 1172
1172 
Содержание
Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура.
Еще раз об аналитике Big Data для бизнеса: маркетинговая постановка задачи
Реклама и маркетинг до сих пор остаются самими крупными потребителями технологий Big Data и Data Science. Причем современный бизнес не только стремится удовлетворить возникшую потребность клиента, но и сформировать ее, простимулировав спрос или предугадав желания потребителя. К примеру, посетители парков отдыха, летних фестивалей и спортивных мероприятий на открытом воздухе заинтересованы в быстрой доставке продуктов для пикника или готовых блюдах. Идентифицировать потенциального клиента можно с помощью онлайн-анализа его активности в социальных сетях. Например, хэштеги #отдых, #паркгорького, #выходные и т.д. под фотографиями в Instagram или Twitter вместе с данными геолокации указывают на то, что именно сейчас человек прогуливается в конкретном районе и, возможно, в зависимости от погоды, с удовольствием выпьет горячий кофе или прохладный зеленый чай, закусив сытным бургером или ЗОЖ-ланчем. Конечно, если пользователь в это самое время не находится в кафе, т.е. в сообщении отсутствуют хэштеги #кафе, #обед, #летняяверанда и пр. Анализируя подобные посты и твиты в реальном времени, фудтех-компания может значительно повысить свою прибыль за счет таких ситуативных продаж.
Таким образом, ключевыми возможностями системы потоковой аналитики больших данных для этого случая будут следующие:
- масштабируемость, точность и высочайшая скорость обработки данных (в реальном времени или near real-time);
- интеллектуальный анализ собранной информации и автоматизированное принятие решений, например, генерация персональных спецпредложений с учетом исторических интересов клиента и его текущих характеристик, таких как геолокация, время суток, погода и прочие факторы;
- визуализация результатов анализа на интерактивном дэшборде.
Как это реализовать на практике, рассмотрим далее.
Архитектура ML-системы потоковой аналитики больших данных
Типичная для вышеописанной потребности Big Data система имеет классическую Kappa-архитектуру, которая позволяет относительно недорого обрабатывать уникальные события в реальном времени без глубинного исторического анализа. Технически это можно реализовать следующим образом [1]:
- считывать данные из соцсетей в real-time режиме;
- агрегировать их, извлекая интересующие хэштеги и определяя отношения между ними;
- производить вычисления, формируя персональные рекомендации с помощью моделей машинного обучения (Machine Learning);
- визуализировать результаты анализа данных в дэшборде BI-системы.
В частности, Twitter API позволяет получать данные в реальном времени, обрабатывать их и передавать далее по конвейеру обработки, который будет выглядеть так:
- данные собираются в формате JSON с помощью API Twitter и записываются в топики Apache Kafka для онлайн-аналитики, а также в Hadoop HDFS для формирования истории;
- за пакетные и потоковые вычисления, а также ML отвечают Spark-приложения;
- в качестве аналитического хранилища данных подойдет NoSQL-СУБД, которая лучше всего отвечает заранее определенным требованиям к хранению и скорости считывания/записи данных, например, Apache HBase, Hive, Greenplum, Cassandra, Elasticsearch и т.д.
- для генерации отчетов и визуализации результатов анализа данных можно использовать готовые BI-решения, например, Tableau, интегрированное с аналитической СУБД с помощью специальных коннекторов.
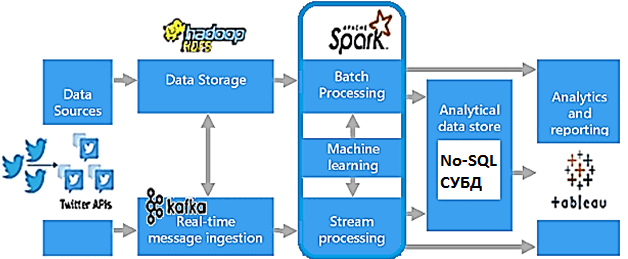
Однако, реализовать подобную систему онлайн-аналитики больших данных можно не только с помощью отмеченных на рисунке технологий Big Data. Читайте далее, какие альтернативы возможны для каждого из описанных компонентов.
Apache Kafka и другие технологии реализации
Сложность связывания компонентов системы между собой и наличие готовых интеграционных коннекторов может стать критерием выбора того или иного фреймворка. Например, в октябре 2020 года вышел релиз Greenplum-Spark Connector 2.0, о котором мы рассказывали здесь. А связать ту же MPP-СУБД Greenplum с Apache Kafka можно с помощью Greenplum Stream Server (GPSS) или Java-фреймворка PXF (Platform eXtension Framework), что мы разбирали в этой статье. А про особенности создания собственного коннектора Apache Spark к BI-системе Tableau читайте в этом материале.
Кроме того, в качестве критериев выбора аналитической СУБД можно использовать необходимые функциональные и нефункциональные требования к этому компоненту системы. Например, у Elasticsearch почти мгновенная индексация новых данных в JSON-и других полуструктурированных форматах с поддержкой нечеткого поиска и модулями ML, о чем мы упоминали здесь. А встроенная интеграция с Kibana позволит визуализировать результаты аналитики данных, как это было сделано в кейсе по анализу конверсии рекламных объявлений. Преимуществом такого варианта решения является отсутствие затрат на коммерческую лицензию BI-системы Tableau – вместо нее используется связка Apache Kafka с компонентами ELK-стека (Elasticsearch, Logstash, Kibana). А за реализацию алгоритмов машинного обучения отвечает код на PySpark во фреймворке Spark [2].
Впрочем, подобные возможности предоставляет и Apache Flink, который можно использовать вместо Spark, если требуется быстрая обработка данных в режиме действительно реального времени. Аналогично Spark, фреймворк Flink также предоставляет модули SQL и библиотеки Machine Learning, в т.ч. набор алгоритмов Alink. Как и Spark, Flink позволяет писать код на Java, Scala и Python с улучшенной производительностью благодаря обновлениям в последнем релизе 1.13.0, выпущенном в мае 2021 года [3]. Ответы на вопрос «Apache Spark vs Flink» (чем похожи и чем отличаются эти распределенные фреймворки) ищите в нашей отдельной статье. О другом интересном кейсе реализации алгоритмов машинного обучения в PySpark читайте в новом материале. А пример применения Flink в мониторинге производственных процессов смотрите здесь.
Технические подробности реализации рассмотренного кейса и другие подобные примеры потоковой аналитики больших данных на базе Apache Kafka, Spark и Greenplum вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Greenplum для инженеров данных
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

