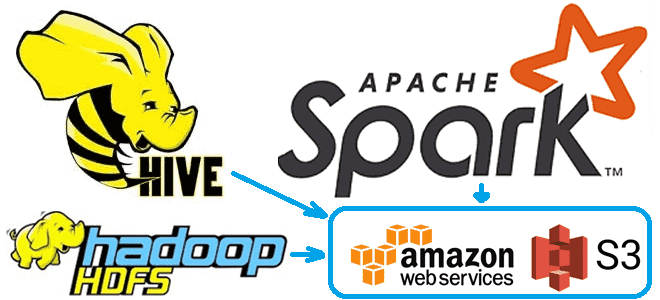
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive.
Еще раз о разнице между AWS S3 и Hadoop HDFS
При том, что облачное объектное хранилище AWS S3 сегодня стало практически стандартом де-факто для надежного хранения данных, оно не может полностью заменить распределенную файловую систему HDFS. В S3 данные хранятся в виде объектов в ресурсах, которые называются корзинами или бакетами (buckets), доступным через API или с помощью консоли Amazon. Хотя интеграция AWS с клиентом Hadoop представляет корзину S3 как файловую систему, bucket следует рассматривать как хранилище объектов, где операции с каталогами потенциально медленные и неатомарные. Также в корзине S3 поддерживаются не все файловые операции, например, отсутствует переименование, а данные не видны, пока не записан весь выходной поток.
Наконец, AWS S3 гарантирует согласованность в конечном счете (eventual consistency), когда объекты реплицируются между серверами для обеспечения доступности, но репликация изменения данных выполняется долго и может привести к несогласованности. Еще S3 не поддерживает разрешения файлов и каталогов HDFS, а также ACL-механизм для безопасного доступа к объектам по контрольным спискам (Access Control List).
Основы Hadoop
Код курса
INTR
Ближайшая дата курса
28 октября, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
За взаимодействие HDFS с AWS S3 используется коннектор S3A – клиента файловой системы, которая позволяет представить облачное объектное хранилище как файловую систему, чтобы обеспечить совместимость с распределенной файловой системой Хадуп. Файловая система S3A включает классы для интеграции с протоколами фиксации заданий Hadoop и Spark с механизмом многокомпонентной загрузки (MultiPart Upload, MPU) файлов в S3. Это позволяет клиенту записывать данные в нескольких POST-запросах по HTTP и автоматически используется при записи больших объемов данных в S3. Подробнее об этом мы рассказывали здесь.
Однако, для взаимодействия Hadoop c S3 одного S3A-коннектора недостаточно. Рассмотрим пример, когда заданию MapReduce, Spark или Hive необходимо получить данные из AWS S3.
Код курса
NOSQL
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Обращение к данных в AWS S3 из экосистемы Hadoop
Если заданию MapReduce, Spark или Hive нужно получить данные из AWS S3, необходимы следующие компоненты:
- идентификатор ключа доступа к AWS;
- ключ доступа к AWS Secret;
- URI-адрес папки с файлами данных, который должен начинаться с s3a, поскольку предыдущие версии коннекторов s3 и s3n устарели и не поддерживаются в последнем релизе Apache Hadoop;
- jar-файл hadoop-aws с реализацией коннектора S3A, версия которого должна совпадать с версией Хадуп;
- jar-файл aws-java-sdk-bundle, который зависит от jar-файла hadoop-aws и тоже должен быть подходящей версии.
Чтобы получить из Hadoop доступ к данным в корзине S3, необходимо изменить конфигурации на каждом узле и перезапустить компоненты кластера:
- HDFS с узла имен (NameNode);
- YARN с узла диспетчера ресурсов;
- хранилище метаданных Hive (Metastore);
- сам Hive как инструмент SQL-on-Hadoop;
- Livy как RESTful-интерфейс доступа к Spark.
Разберем несколько важных конфигураций в xml-файлах.
Файл core-site.xml сообщает демону Hadoop, где в кластере выполняется NameNode. Он содержит параметры конфигурации для Hadoop Core: свойства ввода-вывода, общие для HDFS и MapReduce. Здесь следует задать идентификатор ключа доступа к AWS и ключ доступа к AWS Secret:
<property>
<name>fs.s3a.access.key</name>
<value>AWS_ACCESS_KEY_ID</value>
</property><property>
<name>fs.s3a.secret.key</name
<value>AWS_ACCESS_SECRET_KEY</value>
</property><property>
<name>fs.s3a.impl</name
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
Файл hdfs-site.xml содержит параметры конфигурации для демонов HDFS, основного и вторичного узла имен, а также узлов данных (DataNodes). В файле hdfs-site.xml можно указать репликацию блока по умолчанию и проверку разрешений в HDFS, а также фактическое количество репликаций. Для интеграции Hadoop с AWS S3 в этом файле также задается идентификатор ключа доступа к AWS и ключ доступа к AWS Secret:
<property>
<name>fs.s3a.access.key</name>
<value>AWS_ACCESS_KEY_ID</value>
</property><property>
<name>fs.s3a.secret.key</name>
<value>AWS_ACCESS_SECRET_KEY</value>
</property>
Файл mapred-site.xml содержит параметры конфигурации для демонов MapReduce, трекеры заданий и задач. Для обращения к AWS S3 из Hadoop в этом файле указывается реализация коннектора S3A:
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
Файл hive-site.xml используется для установки значений всей конфигурации Hive. Для обращения к S3 из Hive здесь также указывается идентификатор ключа доступа к AWS и ключ доступа к AWS Secret:
<property>
<name>fs.s3a.access.key</name>
<value>AWS_ACCESS_KEY_ID</value>
</property><property>
<name>fs.s3a.secret.key</name>
<value>AWS_ACCESS_SECRET_KEY</value>
</property>
Код курса
HIVE
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Проверить, что все работает верно, т.е. можно ли получить доступ к папке S3 и файлам из HDFS, помогут простые тестовые задания. Например, можно получить список всех файлов в папке S3 и посмотреть их содержимое. Для работы с Hive следует сперва создать внешнюю таблицу, которая будет указывать на папку S3 в качестве местоположения данных. Далее можно посмотреть строки в таблице и посчитать их. А удостовериться, что Spark работает корректно, поможет простое задание, которое считывает данные из папки S3 и выполняет несложные преобразования, например, перевод CSV-файлов в датафрейм. Также можно считать внешнюю таблицу Hive, указывающую на папку в S3, и перевести данные в датафрейм. Однако, если в Hive включен защищенный протокол Kerberos, могут потребоваться дополнительные настройки для реализации подобного теста.
В заключение отметим, что Hadoop также имеет встроенный jar-файл для объектного хранилища Azure, т.е. подобную последовательность действий можно выполнить не только для AWS S3. О том, почему не все бывает гладко при передаче данных в AWS S3 с помощью Apache Spark, читайте в нашей новой статье.
Узнайте больше про практическое применение Apache Hive для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
- Администрирование кластера Hadoop
- Основы Hadoop
- Hadoop для инженеров данных
Источники