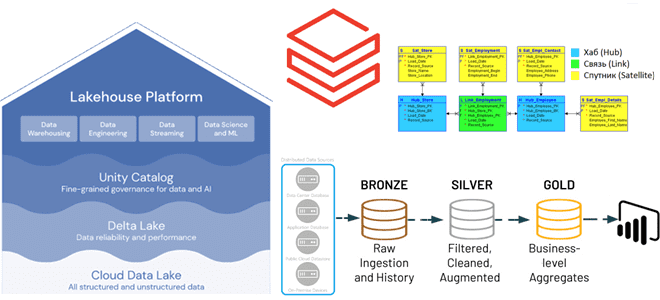
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
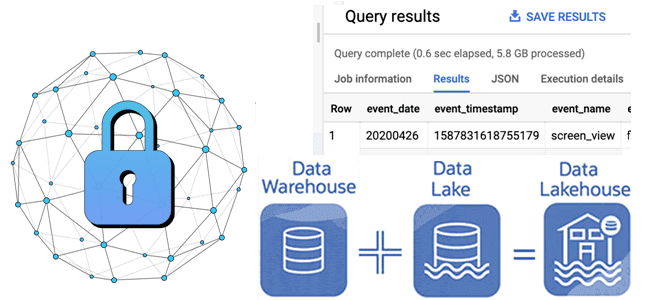
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...
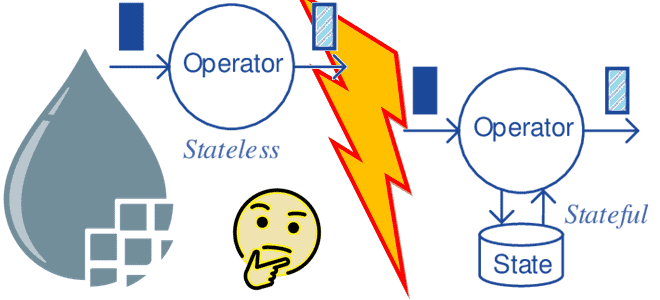
Недавно мы писали, что такое Apache NiFi без сохранения состояния и чем он отличается от классического приложения потокового конвейера обработки данных. Сегодня рассмотрим особенности и ограничения Stateless-механизма и наилучшие сценарии использования в сравнении с классическим движком. Особенности и ограничения Stateless-движка Напомним, классический NiFi предназначен для запуска большого многопользовательского приложения, в...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...
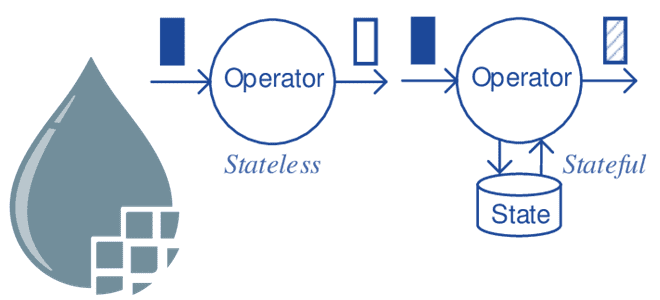
Чем Stateless-движок отличается от классического механизма потоковой обработки данных Apache NiFi, каковы его ключевые принципы работы и почему здесь особенно важна надежность источника. Классический Apache NiFi: основные понятия Приложение Apache NiFi можно рассматривать как два отдельных, но взаимосвязанных компонента: подлинности потока и его движок. Объединив их в одном приложении, NiFi...
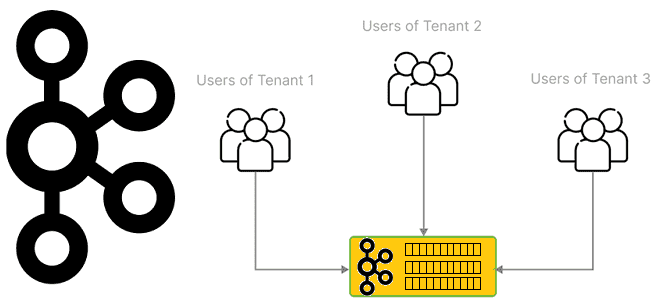
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...
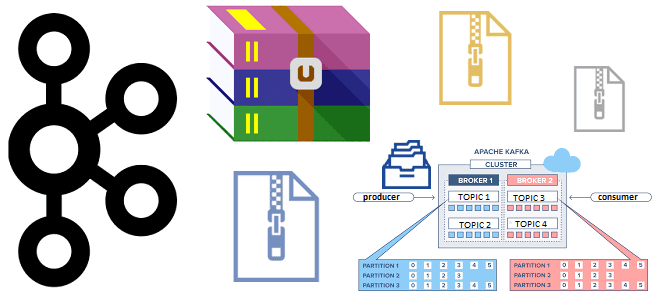
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования. Сжатие сообщений в Kafka: причины использования и принципы работы Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот...
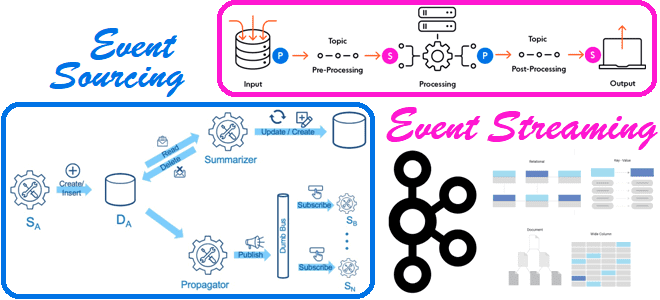
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...
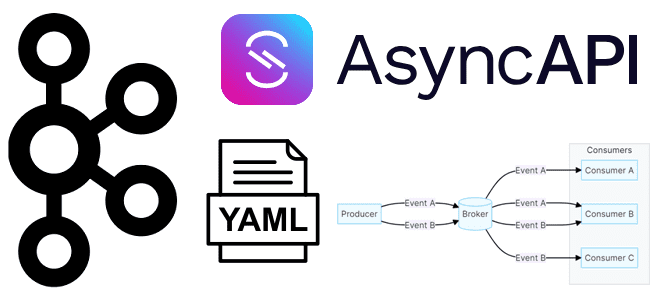
Что такое AsyncAPI, зачем документировать спецификацию для EDA-архитектур и как это сделать. Создаем свою спецификацию для Apache Kafka с помощью веб-инструмента AsynсAPI Studio. Что такое AsyncAPI Подобно тому, как Swagger (OpenAPI ) стал стандартом де-факто для описания синхронного REST API, включая HTTP-методы запросов и ответы приложения на них со структурами...