 637
637 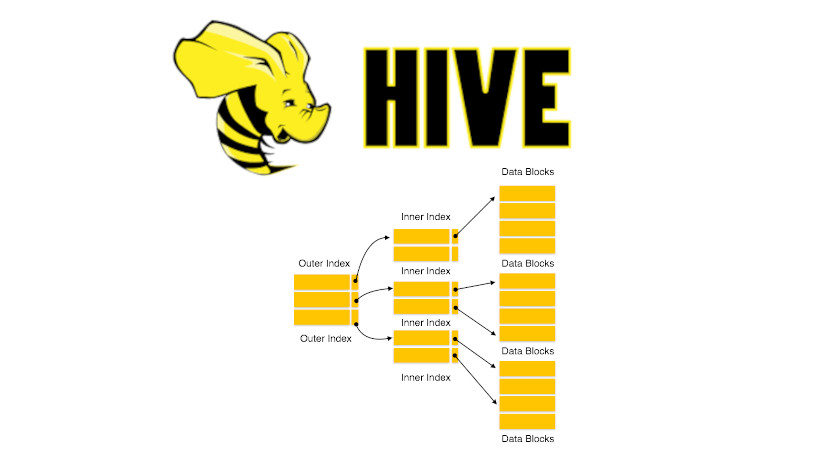
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive.
Какую роль играет использование индекса при обработке Big Data в Apache Hive
Индекс (index) – это объект базы данных, который отвечает за повышение производительности поиска данных в таблице базы данных (база данных может быть как реляционная, так и NoSQL). Hive обычно оперирует таблицами с большими массивами данных, которые хранятся в произвольном порядке, и их поиск по заданному критерию путем последовательного (строка за строкой) просмотра таблицы может занимать очень много времени. Для того, чтобы избежать долгих вычислений, формируется индекс из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы по поиску данных достигается за счет того, что индекс имеет структуру, оптимизированную под поиск (например, хеш или сбалансированное дерево) [1].
Особенности создания индекса при работе с Big Data в Hive: несколько практических примеров
Как уже говорилось выше, индекс создается по значениям конкретного столбца таблицы. Столбец выбирается исходя из поисковых запросов, которые планируются к выполнению. В качестве примера рассмотрим таблицу Employees, для которой далее будет создаваться индекс.
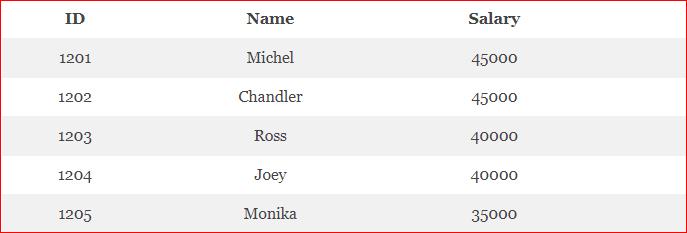
В качестве поля, по которому будет осуществляться поиск данных (в частности, сотрудников), можно взять Salary (зарплата). Для того, чтобы ускорить поиск по выбранному столбцу, необходимо создать индекс, добавив в него название данного столбца. За создание индекса в Hive отвечает команда CREATE INDEX. Следующий код на диалекте HiveQL отвечает за создание индекса в Hive-таблице по столбцу Salary [1]:
CREATE INDEX index_salary ON TABLE Employees(Salary) AS ‘org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler’;
Следует также отметить, что поиск будет выполняться быстрее только тогда, когда созданный индекс (а также столбец, по которому он был создан) используется при поиске, то есть для ускоренного поиска данных вышеприведенной таблицы необходимо задействовать созданный индекс путем добавления индексированного столбца в условие поиска:
SELECT * FROM Employees WHERE Salary>40000

Для удаления созданного индекса используется SQL-команда DROP INDEX. Следующий код отвечает за удаление созданного индекса:
DROP INDEX index_salary ON Employees;
Однако стоит учитывать, что индекс не только ускоряет поиск данных по таблице, но и значительно замедляет добавление или удаление новых данных, так при этих операциях перестраивается вся древовидная структура, которая была сформирована за счет создания индекса.
Таким образом, благодаря поддержки механизма индексов, Apache Hive позволяет значительно ускорить поиск Big Data и сэкономить на этом много времени. Это делает Apache Hive весьма удобным средством для работы с Big Data.
Больше подробностей про применение Apache Hive в проектах анализа больших данных вы узнаете на практических курсах по NoSQL в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
HIVE: Hadoop SQL администратор Hive
Источники
- https://data-flair.training/blog/hive-view-hive-index/

