 1024
1024 
Содержание
Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf.
Постановка задачи: аналитика пользовательского поведения в Udemy и проблемы текущего решения
Образовательной платформой Udemy пользуются более 44 миллионов студентов по всему миру. Компания анализирует данные о событиях, генерируемые действиями пользователей (клики, просмотры страниц и показы) для следующих бизнес-задач:
- формирование персональных рекомендаций;
- подсчет рейтинга результатов поиска;
- A/B тестирование;
- атрибуция маркетинговых и платежных каналов;
- сбор статистики.
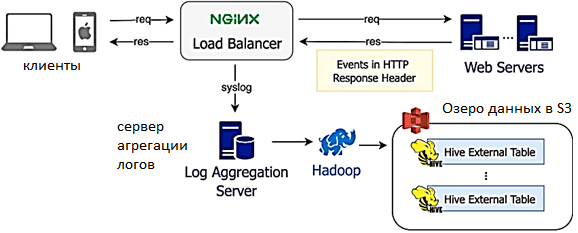
Раньше Udemy для этого использовала legacy-систему сбора данных, где каждая строка лога включала фиксированный набор полей для каждого события и небольшую информацию с дополнительными подробностями о конкретном событии. Анализ логов выполнялся один раз в день, а результаты загружались в AWS S3 для запроса через Apache Hive. Хотя практика такого синтаксического парсинга довольно распространена, для этого способа анализа характерны следующие проблемы:
- низкая масштабируемость сервера агрегирования логов;
- высокая задержка – данные анализируются в пакетном режиме раз в день, а не в реальном времени;
- отсутствие настраиваемых структур событий, т.к. одни и те же поля используются в нескольких приложениях, их значение может варьироваться в зависимости от контекста, создавая путаницу для последующих потребителей данных;
- низкое качество данных из-за отсутствия механизма проверки событий в реальном времени. Недопустимые события обнаруживаются только при отказе следующих потребителей и/или получения некорректных результатов.
- отсутствие специфической документации для отдельных кейсов из-за общей структуры событий.
Чтобы решить эти и другие проблемы имеющейся системы, было решено перестроить ее с учетом новых требований, ключевыми из которых стали следующие:
- поддержка всех приложений Udemy (веб-сайты, а также мобильные приложения на iOS и Android), обеспечивая возможности отслеживания событий на стороне клиента и на стороне сервера;
- соблюдение схем данных и предотвращение сбора некорректных данных;
- отсутствие негативного влияния на производительность веб-сайта;
- обработка собранных событий в реальном времени и в пакетном режиме.
Как эти требования были реализованы, мы рассмотрим далее.
Архитектура новой системы и преимущества AVRO-сериализации
Определив требования к решению, аналитики выбирают между 2-мя вариантами их реализации: использовать готовый продукт с нужными функциональными возможностями или разрабатывать новый. Чтобы ответить на этот вопрос, сотрудники Udemy запустили пилотный проект оценки существующих решений с открытым исходным кодом и коммерческих SaaS-альтернатив. Проверочное тестирование показало, что ни одна из готовых систем не обеспечивала всех требований в части качества данных, особенно безопасную эволюцию схемы. А поскольку компания рассматривает сбор высококачественных данных как стратегическую инициативу, в итоге было решено приступить к созданию собственного продукта, который будет отвечать всем функциональным и нефункциональным требованиям.
При этом одним из главных аспектов стал выбор технологии сериализации данных. На первый взгляд, проще всего использовать JSON во всей системе. Но так данные будут храниться в виде необработанного текста, что приведет к неэффективному использованию дискового пространства и множеству парсеров. Поэтому дата-инженеры Udemy стали выбирать между Apache AVRO и Google Protobuf, которые поддерживают:
- двоичное кодирование в соответствии со схемой данных, что более эффективно по сравнению с текстовым форматом;
- автоматическая проверка структуры данных на соответствие схеме;
- эволюция схемы, когда данные изменяются по мере бизнес-потребностей, а в их структуру добавляются новые или удаляются существующие поля.
Несмотря на сходства между Apache AVRO и Google Protobuf, эти технологии сериализации данных имеют ряд важных отличий:
- концепция обязательных и необязательных полей – в Protobuf v3 каждое поле необязательно, а в AVRO можно указать, какие поля должны быть заполнены всегда;
- интеграция с внешними системами — AVRO изначально интегрирован с Apache Hive и Presto, которые используются в Udemy;
- мультиязычность – Protobuf изначально поддерживает генерацию кода на многих языках программирования, а AVRO – только для Java;
- схема на чтение и запись — для чтения данных AVRO требуется, чтобы схема записи присутствовала вместе со схемой чтения;
- эволюция схемы – в AVRO при изменении схем нужен их реестр, чтобы ссылаться на необходимую версию схемы без сохранения ее вместе с данными.
