 596
596 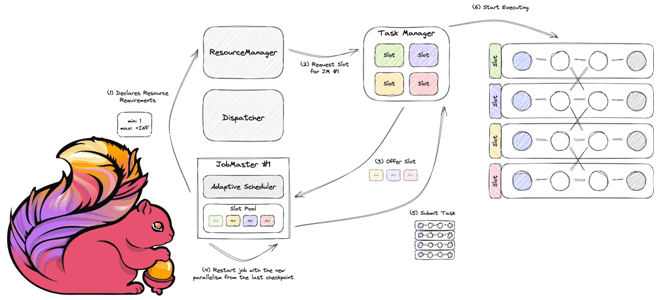
Содержание
Как работает планировщик заданий в Apache Flink, чем разные реализации Scheduler отличаются друг от друга, и каковы преимущества адаптивных планировщиков.
Как Apache Flink планирует выполнение заданий клиентской программы
Архитектура Apache Flink, которую мы рассматривали здесь, включает несколько компонентов. Одним из них является планировщик заданий, которые отправляются клиентским приложением в диспетчер заданий на кластер Flink. Диспетчер заданий передает задание из приложения Apache Flink планировщику, которые решает, какой параллелизм установить для этого задания для оптимального выполнения входящих в него задач. Помимо планирования, планировщик также создает граф выполнения (Execution Graph) и жизненный цикл задач с соответствующими обратными вызовами метода onTaskX().
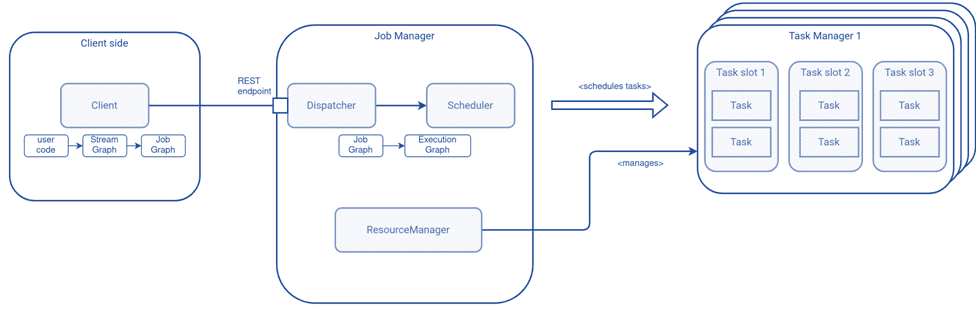
Планировщик имеет различные реализации, зависящие от рабочего процесса:
- DefaultScheduler— планировщик по умолчанию без каких-либо дополнительных функций;
- AdaptiveScheduler – адаптивный потоковый планировщик, который подстраивает параллелизм заданий к доступным слотам. Затем он может увеличить или уменьшить уровень параллелизма в зависимости от наличия свободных ресурсов.
- AdaptiveBatchScheduler— планировщик по умолчанию для пакетных заданий, который наследует адаптивное поведение от AdaptiveScheduler.
- SpeculativeScheduler– планировщик спекулятивного выполнения заданий, когда медленное выполнение одной или нескольких задач может вызвать их запуски, чтобы они завершились быстрее. Он наследуется от AdaptiveBatchScheduler, но вызывается после завершения одной задачи. В случае других запусков он досрочно завершит их.
