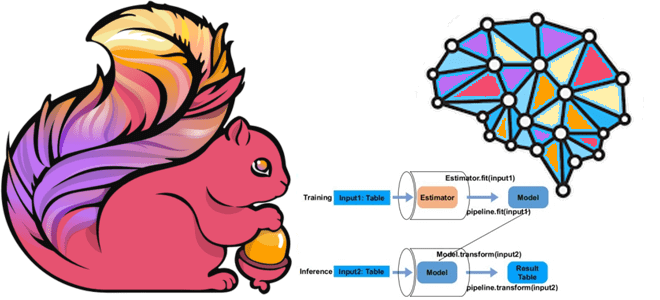
Как построить конвейер машинного обучения с помощью библиотеки Flink ML, из каких компонентов она состоит и как работает, а также что позволяет объединить алгоритмы потоковой обработки данных Apache Flink с ML-моделями. Что такое Flink ML Помимо MLeap, библиотеки сериализации для моделей машинного обучения, Apache Flink также включает Flink ML —...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...
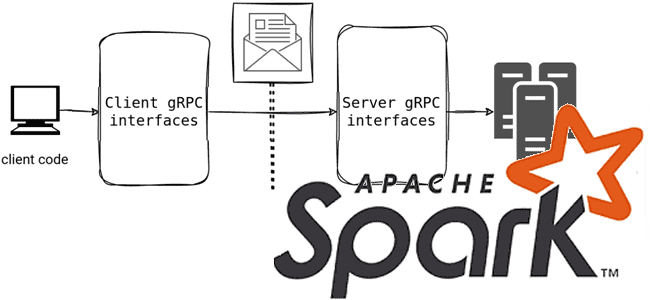
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...

Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...
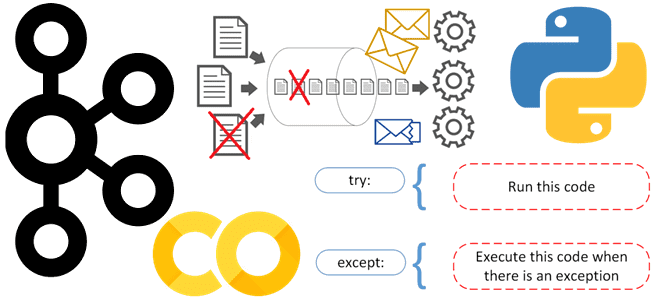
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
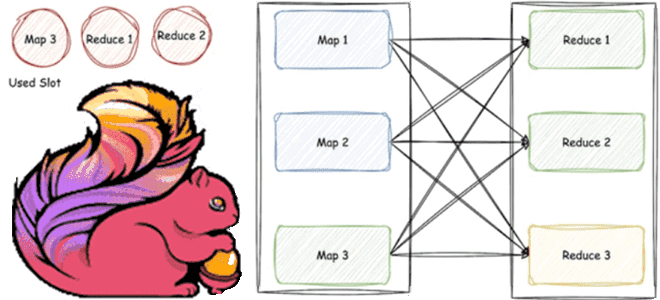
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle. Что такое режим гибридного перемешивания в Apache Flink В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной...
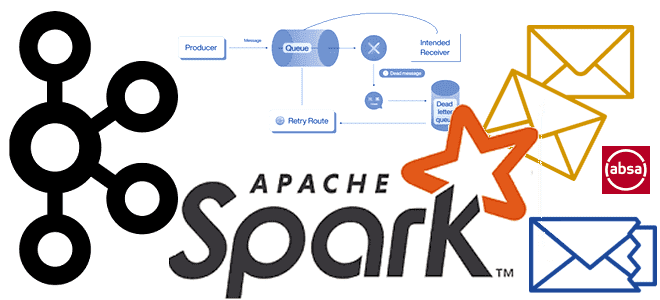
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
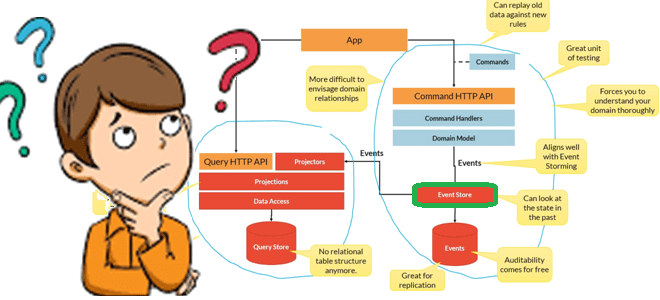
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...
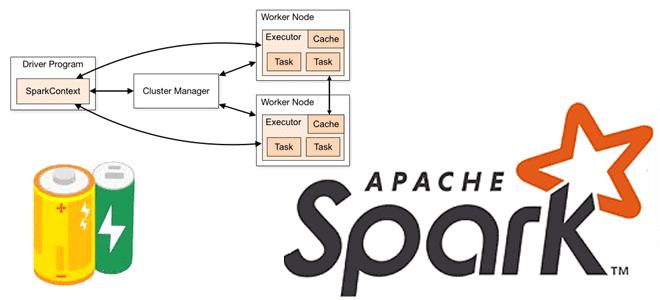
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...
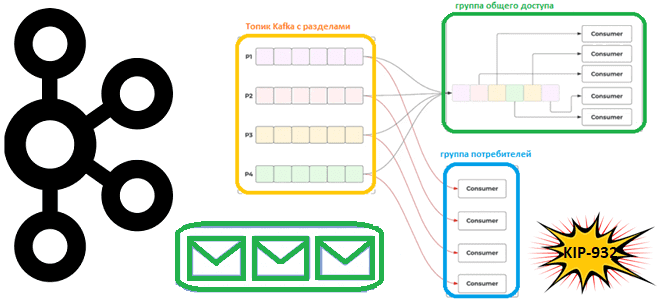
Что такое группы общего доступа для потребителей, чем это отличается от существующей концепции группы потребителей, почему в Apache Kafka появляются очереди и чем это улучшит потоковую обработку событий. Что такое KIP-932: группы общего доступа потребления данных из Apache Kafka Напомним, группы потребителей в Kafka предназначены для повышения надежности упорядоченной доставки...
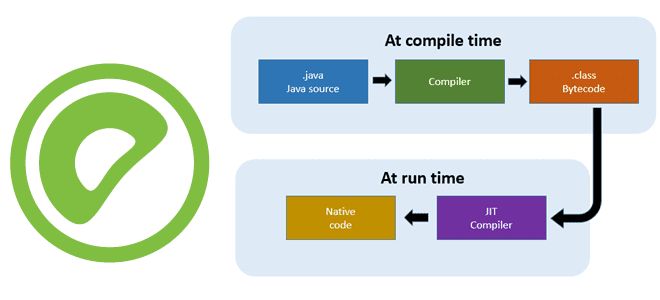
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных. Что такое JIT-компиляция Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Недавно мы писали про источники данных Apache Flink. Сегодня рассмотрим, как создать и протестировать собственный источник данных для их обработки в распределенном приложении. Создание своего источника данных в Apache Flink Напомним, источник данных в Apache Flink состоит из трех основных компонентов: Split, SplitEnumerator и SourceReader. Splits — это часть данных,...
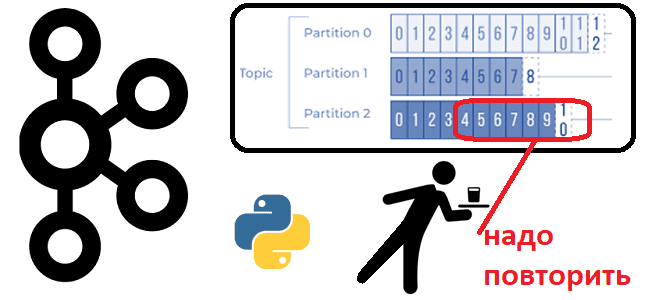
Иногда возникает потребность в повторном чтении данных из Apache Kafka с определенного момента времени. Сегодня рассмотрим, как это сделать, написав простенький Python-скрипт потребления из раздела топика. Публикация данных в Kafka В качестве примера возьмем ранее рассмотренный в этой статье кейс приема потока обращений в интернет-магазин. Обращения могут представлять собой заявки...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...

Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...

Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто. Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения Недавно я показывала, как написать PyFlink-скрипт считывания данных из...
Что такое «проблема разделенного мозга» в распределенных системах, почему она возникает, при чем здесь зомби-продюсеры и как с этим бороться. Разбираем на примере Apache Kafka. Проблема разделенного мозга или зомби-процессы в распределенных системах Термин зомби-процесс пришел из области операционных систем, однако, в распределенных системах его интерпретация абсолютно противоположна исходному значению....