
Как выбирать политики распределения и разделения данных в Greenplum, в чем польза динамического сканирования индексов, зачем регулярно использовать операции VACUUM и ANALYZE, из-за чего тормозят SQL-запросы и как это исправить. Эффективное распределение и разделение Будучи основанной на PostgreSQL, Greenplum расширяет возможности этой замечательной СУБД, добавляя операции с массово-параллельной обработкой. Для...

Насколько быстро работает Apache Kafka в облачной платформе Upstash: пишем простой пример для пары продюсер-потребитель на Python и измеряем задержку. Миллисекундное отставание при публикации и минутная задержка обработки данных на потребителе. Задержка публикации сообщений в Kafka Чтобы измерить задержку асинхронного обмена данными в системе с EDA-архитектурой из продюсера и потребителя...

Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...

Зачем делать моментальные снимки состояния распределенной файловой системы Apache Hadoop, почему не стоит создавать снапшоты HDFS в корневом каталоге и как найти оптимальную частоту сохранения состояния больших данных. Как устроен механизм снапшотов в HDFS Чтобы повысить надежность системы, ее состояние необходимо периодически сохранять. Для баз данных и файловых систем эта...
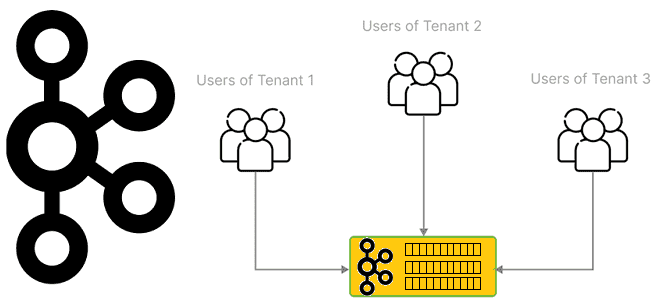
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...

Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions. Apache Flink Stateful Functions Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для...
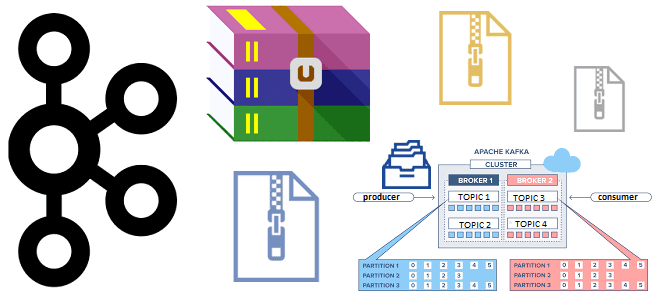
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования. Сжатие сообщений в Kafka: причины использования и принципы работы Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...

Как разница между Scala и Java отражается на работе Spark-приложения, почему код на Scala работает быстрее и когда выбирать этот язык программирования для разработки приложений аналитики больших данных. Scala vs Java: ключевые отличия Хотя Apache Spark позволяет разработчику писать код на нескольких языках программирования (Scala, Java, R, Python), сам фреймворк...
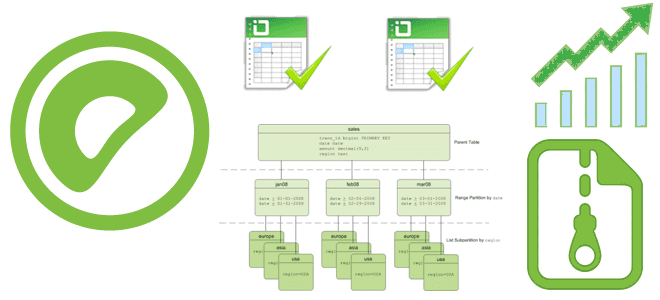
Как включить сжатие данных в Greenplum, какие алгоритмы сжатия поддерживает эта MPP-СУБД и можно ли установить разные параметры сжатия для отдельных столбцов и разделов больших таблиц. Примеры SQL-запросов и рекомендацию по настройке. Как Greenplum сжимает данные: примеры настроек и SQL-запросов Эффективное сжатие данных позволяет Greenplum снижать потребление памяти и повышать...
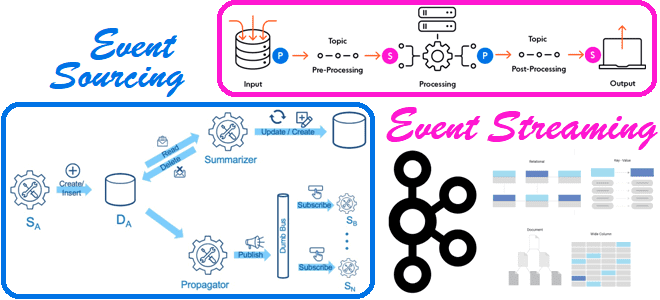
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...

