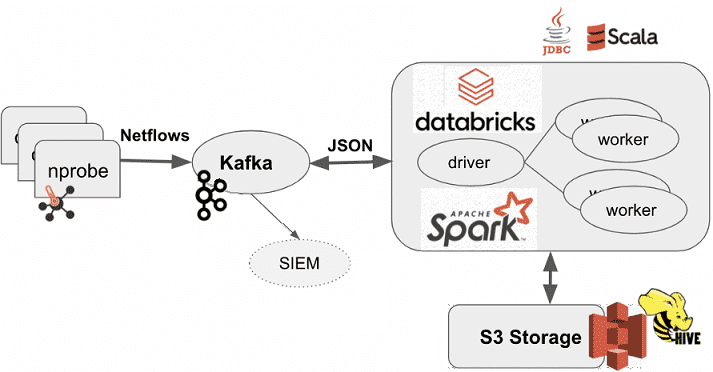
Коллектор nProbe позволяет указать формат потоков NetFlow v9/IPFIX и экспортировать их в Apache Kafka в формате JSON. Вообще nProbe поддерживает около 200 опций различных показателей, включая атрибуты, указанные в NetFlow v9 RFC³. Для точного задания этих настроек, помимо выбора формата JSON и экспорта потоков в топики Kafka, в файле конфигурации nprobe.conf указано 50 полей, включая настраиваемое поле с константой для идентификации коллектора.
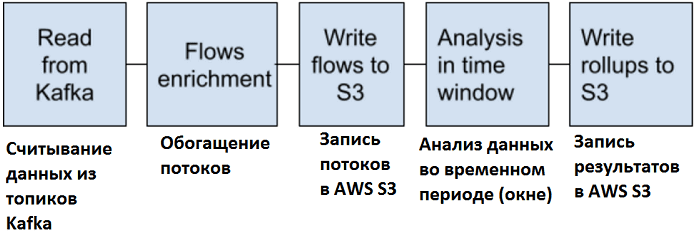
Сам конвейер приема и обработки данных выглядит следующим образом [1]:
- сперва выполняется считывание данных из Kafka. В рассматриваемом примере создано 2 топика Kafka: один используется коллекторами nProbe для публикации NetFlows, а во второй в реальном времени записываются подозрительные пакеты для последующей обработки.
- Далее выполняется обогащение данных с помощью Spark-приложений;
- Обогащенные сетевые потоки записываются в озеро данных (Data Lake) в объектном хранилище AWS S3;
- за анализ метаданных отвечают оконные SQL-запросы Apache Spark;
- Результаты анализа сохраняются в AWS S
Отметим, что в записной книжке платформы Databricks можно легко подключить существующую пустую корзину AWS S3 к файловой системе Databricks (DBFS), чтобы предоставить доступ к данным в объектном хранилище, как будто они находятся в локальной файловой системе:
dbutils.fs.mount(s«s3a://meg-netflows», s«/mnt/flows-datasets»)
display(dbutils.fs.ls(s«dbfs:/mnt/flows-datasets»))
При этом для правильной S3-аутентификации ключ AWS и секрет к нему должны быть установлены как переменные среды Spark в кластере Databricks или добавлены в путь корзины. Рекомендуется использовать новую версию s3a, собственного коннектора s3n, чтобы обеcпечить взаимодействие Apache Spark c Amazon S3.
Kafka является обычным источником данных для Spark, поэтому поток из топика этой платформы считывается в датафрейм Spark.
В Spark SQL есть функция from_json(), которая принимает входной столбец данных JSON и создает структурированный выходной столбец. Но для вызова этой функции необходимо предоставить схему для объектов JSON. Используемая для этого схема данных jsonDF состоит из двух атрибутов: отметки времени прибытия, добавленной Kafka, и строкового значения с JSON NetFlow.
С помощью заданной схемы можно проанализировать JSON, содержащийся в столбце значений, а функция from_json() позволит получить доступ к данным из определенного столбца.
NetFlow-данные сохраняются в озере данных на AWS S3 как сжатые объекты Parquet по мере их поступления из Kafka, по одному в минуту, иерархически организованные по году, месяцу, дню и часу. А использование метода partitionBy() приводит к разделению в стиле Hive, что увеличит скорость выполнения SQL-запросов. Подробный код рассмотренного примера приведен в источнике [1].
Таким образом, мы в очередной раз показали, что Apache Spark и Kafka – это мощные технологии Big Data, которые позволяют создавать конвейеры, сочетающие прием, анализ и агрегацию данных в реальном времени. Это весьма полезно для анализа сетевого трафика, особенно при использовании с современными коллекторами потоков, которые генерируют метаданные в результате глубокой проверки пакетов.
Еще больше интересных примеров разработки распределенных приложений потоковой аналитики больших данных с Apache Kafka и Spark вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
Источники

