В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов.
Еще раз про транзакции в Apache Hive
Напомним, ACID – это акроним четырех ключевых свойств транзакции:
- Атомарность (Atomicity) – однозначность полностью успешного либо полностью неуспешного завершения;
- Согласованность (Consistency) – результаты выполнения каждой транзакции видны каждому следующему запросу;
- Изоляция (Isolation) – выполняется любой транзакции не вызывает неожиданных побочных эффектов для других пользователей, т.е. все транзакции отделены друг от друга;
- Долговечность (Durability) – завершенная транзакция будет сохранена даже в случае сбоя отдельного узла или всей системы.
До Hive версии 0.13 атомарность, согласованность и долговечность поддерживались на уровне раздела, а изоляция использовалась для механизма блокировки отдельных операций, но отсутствовала для транзакций в целом. С версии 0.13, все функции ACID стали полностью поддерживаться. ACID-транзакции в Apache Hive требуются в следующих сценариях:
- запись потоковых данных, когда в одном разделе Hive каждые несколько секунд создается множество небольших файлов, что снижает производительность. ACID позволяет вставлять, обновлять или удалять один и тот же раздел, не влияя на производительность таблицы.
- корректировка данных в озере на Hadoop HDFS, когда нужно исправить их операций вставки, обновления или удаления;
- массовые обновления с использованием SQL-оператора слияния (merge), когда можно объединить небольшие файлы в один, не влияя на производительность чтения.
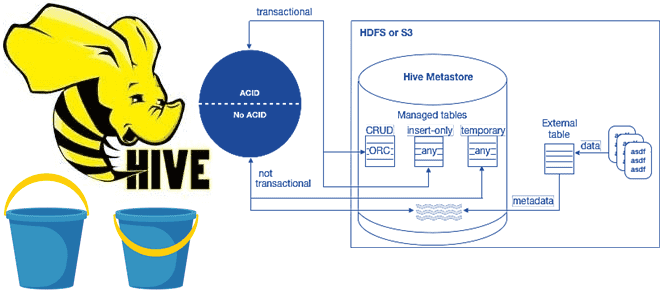
Изначально HDFS не поддерживает изменения в существующих файлах и не обеспечивает согласованность чтения, если операция записи добавляет данные в файл, уже читаемый другим пользователем. Для поддержки ACID-функций Hive хранит табличные данные в наборе базовых файлов, а все данные операций вставки, обновления и удаления – в дельта-файлах. Во время чтения происходит слияние базовых и дельта-файлов, чтобы представить самые свежие данные, например:
/user/hive/warehouse/acid_db.db/employee/base_0000022/bucket_00000
/user/hive/warehouse/acid_db.db/employee/delta_0000023_0000023_0000/bucket_00000
Под капотом ACID-транзакций
Диспетчер блокировок DbLockManager, представленный в Hive 0.13, хранит всю информацию о транзакциях и связанных блокировках в хранилище метаданных (Metastore). Менеджер блокировок DummyTxnManager управляет всеми блокировками в хранилище метаданных. Контрольные сигналы регулярно отправляются держателями блокировок и инициаторами транзакций в хранилище метаданных Hive для предотвращения устаревших блокировок и транзакций. Если хранилище метаданных не получает контрольный сигнал в течение времени, указанного в свойстве конфигурации hive.txn.timeout, блокировка или транзакция прерываются, а DbTxnManager получит блокировки для всех таблиц, даже для тех, у которых нет свойства transactional=true. По умолчанию операция Insert в нетранзакционной таблице получает исключительную блокировку и, блокируя другие операции вставки и чтения.
DbLockManager отвечает за управление блокировками базы данных, таблицы и раздела. Он описывается свойством hive.lock.manager, значение которого по умолчанию равно hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager. Это означает, что администраторы Hive использует сервис синхронизации метаданных ZooKeeper или диспетчеры блокировки в памяти. Чтобы просмотреть информацию о блокировках, связанных с транзакциями, администратор использует DDL-команду SHOW LOCKS, которая возвращает следующие выходные данные для каждой блокировки:
- имя базы данных (Database name);
- имя таблицы (Table name);
- раздел (Partition) для партиционированной таблицы;
- состояние блокировки (Lock state) – Получено (Acquired), когда инициатор транзакции удерживает блокировку, Ожидание (Waiting), когда инициатор транзакции ожидает блокировки или Прервано (Aborted), когда время блокировки истекло, но еще не очищено;
- тип блокировки (Lock type) – Эксклюзивная (Exclusive), когда блокировка не может быть разделена, Совместное чтение (Shared_read), когда блокировка может использоваться совместно с любым количеством других блокировок Shared_read или Совместная запись (Shared_write), когда блокировка может совместно использоваться любым количеством других блокировок Shared_read, но не с другими блокировками Shared_write;
- идентификатор транзакции (Transaction ID), связанный с блокировкой, если она существует;
- последнее время контрольного сигнала от заблокированного компонента;
- время получения блокировки;
- пользователь Hive, который запросил блокировку;
- хост-компьютер, где пользователь запустил клиент Hive.