13 сентября 2023 года вышел Apache Spark 3.5. Знакомимся с самыми важными новинками свежего релиза: расширения Spark Connect и SQL, поддержка DeepSpeed, улучшения потоковой передачи и свежие UDF-функции Python. ТОП-5 новинок Apache Spark 3.5.0 В Apache Spark 3.5. добавлено много исправлений и улучшений, а также реализованы новые функции. Наиболее интересными...
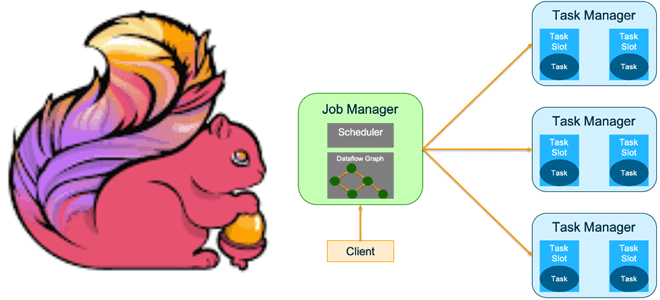
Какие режимы развертывания заданий поддерживает Apache Flink и чем они отличаются. Достоинства и недостатки режима сеанса и режима приложения, а также варианты использования. Особенности развертывания приложения Apache Flink Режим развертывания определяет, с каким уровнем изоляции ресурсов задание Flink будет выполняться в кластере. Напомним, выполнение задания Apache Flink включает 3 объекта:...

Сегодня рассмотрим, какие улучшения Apache Spark опубликованы в 2023 году и как подать свое предложение по улучшению самого популярного вычислительного движка в стеке Big Data. Что такое SPIP и как подать свое предложение по улучшению фреймворка В любом продукте помимо ошибок есть также предложения по улучшению. В Apache Spark они...

Чем отличается оркестрация ETL-процессов в Databricks и Apache AirFlow: принципы работы, достоинства и недостатки, а также что выбирать дата-инженеру для решения практических задач. Apache AirFlow vs Spark в Databricks: сходства и отличия Облачная платформа Databricks, основанная на Apache Spark, предлагает пользователям единую среду для создания, запуска и управления различными рабочими...

Почему в Greenplum 7 восстановление данных из резервной копии базы стало медленнее и как разработчики это исправили: причины замедления и способы их устранения. SQL-синтаксис и восстановление из бэкапа Напомним, 7-ой релиз Greenplum имеет много интересных и полезных функций, включая возможность определять партиционированную таблицу без определения дочерних разделов и изменять таблицы...

Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...

Может ли Apache Kafka поддерживать не только хореографический стиль взаимодействия между разными сервисами, кто и как организует оркестрацию рабочих процессов с помощью этой распределенной платформой потоковой передачи и почему она не заменит BPM-движки. Оркестрация событий с Apache Kafka При использовании Apache Kafka в архитектуре, управляемой событиями (EDA, Event Driven Architecture),...
Какие файловые системы поддерживает Apache Flink: средства взаимодействия с файлами, хранящимися локально или в объектных хранилищах HDFS, S3 и GCS. Особенности работы с файловыми системами в Apache Flink Apache Flink имеет собственную абстракцию файловой системы через класс org.apache.flink.core.fs.FileSystem. Эта абстракция обеспечивает общий набор операций и минимальные гарантии для различных типов...

Что такое квоты в Apache Kafka и как этот механизм позволяет управлять ресурсами брокера, предупреждая DDOS-атаки от слишком активных потребителей и продюсеров. Разбираемся с типами клиентских квот, их конфигурациями и принципами работы. Квоты клиента и пользователя в Apache Kafka Чтобы управлять ресурсами брокера, кластер Kafka может применять квоты на запросы...