Поскольку AVRO больше подходил для экосистемы данных Udemy, компания выбрала именно этот формат со строгими правилами совместимости схем и поддержкой JSON, чтобы использовать его для клиентов внешнего интерфейса при двоичной сериализации внутренних событий. В качестве реестра схем используется компонент платформы Kafka Confluent – Schema Registry, о котором мы писали здесь.
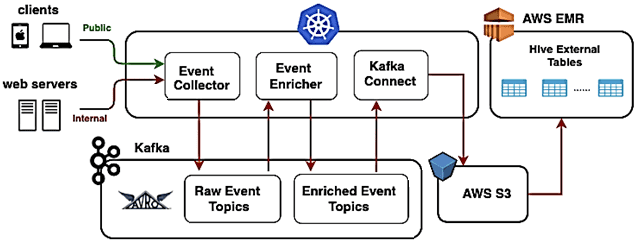
Клиенты Udemy и внутренние веб-серверы включают трекеры, с помощью которых они отправляют события в сервис «Обогащение событий» (Event Enricher). События из JSON-формата сериализуются в AVRO согласно схемам из реестра. Затем эти данные записываются в топики необработанных или «сырых» событий (raw-event) в Apache Kafka.
Event Enricher читает необработанные события, «обогащает» их и записывает в окончательные топики событий Kafka для дальнейшей потоковой обработки. Чтобы включить запросы или пакетную обработку в Apache Hive, коннектор Kafka S3 считывает события из Kafka и выгружает их в озеро данных на AWS S3. Все компоненты развернуты в Kubernetes, а за работой системы ведется тщательный мониторинг, включая отслеживание аномалий и пороговых значений с генерацией предупреждений в случае чрезвычайной ситуации.
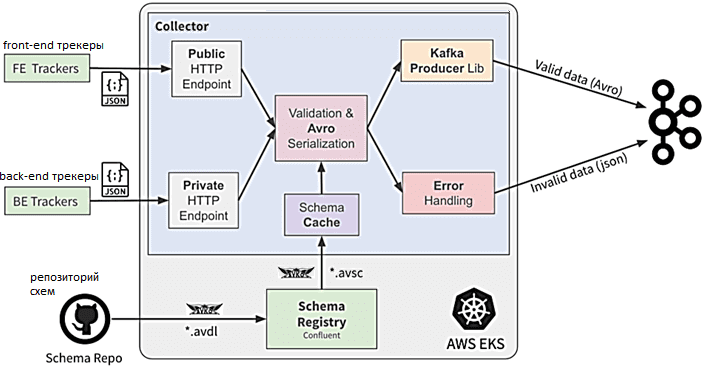
AVRO-сериализация в этом проекте – это не только способ повысить качество данных через отклонение недопустимых событий, но и средство коммуникации – контракт между производителями событий и группами их потребителей. Когда требуется новое событие, перед его созданием продюсер должен сперва создать схему события и зарегистрировать ее в реестре схем, а лишь потом генерировать данные по этой структуре. Для этого поверх формата Avro IDL, который упрощает редактирование и просмотр для разработчиков, преобразуясь в формат схемы AVRO во время регистрации, специалисты Udemy создали ряд дополнительных функций.
В частности, для десериализации AVRO нужна точная версия схемы, которая использовалась при сериализации. Хотя можно встраивать схему в каждое сообщение, записанное в Kafka, это очень неэффективно, т.к. схемы обычно больше, чем события. Реестр схем Confluent сопоставляет каждую схему с уникальным идентификатором, поэтому вместо включения всей схемы в сообщение Kafka, можно было включить только идентификатор схемы. Поскольку к реестру схемы будут обращаться любые сервисы записи событий в Kafka, он должен быть всегда доступен, а потому развертывается на нескольких экземплярах. Также Schema Registry отвечает за проверку совместимости для всех схем событий, гарантируя, что никакие изменения в существующих схемах не нарушат работу существующих продюсеров и потребителей сообщений. Эта конфигурация совместимости настраивается для каждого типа события.
