
В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...

Сегодня рассмотрим основные преимущества ClickHouse – аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Читайте в нашей статье, чем еще хорош Кликхаус, кроме высокой скорости, и почему эту систему так любят аналитики, разработчики и администраторы Big Data. Чем хорош ClickHouse: главные преимущества Напомним, основным...

Продолжая разговор про успехи применения отечественных Big Data продуктов, сегодня мы рассмотрим пример использования Arenadata DB в одной из ведущих отечественных компаний розничного ритейла. Читайте в нашей статье про особенности внедрения распределенной отказоустойчивой MPP-СУБД для аналитики больших данных в Х5 Retail Group. Зачем ритейлеру еще одно Big Data решение: специфика...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...

Сегодня мы поговорим про продукты компании Arenadata – отечественного разработчика дистрибутива Apache Hadoop (ADH), массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB) и других Big Data платформ. Читайте в нашей статье, где внедрены эти решения и какую пользу они уже успели принести бизнесу. Облака и банк: 3...
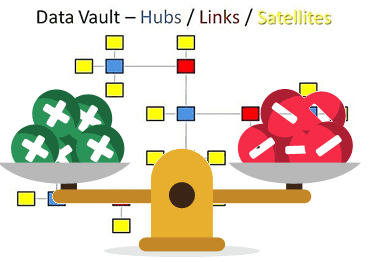
В этой статье мы рассмотрим основные плюсы и минусы Data Vault – популярного подхода к моделированию сущностей при проектировании корпоративных хранилищ данных (КХД). Читайте сегодня, почему промежуточные базы перед витринами данных упрощают ETL-процессы, за счет чего обеспечивается отсутствие избыточности и как много таблиц могут усложнить жизнь архитектора Big Data. Чем...
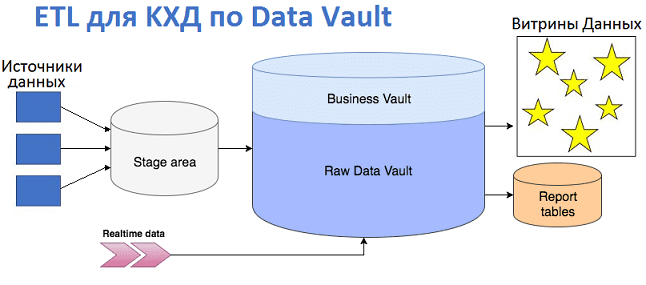
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....

В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...
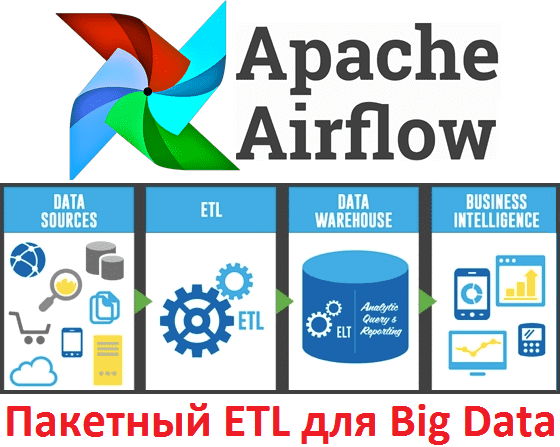
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...

Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для...

Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
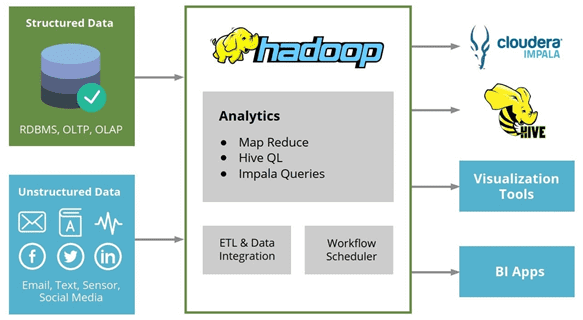
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...

Продолжая тему SQL-on-Hadoop, сегодня мы рассмотрим вопросы обеспечения информационной безопасности в Apache Hive и Cloudera Impala. Читайте в нашем материале, что такое RBAC, в чем специфика cybersecurity больших данных в экосистеме Hadoop и какие средства помогут защитить Big Data при работе с Hive и Impala. Что такое RBAC для SQL-on-Hadoop...

Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop. Что такое HiveQL,...

В прошлой статье мы рассмотрели основные возможности и ключевые характеристики Apache Hive и Cloudera Impala. Сегодня подробнее поговорим про то, что между ними общего и чем отличаются друг от друга эти SQL-инструменты для обработки больших данных (Big Data), хранящихся в кластере Hadoop. Что общего между Apache Hive и Cloudera Impala:...

Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга....
В последних версиях Apache HIVE пытается внедрить CBO (cost based optimizer) и оптимизация операций JOIN одна из главных его составляющих. Поэтому понимание сценариев оптимизации применения операций JOINs (объединений) является одним из ключевых факторов настройки производительности HiveQL. Рассмотрим каждый вид объединений на практических примерах и определим их различия: Shuffle Join (Common...