 440
440 
Содержание
В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL.
Еще раз про партиционирование: разделы в Apache Spark и Hive
Партиционирование или разбиение данных на разделы в Apache Spark обеспечивает параллельную обработку данных. В популярном инструменте SQL-on-Hadoop, Apache Hive, который позволяет обращаться к данным, хранящимся в Hadoop HDFS через SQL-запросы, концепция разделения также используется. Ее реализация в Hive достаточно проста: следует определить один или несколько столбцов для разделения данных, а затем фреймворк для каждой уникальной комбинации значений в этих столбцах создает подкаталог для хранения соответствующих данных. Результат похож на эффект индексации – простого способа найти строки с определенной комбинацией значений. Также здесь появляются дополнительные преимущества размещения данных в одном файле для ускорения доступа к ним. В Apache Spark партиционирование обеспечивает простой и эффективный способ распределения данных по рабочим узлам, поскольку разделы уже образуют логические группы. Это сокращает объем данных, которые придется перемешивать между worker’ами, и повышает производительность.
Однако, эффективность партиционирования во многом зависит от того, как будут использоваться столбцы разделения. В частности, рекомендуется разделять данные по столбцам, которые регулярно участвуют в операциях группировки. Иначе партиционирование не имеет особого смысла и даже может снизить производительность, поскольку Spark придется перемешивать больше данных.
Также партиционирование наиболее эффективно, когда количество строк в каждом разделе примерно одинаково. При сильном перекосе разделов у одних worker’ов будет гораздо больше данных для обработки, чем у других, что приведет к неэффективному использованию ресурсов кластера.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
1 декабря, 2025
Продолжительность
32 ак.часов
Стоимость обучения
96 000
Бакетирование или разделение с хешированием
Другим популярным методом оптимизации производительности задач последовательного чтения данных в Apache Spark и Hive является бакетирование (bucketing). Это тоже способ разделения данных, похожий на партиционирование, но с некоторыми важными отличиями. Бакетирование также ускоряет выполнение SQL-запросов, исключая рандомизацию при JOIN-соединениях и агрегациях за счет хранения данных в одних сегментах или столбцах кластеризации, которые называются бакеты (bucket). Apache Spark выполняет бакетирование таблиц в стиле Hive, разбивая разделы на фиксированное количество бакетов в соответствии с хеш-функцией по некоторому набору столбцов. При совместном использовании партиционирования и бакетирования каждый раздел будет разделен на равное количество бакетов. Hive гарантирует, что все строки с одинаковым хешем попадут в один и тот же бакет, который может содержать несколько таких групп. Поскольку количество бакетов фиксировано для каждого раздела, наличие большого количества различных значений в столбцах бакетирования не становится проблемой, в отличие от партиционирования.
Таким образом, бакетирование приводит к более равномерному распределению данных, при этом связанные данные, определяемые хэш-функцией, будут размещаться в одном сегменте, сохраняя выигрыш в производительности. В случае бакетирования перекос в данных по-прежнему является проблемой, которую можно смягчить, уменьшив количество бакетов. Например, если половина данных имеет один и тот же хэш, можно использовать всего 2 бакета: один для самого распространенного значения и один для всего остального. Как это работает на практике, рассмотрим далее, а пример того, как партиционирование используется в реальных кейсах читайте в нашей новой статье.
Бакетирование vs партиционирование: сравнение эффективности
Чтобы понять, какой именно практический прирост производительности дают методы партиционирования и бакетирования, разберем небольшой практический пример по обработке набора данных обзора книжных новинок. Создадим 3 варианта этого датасета, зарегистрировав их в хранилище метаданных Hive:
- первый вариант – простая таблица;
- второй вариант – партиционирован по столбцу рейтинга — PARTITIONED BY (star_rating STRING);
- 3-ий вариант – дополнительно к партиционированию добавлено бакетирование по дате рецензирования:
PARTITIONED BY (star_rating STRING) CLUSTERED BY (review_date) INTO 100 BUCKETS
В качестве средства проверки напишем небольшое задание Spark, которое будет выполнять агрегированные вычисления путем группировки по рейтингу и дате рецензирования для каждой из трех таблиц:
df.groupBy("star_rating","review_date")
.avg("product_parent")
.collect()
Протестировав этот код с 3-мя версиями одного набора данных, можно заметить явный выигрыш в производительности, который дают методы партиционирования и бакетирования. Без применения этих методов разделения данных их обработка заняла 37 секунд. С партиционированием по рейтингу – на 7 секунд меньше. А партиционирование + бакетирование сократило время обработки до 8 секунд.
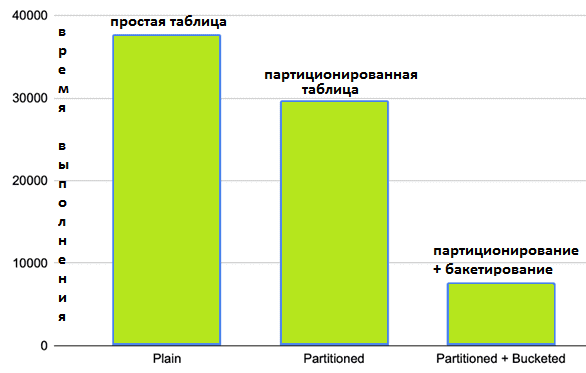
Таким образом, оптимизация способа хранения данных для этого конкретного запроса сократила время вычислений почти на 80%. Разумеется, это тест для конкретного набора данных и сценария их обработки. Однако, результаты подтверждают эффективность разделения в зависимости от обстоятельств. Например, если в столбце будет относительно небольшое количество различных значений, которые будут часто использоваться в фильтрах при примерно одинаковом количестве строк для каждого значения, партиционирование будет отличным вариантом. Если есть много различных значений, которые могут распределены не равномерно, подойдет бакетирование таблиц. Подробнее про особенности бакетирования в Apache Spark и Hive мы рассказывали здесь, здесь и здесь.
В заключение отметим, что механизмы бакетирования в Spark SQL и в Apache Hive немного отличаются друг от друга, что может стать существенным ограничением. В частности, бакетирование в Spark SQL требует сортировки по времени чтения, снижая производительность выполнения запроса. Когда Spark записывает данные в бакетированную таблицу, он может генерировать множество небольших файлов, которые не эффективно обрабатываются HDFS. Поэтому в 2020 году в Apache Spark были добавлены некоторые оптимизации, чтобы сделать бакетирование применимым к большему количеству сценариев, а также упростить миграцию с Hive на Spark SQL. Читайте в нашей новой статье про реализацию ACID-транзакций в Apache Hive.
Освойте все тонкости практического использования Apache Hive и Spark для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark

