 1001
1001 
Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных упрощает тестирование и отладку data pipeline’ов, помогая разработчикам и инженерам.
Сложности тестирования Spark-приложений: кластера и локальные среды
Несмотря на то, что Apache Spark предоставляет гибкий и мощный API, создание конвейеров обработки данных из Spark-приложений – сложная и трудоемкая работа. На разных этапах разработки нужны совершенно разные настройки: некоторые ошибки можно быстро отловить локально на небольших датасетах, а другие требуют кластера и множества данных. Например, при тестировании и отладке задания PySpark нужно несколько раз выполнить целый ряд действий [1]:
- запустить облачный Spark-кластер;
- запустить задание и дождаться его завершения;
- просмотреть таблицы и графике в пользовательском интерфейсе, чтобы обнаружить, что обновленный код не был отправлен в кластер;
- отправить в кластер обновленный код;
- запустить Spark-задание и дождаться его выполнения;
- снова просмотреть отчеты в пользовательском интерфейсе, чтобы обнаружить ошибку.
При этом, некоторые ошибки, в частности, в синтаксисе или логике программы, можно найти локально, не отправляя код в облачный кластер. Таким образом, разработчику на разных этапах разработки и развертывания Spark-приложений нужны совершенно разные среды, к примеру:
- найти синтаксические и базовые логические ошибки можно в облегченной локальной установке с небольшим набором данных;
- для выявления редких случаев нужен репрезентативная выборка;
- для обнаружения проблем с распределенными вычислениями необходим кластер;
- чтобы выявить проблемы с производительностью, нужен объем данных рабочего размера, без перезаписи production-таблиц.
При этом для каждой настройки следует убедиться, что:
- указаны корректные места чтения и записи данных;
- задана верная конфигурация Spark;
- задания выполняются в соответствующем кластере;
- запускается нужная версия кода, что непросто при удаленном запуске.
Упростить этот запутанный процесс разработки и тестирования Spark-конвейеров можно с помощью современных платформ дата-инженерии с расширенным набором инструментов для отладки и поддержки эксплуатации. В частности, коммерческая Spark-платформа от Databricks поддерживает интеграцию с облачными сервисами Amazon и оркестратором Dagster, который расширяет и дополняет Apache AirFlow, упрощая разработку, запуск, тестирование и мониторинг data pipeline’ов. Подробнее о том, чем Dagster отличается от AirFlow, мы рассказывали здесь, здесь и здесь. А как именно этот Big Data оркестратор упрощает разработку и тестирование Spark-заданий, рассмотрим далее.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
6 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Dagster и PySpark
Dagster – это open-source оркестратор данных, который устраняет сложность разработки и отладки конвейеров из Spark-заданий, организуя код и настройки развертывания приложений. Он поставляется с предварительно созданными утилитами для развертывания кода Spark в таких средах, как AWS EMR и Databricks. Этот фреймворк отделяет бизнес-логику в Spark-заданиях от настроек среды, в которых они должны работать. Бизнес-логика представляется в виде направленного ациклического графа (DAG, Directed Acyclic Graph) функций Python (solids), каждая из которых принимает датафрейм в качестве входных данных и возвращает в качестве выходных.
В определение конвейера включается список режимов, каждый из которых описывает среду для запуска конвейера. Например, один режим для локального выполнения внутри процесса, а второй — для работы с кластером. Благодаря шаблонизации можно создать множество установок для различных режимов, например, для проверки на тестовом сервере и запуска в production.
Режимы предоставляют объект «ресурс» для каждого ключа требуемых ресурсов по любому solid’у в конвейере. Внутри самих solid-функций код может обращаться к ресурсам, например, запрашивая или предоставляя сессию Spark — объект SparkSession с заданными параметрами конфигурации. Еще благодаря механизму ресурсов можно запускать solid-функции как шаг в кластере EMR.
Режимы также могут определять промежуточное хранилище, где будут храниться промежуточные значения между этапами конвейера, например, в AWS S3. Подробный код рассматриваемого примера доступен на Github [2].
Пользовательский веб-интерфейс Dagster под названием Dagit позволяет наблюдать за работой конвейера в режиме онлайн: средство просмотра структурированных логов упрощает поиск по журналам, а диаграмма Ганта показывает, какие шаги задерживают завершение конвейера.
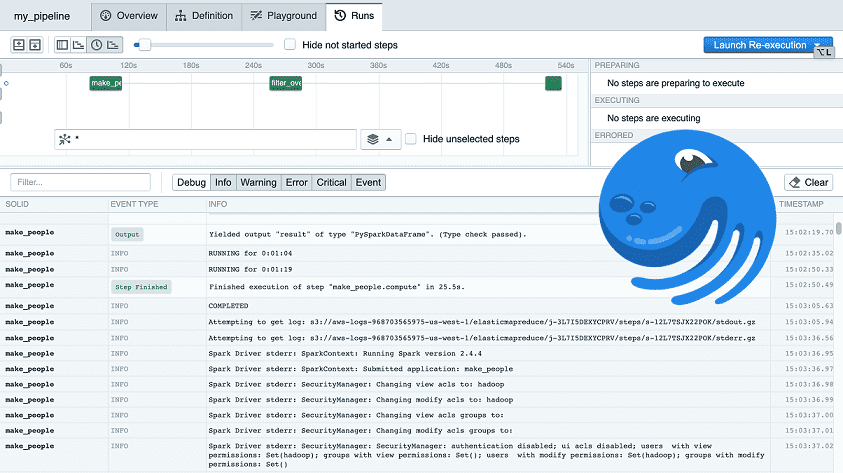
Разработка с использованием удаленного кластера позволяет запускать самые последние версии PySpark-кода следующим образом:
- во время запуска кластера можно отправить на узлы команду установки нужного набора пакетов. AWS EMR обрабатывает это с помощью действий начальной загрузки, а Databricks — с помощью библиотек. К примеру, пакеты dagster и dagster-pyspark понадобятся в Spark-кластере для выполнения там заданий Dagster PySpark. Но это не лучший вариант для развертывания нового кода для каждой Spark-задания с локального компьютера разработчика.
- можно отправить код в py-файлах через spark-submit. Это удобно при развертывании нового кода с локального компьютера, позволяя публиковать его для каждого запуска задания. Но требует предварительной подготовки: нужно упаковать код в zip-файл, поместить его в удаленное хранилище, например, AWS S3, а затем указать этот файл при отправке задания. Автоматизировать этот вариант можно с помощью ресурса пошагового запуска Emr_pyspark_step_launcher от Dagster, установив для параметра deploy_local_pipeline_package значение True в конфигурации. Параметр local_pipeline_package_path сообщает программе пошагового запуска, какой каталог нужно упаковать. Для регулярного запланированного задания рекомендуется заранее поместить код в хранилище S3, чтобы не тратить время на его упаковку при каждом запуске.
Таким образом, принципы тестирования и отладки Spark-конвейеров с Apache AirFlow, применимы и к фреймворку Dagster, однако здесь они реализуются быстрее и удобнее, повышая эффективность инженера данных и разработчика data pipelines.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Узнайте больше про практическую дата-инженерию и использование Apache AirFlow для разработки сложных конвейеров аналитики больших данных с Hadoop и Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