Конфигурационные параметры DbLockManager показаны на рисунке.

В таблице транзакций ACID для каждой транзакции создается свой дельта-каталог. При этом у ACID-транзакций в Hive есть некоторые ограничения, что мы и рассмотрим далее.
Ограничения и проблемы уплотнения
- не поддерживаются команды BEGIN, COMMIT, ROLLBACK, а все транзакции автоматически фиксируются в Hive ACID;
- поддерживается только формат файла ORC;
- таблицы должны быть управляемы и бакетированы, ACID не поддерживается для внешних таблиц, т.е. изменения во внешних таблицах не учитываются;
- менеджер транзакций Hive должен быть установлен на apache.hadoop.hive.ql.lockmgr.DbTxnManager для работы с таблицами ACID, когда сеансы без ACID, например, Spark не могут получить доступ к этим транзакционным таблицам;
- оператор «LOAD DATA» не поддерживается в транзакционных таблицах, так как он работает на уровне файлов.
Как мы уже отметили выше, Apache Hive для каждой ACID-транзакции создается свой дельта-каталог в таблице ACID-транзакций. Со временем там появляется множество дельта-каталогов, в которых хранятся данные для каждой транзакции. Эти каталоги и небольшие файлы снижают производительность чтения, так как при этом все базовые и дельта-каталоги сливаются при любых обновлениях и удалениях. Hive реализует такое слияние дельта-каталогов с помощью процесса уплотнения, который бывает 2-х видов:
- незначительное (Minor) – объединяет набор существующих дельта-файлов в один дельта-файл для каждого сегмента и не удаляет удаленные записи/данные;
- базовое (Major) – объединяет несколько дельта-файлов и базовый файл для сегмента в новый базовый файл для каждого сегмента. Это более дорогостоящий процесс по сравнению с Minor-уплотнением, поэтому следует выполнять его осторожно и только при необходимости, т.к. оно удаляет удаленные записи и данные.
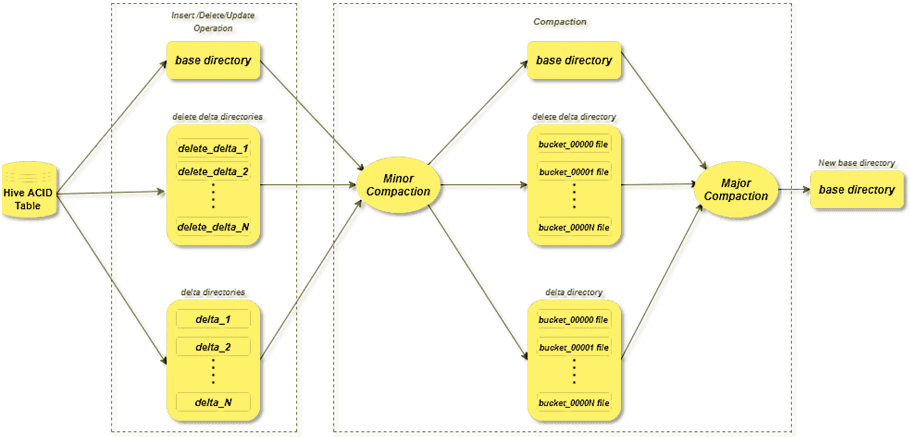
Настраивать уплотнение рекомендуется с учетом частоты, с которой выполняются транзакции в ACID-таблице и частоты, с которой в ней создаются небольшие файлы в результате этих транзакций. А почему много небольших файлов становятся проблемой в Apache Hive и других технологиях на базе HDFS, читайте в нашей новой статье.
Узнайте больше про практическое применение Apache Hive для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: