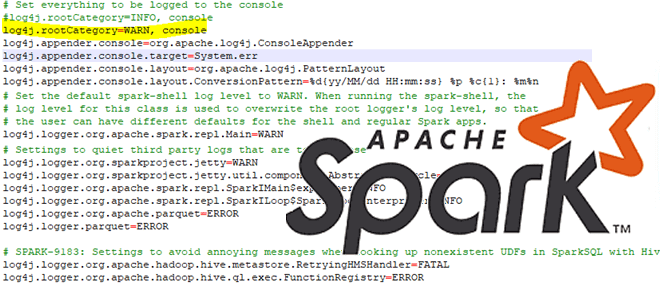
Сегодня рассмотрим особенности отладки PySpark-приложений: как Python-код исполняется в JVM, какие сложности возникают у разработчика при тестировании и исправлении ошибок в программе, написанной локально и запускаемой в кластере, а также как настроить вывод событий в лог-файл. Запуск и выполнение PySpark-кода Хотя Apache Spark и имеет Python API, позволяя писать код...

Что такое потоковое обогащение данных, зачем это нужно и как оно реализуется в Apache Flink. Проблемы и решения предварительной загрузки справочных данных в память, синхронного и асинхронного поиска в источнике по каждой записи и организация потоковой передачи событий. 3 способа загрузить эталонные (справочные) данных в Apache Flink для обогащения потока...
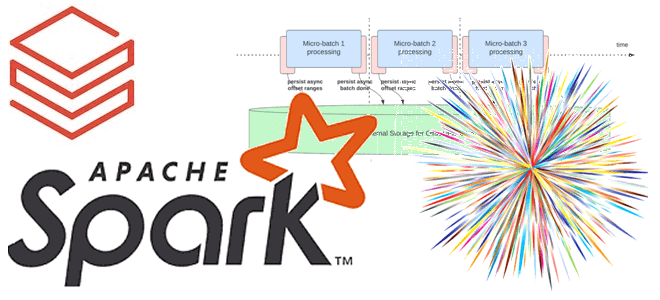
В прошлом году Databricks выпустили новый проект для ускорения потоковой передачи в Apache Spark. Сегодня рассмотрим, как именно Lightspeed сокращает задержку в операционных рабочих нагрузках Structured Streaming с помощью асинхронного управления смещением. Операционные рабочие нагрузки и что их тормозит в Apache Spark Structured Streaming Рабочие нагрузки потоковой передачи можно разделить...
Чем базы данных временных рядов отличаются от реляционных и key-value хранилищ, какова модель данных для хранения метрик, значения которых меняются во времени, какие решения этой категории NoSQL-СУБД сегодня популярны на рынке и для чего они используются. Что такое база данных временных рядов и где она используется Как и следует из...

Сегодня рассмотрим, какие системные метрики Greenplum необходимо отслеживать администратору кластера и дата-инженеру для оценки работоспособности и эффективности этой СУБД, а также с помощью каких инструментов это сделать. Мониторинг средствами Greenplum Прежде всего, стоит отметить, что контролировать Greenplum можно с помощью различных инструментов, включенных в систему или доступных в качестве надстроек....
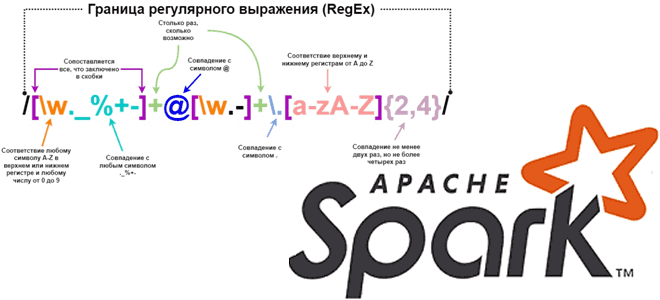
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения. Как работает функция regexp_replace() Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например,...
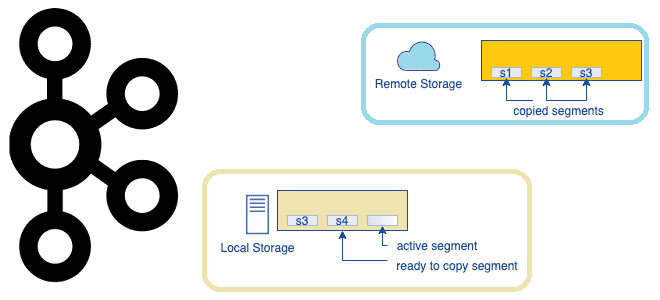
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных. Надежность vs скорость: вечный компромисс в Apache Kafka Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот...
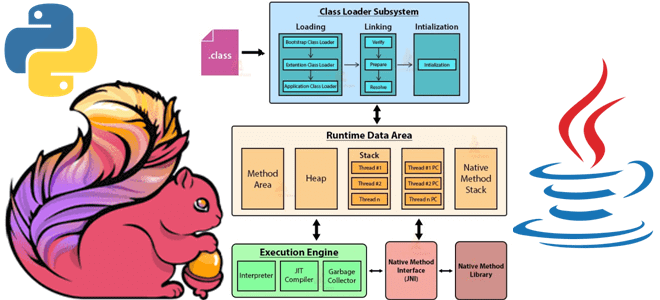
Как и большинство Big Data фреймворков, Apache Flink имеет Python API, позволяя разработчикам высоконагруженных потоковых приложений писать код на этом популярном языке программирования. Однако, Flink-задание выполняется в JVM, поэтому сам фреймворк транслирует Python-код в Java. Разбираемся, в чем особенности этого многоступенчатого процесса. Из Python в Java: как устроен API PyFlink...
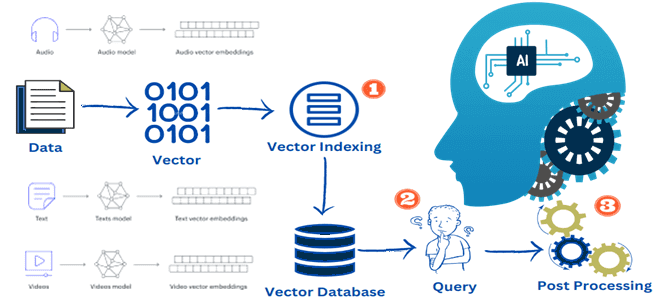
Как устроены векторные базы данных и почему они стали так популярны с распространением ИИ. Архитектура, алгоритмы, принципы работы и примеры векторных СУБД. Что такое векторная СУБД и при чем здесь ИИ Как и следует из названия, векторная база хранит данные в виде векторов. Это понятие из математики означает специализированное представление...

В январе 2023 года компания Arenadata, российский разработчик отечественных Big Data решений, выпустила средство мониторинга и управления коннекторами Apache Kafka для своего продукта Arenadata Streaming (ADS). Знакомимся с возможностями и ограничениями ADSCC. Arenadata Streaming Command Center для управления коннекторами Kafka Одной из главных фишек продуктов Arenadata, является ADCM (Arenadata Cluster...
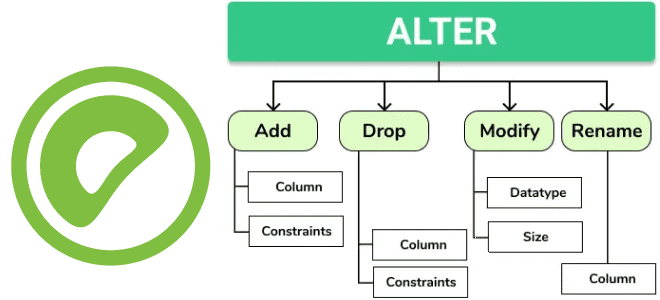
Какие команды изменения таблиц добавлены в 7-ю версию Greenplum и чем они полезны дата-инженеру. Разбираемся с новыми функциями: как добавить столбец, изменить его тип, кодировку хранения и перезаписать несколько таблиц одной командой. Добавление столбца О новых функциях работы с партиционированаными таблицами в Greenplum 7 мы уже писали. В частности, Greenplum...
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...

Недавно мы писали про уязвимости Apache Kafka, обнаруженные и исправленные в 2023 и 2022 гг. Сегодня рассмотрим, как одна из них устранена в отладочном релизе 3.5.1, опубликованного 21 июля 2023 года. А также познакомимся с другими улучшениями и исправлениями ошибок этого выпуска. Обновления Apache Kafka 3.5.1 Релиз Apache Kafka 3.5.1...

Что такое спекулятивное выполнение заданий в Apache Flink, какой планировщик его поддерживает, какие конфигурации нужно настроить для его эффективного использования и зачем при этом переопределять поведение генератора разделений потокового источника данных. Что такое спекулятивное выполнение заданий Apache Flink Распределенная природа Apache Flink приводит к тому, что приложения, созданные с помощью...

От межсайтового скриптинга до внедрения вредоносного кода: какие проблемы информационной безопасности были обнаружены и исправлены в Apache Spark в 2023, 2022 и 2021 годах. Последние известные и исправленные проблемы информационной безопасности Apache Spark Недавно мы писали о механизмах обеспечения информационной безопасности в Apache Spark. Однако, несмотря на наличие этих средств,...
Как устроены по-настоящему мультимодельные базы данных, чем они отличаются от реляционных и NoSQL-СУБД, а также какова истинная природа универсального подхода к хранению и оперированию данными. Разбираемся на примере ArangoDB, OrientDB и Cosmos DB. Что такое мультимодельная СУБД и зачем она нужна Любая технология предназначена, прежде всего, для решения конкретных проблем,...
Почему запросы Flink SQL перестают работать эффективно при больших объемах несбалансированном распределенных данных и как это исправить с помощью мини-пакетной агрегации. Что такое MiniBatch, как это работает и чем может опасно. Перекос данных по ключу группировки в Apache Flink Flink SQL — это мощный инструмент, объединяющий пакетную и потоковую обработку...
Как кодек сжатия snappy может вызвать ошибку нехватки памяти на брокерах, что может нарушить пользовательская JAAS-конфигурация клиента с протоколом безопасности на основе SASL и еще 4 уязвимости Apache Kafka в 2023 и 2022 гг. Уязвимости Apache Kafka 2023 года В 2023 году обнаружена уязвимость CVE-2023-34455, связанная с тем, что клиенты,...

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...

15 июня 2023 года опубликован очередной выпуск самой популярной распределенной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.5.0, особенно важными для разработчиков, дата-инженеров и администраторов кластера. Обновления брокеров, контроллеров, продюсеров и потребителей Релиз Apache Kafka 3.5.0 богат на новинки: в нем 50 улучшений и почти 80 исправленных ошибок....