Сборщик событий предоставляет простую конечную точку для публикации событий в системе: клиенты отправляют данные о событиях в формате JSON, а Event Collector сериализует их в AVRO и публикует в Kafka. Это масштабируемый и высокодоступный микросервис, развернутый в Kubernetes, написан на языке Kotlin с помощью SpringBoot. Кроме конвертации из JSON в AVRO и проверки соответствия структуры события схеме при сериализации, сборщик отправляет события в Kafka с помощью KafkaProducer. Также этот сервис обогащает события данными, содержащимися в запросе, например, метка времени, и отправляет недопустимые события в отдельный топик Kafka для сообщений с некорректной структурой, чтобы обработать их позже. Наконец, Event Collector выполняет мониторинг и логирование: выдает метрики для сбора общей статистики, а также создает логи о недопустимых событиях.
Kafka является ядром системы, выполняя роль основной системы хранения данных, с которой взаимодействует каждый продюсер и потребитель сообщений. Как только событие попадает в Kafka после Event Collector, данные сохраняются на диске и обрабатываются как минимум один раз. В Udemy кластер Kafka 2.1.1 включает 5 брокеров с пропускной способностью записи 50 тысяч сообщений в секунду, и в 2 раза больше на чтение. У каждого типа событий есть свой топик Kafka, чтобы обеспечить изоляцию. Каждый топик имеет коэффициент репликации 3 и количество разделов 3. Одно сообщение Kafka содержит событие в кодировке AVRO, занимая в среднем 500 байт. Срок хранения настроен на 4 дня. По умолчанию в кластере Kafka компания Udemy использует семантику не строго однократной доставки сообщений (acks=all), а at-least-once (acks=1), принимая риск потери события в сценарии переключения при отказе лидера, чтобы повысить производительность записи.
Помимо Amazon S3 для озера данных, Udemy также использует Amazon EMR для управления кластерами Apache Hive, Spark и Presto, чтобы работать с событиями в S3. Каждый раз, когда схема AVRO развертывается в production с помощью диспетчера схем событий, в хранилище метаданных Hive автоматически создается соответствующая внешняя таблица.
Дальнейшие потребители Apache Superset, Hive, Presto и Spark используют разделы Hive (год, месяц, день, час) для эффективного запроса данных о событиях из Amazon S3. Поэтому эти разделы есть во внешних таблицах Hive в соответствии с путями AWS S3. Чтобы создавать разделы без задержек, разработчики Udemy реализовали собственный Hive Partitioner – микросервис, который создает разделы на внешних таблицах Hive почти в реальном времени с помощью уведомлений о событиях S3. Подробнее о том, что такое партиционирование в Apache Hive и чем оно отличается от бакетирования, читайте в этой статье.
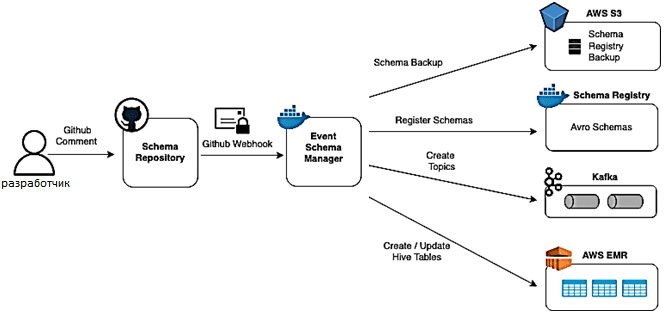
Средством хранения схем данных IDL Avro выступает репозиторий GitHub. Когда запускается pull-запрос для создания новой схемы или изменения существующей, диспетчер схемы событий выполняет следующие операции:
- загрузка резервной копии реестра схемы в корзину S3;
- преобразование формата схемы Avro IDL в фактический формат схемы AVRO (avsc);
- проверка совместимости схемы с использованием реестра;
- регистрация схем в реестре;
- создание топиков Kafka для новых событий;
- создание или обновление внешних таблиц Hive.
Таким образом, разработанная система помогла компании онлайн-образования включить продюсера и потребителей в жизненный цикл данных, предоставив им общий контракт и возможность отслеживать состояние собранных данных. Описанная система аналитики больших данных работает в production больше года, обеспечивая доступ к информации с задержкой менее секунды для более 20 команд и 250+ типов событий.
Узнайте больше про практическое применение Apache Hive и Kafka для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
- Apache Kafka для разработчиков
- Администрирование кластера Kafka
Источники

