
Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
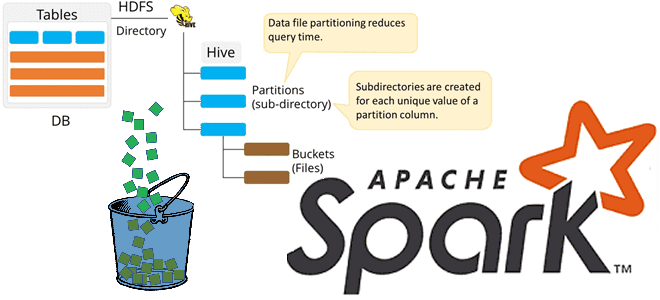
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...

Сегодня поговорим про бакетирование таблиц в Apache Spark для оптимизации производительности заданий и снижения затрат на кластер при их выполнении. Читайте далее, что такое Bucketing в Spark SQL и как это предотвращает операции перетасовки в приложениях аналитики больших данных. Что такое Bucketing и зачем это нужно в Big Data Бакетирование...

Сегодня в качестве пятничного развлечения для дата-инженеров, разработчиков распределенных приложений, администраторов, аналитиков и других специалистов по большим данным мы приготовили небольшой квиз по Apache Hadoop. Проверьте свое знание главной технологии Big Data, решив кроссворд, филворд и небольшой тест по основным компонентам и главным принципам работы этой платформы хранения и аналитики...

В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data. Еще раз об OLAP: схема звезды...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...

В прошлый раз мы говорили про виды таблиц для быстрой работы с Big Data в Apache Hive. Сегодня поговорим про создание пользовательских функций и их применение в Hive. Читайте далее про особенности создания и применения UDF для работы с Big Data в распределенной платформе Apache Hive. Что такое пользовательские функции...

Чтобы самостоятельное обучение по Хайв стало еще интереснее, сегодня мы предлагаем вам простой тест по основам архитектуры распределенной SQL-платформы Apache Hive, включая элементы, из которых она состоит и их структуру. Тест по основам архитектуры Hive для новичков Для начинающих самостоятельное обучение по Apache Hive мы предлагаем простой интерактивный тест...
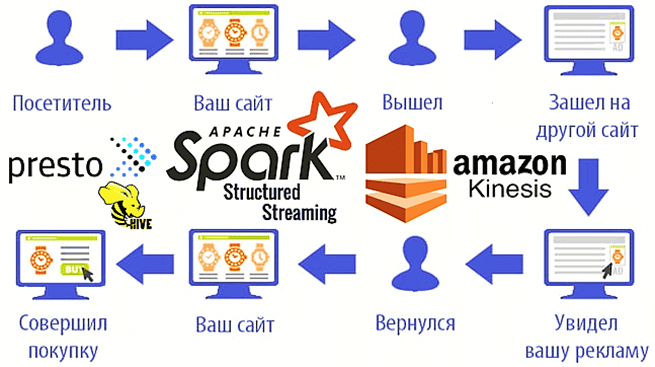
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

В прошлой статье мы рассматривали архитектуру Apache Hive и ее основные элементы. Сегодня поговорим про основные виды таблиц в Hive. Также подробно рассмотрим создание этих таблиц на практических примерах. Читайте далее про виды таблиц в Hive и их особенности. 2 основных вида таблиц для быстрой работы с большими данными в...

В этой статье мы поговорим про структуру системы управления базами данных (СУБД) Apache Hive. Также рассмотрим, какие базовые компоненты входят в структуру известной SQL-подобной СУБД, входящей в экосистему Hadoop. Читайте далее про основные компоненты структуры Apache Hive, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки больших...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Сегодня поговорим про особенности перехода с локального Hadoop-кластера в облачное SaaS-решение от Google – платформу Dataproc. Читайте далее, какие 5 шагов нужно сделать, чтобы быстро развернуть и эффективно использовать облачную инфраструктуру для запуска заданий Apache Hadoop и Spark в системах хранения и обработки больших данных (Big Data). Шаги переноса Data...

В этой статье рассмотрим архитектуру и принципы работы системы хранения, аналитической обработки и визуализации больших данных на базе компонентов Hadoop, таких как Apache Spark, Hive, Tez, Ranger и Knox, развернутых в облачном Google-сервисе Dataproc. Читайте далее, как подключить к этим Big Data фреймворкам BI-инструменты Tableau и Looker, а также что обеспечивает...

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache...

В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data). Apache Kudu в...

Сегодня поговорим про еще один open-source проект от Apache Software Foundation – Bigtop, который позволяет собрать и протестировать собственный дистрибутив Hadoop или другого Big Data фреймворка, например, Greenplum. Читайте в нашей статье, что такое Apache Bigtop, как работает этот инструмент, какие компоненты он включает и где используется на практике. Что...