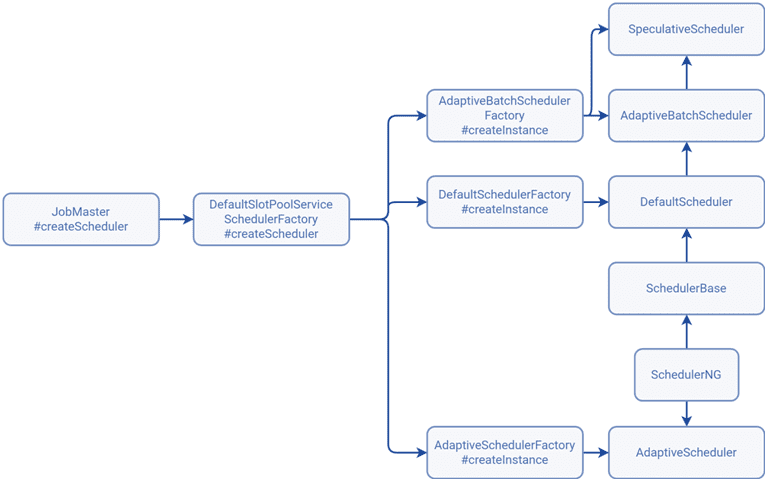
Flink сам создает нужный планировщик в зависимости от параметров менеджера заданий, получаемых вызовом метода getSchedulerType() класса DefaultSlotPoolServiceSchedulerFactory. Для пакетных заданий используется AdaptiveBatchScheduler, если установлена хотя бы одна из этих конфигураций:
- scheduler-mode=reactive;
- scheduler=adaptive.
Иначе планировщик берется из конфигурации jobmanager.scheduler. Если значение не задано, то для динамических графов выполнения заданий используется планировщик по умолчанию DefaultScheduler.
Для потоковых заданий используется AdaptiveScheduler при scheduler-mode=reactive. Иначе берется значение из конфигурации jobmanager.scheduler. Когда в системных свойствах задано flink.tests.enable-adaptive-scheduler, создается AdaptiveScheduler. При отсутствии этих значений применяется планировщик по умолчанию DefaultScheduler.
Преимущество адаптивных планировщиков в том, что они позволяют менять параллелизм задания во время его выполнения. Исторически этот параметр был статическим на протяжении всего жизненного цикла задания и определялся один раз во время его отправки с клиентского Java-приложения в кластер Flink. Пакетные задания вообще нельзя было масштабировать, а потоковые задания можно было остановить с помощью точки сохранения и перезапустить с другим параллелизмом. Но в версии 1.15, о которой мы писали здесь, был впервые реализован AdaptiveBatchScheduler, который может автоматически определять параллелизм вершин пакетных заданий в зависимости от объема обрабатываемых данных. А в версии 1.17 он стал использоваться для пакетных заданий по умолчанию. Далее рассмотрим, как работают эти адаптивные планировщики.
Как работают адаптивные планировщики
Адаптивный планировщик потоковых заданий AdaptiveScheduler может регулировать параллелизм задания в зависимости от доступных слотов. Например, автоматически уменьшает параллелизм, если для запуска задания с недостаточно свободных слотов из-за недостаточности ресурсов на момент отправки или сбоев диспетчера задач TaskManager во время выполнения. Когда появятся новые слоты, задание будет масштабировано до изначально заданного параллелизма. В реактивном режиме настроенный параллелизм игнорируется и обрабатывается так, будто он установлен на бесконечное значение, позволяя заданию всегда использовать как можно больше ресурсов. Одним из преимуществ адаптивного планировщика по сравнению с DefaultScheduler является то, что он может корректно обрабатывать сбои TaskManager.
Адаптивный планировщик основан на функции декларативного управления ресурсами Declarative Resource management, реализованной в версии фреймворка 1.12. Вместо того, чтобы запрашивать точное количество слотов, мастер заданий JobMaster объявляет менеджеру ресурсов ResourceManager желаемые ресурсы, который затем пытается заполнить. Это сделано, чтобы повысить эффективность работы приложения в условиях ограниченных ресурсов и не тормозить JobMaster ожиданием запрошенных слотов. Когда JobMaster получает больше ресурсов во время выполнения, он автоматически масштабирует задание, используя последнюю доступную точку сохранения, устраняя необходимость во внешней оркестрации. Такой подход делает Apache Flink еще ближе к облачному потоковому процессору. Начиная с версии 1.18, можно повторно объявить требования к ресурсам выполняемого задания с помощью внешнего декларативного управления ресурсами. Иначе адаптивный планировщик не сможет обрабатывать случаи, когда задание необходимо масштабировать из-за изменения скорости поступления данных или производительности рабочей нагрузки.
Внешнее декларативное управление ресурсами направлено на следующих сценариях развертывания:
- адаптивный планировщик в кластере сеансов, где несколько заданий могут конкурировать за ресурсы, и разработчику нужен детальный контроль над тем, как они распределяются между заданиями;
- адаптивный планировщик в кластере приложений вместе с Active Resource Manager, например, при развертывании в Kubernetes, где можно положиться на внутренние механизмы Flink для создания новых экземпляров диспетчера задач, но продолжая использовать возможности масштабирования, как в реактивном режиме.
При использовании адаптивного планировщика в кластере сеансов, где предварительная фаза Java-приложения выполняется на стороне клиента, нет никаких гарантий по распределению слотов между несколькими запущенными заданиями в одном сеансе, когда в кластере недостаточно ресурсов. Внешнее декларативное управление ресурсами может частично решить эту проблему. Но все же рекомендуется использовать адаптивный планировщик в кластере приложений, когда создается кластер для каждого отправленного задания, и метод Java-приложения main() выполняется в диспетчере заданий. Чтобы использовать адаптивный планировщик вместо DefaultScheduler на уровне кластера, надо настроить конфигурацию jobmanager.scheduler, задав ей значение adaptive. Поведение адаптивного планировщика настраивается всеми параметрами конфигурации с префиксом jobmanager.adaptive-scheduler.
Планировщик AdaptiveScheduler работает только с потоковыми заданиями. В случае пакетного задания Flink будет использовать AdaptiveBatchScheduler. Планировщик AdaptiveScheduler не поддерживает частичный переход на другой ресурс при сбое, не позволяя перезапустить отдельные части невыполненного задания. Это ограничение влияет только на время восстановления до невозможности параллельных заданий: планировщик по умолчанию DefaultScheduler может перезапустить неисправные части, а адаптивный планировщик перезапустит все задание. События масштабирования вызывают перезапуск заданий и задач, что увеличивает количество попыток их выполнения.
Адаптивный пакетный планировщик AdaptiveBatchScheduler может автоматически корректировать план выполнения пакетных заданий, определяя для них параллелизм операторов. Если для оператора не задан параллелизм, планировщик определит его сам в соответствии с размером потребляемых им наборов данных. Это освобождает разработчика от ручной настройки параллелизма. Кроме того, автоматически настроенные параллелизмы могут лучше соответствовать потребляемым наборам данных, размеры которых меняются каждый день. В настоящее время адаптивный пакетный планировщик является планировщиком по умолчанию для пакетных заданий Flink. Поэтому для его использования не нужны никакие дополнительные настройки, если другие планировщики не настроены явно, например jobmanager.scheduler: default. Для использования AdaptiveBatchScheduler нужно оставить параметр execution.batch-shuffle-mode неустановленным или явно установить для него значения shuffle-режима ALL_EXCHANGES_BLOCKING или ALL_EXCHANGES_HYBRID_FULL вместо ALL_EXCHANGES_HYBRID_SELECTIVE.
Планировщик AdaptiveBatchScheduler может обрабатывать только пакетные задания и выдаст исключение и при попытке потоковой обработки. Он не поддерживает источники FileInputFormat, включая методы readFile(), readTextFile() и createInput(FileInputFormat) класса StreamExecutionEnvironment. Вместо этого разработчику надо использовать коннектор FileSystem DataStream или FileSystem SQL Connector для чтения файлов. Кроме того, при использовании адаптивного пакетного планировщика можно столкнуться с рассинхронизацией результатов широковещательной рассылки в веб-GUI фреймворка, когда количество байтов/записей, отправленных восходящей задачей, подсчитанное метрикой, не равно количеству байтов/записей, полученных нисходящей задачей.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

