 1315
1315 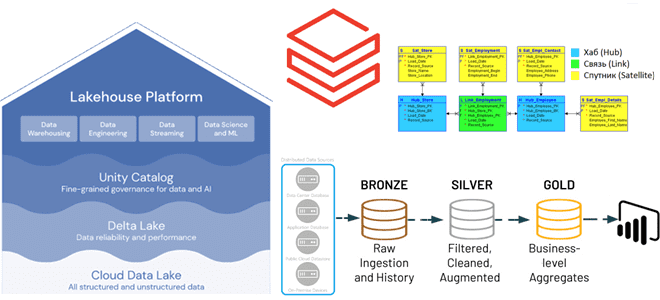
Содержание
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища.
Принципы методологии Data Vault и их применение к проектированию DWH
Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы Кимбала и Инмона, а также Data Vault, о которых мы писали здесь и здесь. Эти методы моделирования могут использоваться при проектировании архитектуры данных Lakehouse. Архитектура данных Lakehouse основанна на открытых стандартах и API которые позволяют сочетать ACID-транзакции и управление данными классических корпоративных хранилищ с гибкостью и экономичностью озер данных. По сути, Lakehouse представляет собой слой поверх классического DWH и/или Data Lake, с чьими данными активно работают ETL-конвейеры, чтобы сделать их пригодными для аналитики и машинного обучения. Подробнее о том, как устроена архитектура данных Lakehouse, мы разбирали здесь и здесь. Сегодня наиболее популярными реализациями архитектуры Lakehouse являются платформы от крупных PaaS-провайдеров. Например, Databricks организует данные, хранящиеся в Delta Lake, в облачном объектном хранилище с помощью схем базы данных, таблиц и представлений.
Чтобы организовать доступ к этим данным в Lakehouse, необходимо сперва спроектировать архитектуру этого хранилища. Для этого отлично подойдет методология Data Vault, которая позволяет быстро и гибко адаптировать структуру данных к меняющимся требованиям. Модель данных, построенная по методологии Data Vault, легко расширяется и детализируется благодаря манипуляциям с ее ключевыми сущностями:
- Хаб (Hub) – основной бизнес-объект, сущность домена, например, клиент, продукт, заказ и пр. Первичный ключ для хаб-таблиц обычно состоит из комбинации идентификатора доменного понятия (бизнес-ключа), даты загрузки данных в хранилище (load timestamp) и их источника (record source). Обычно в качестве первичного ключа хаб-таблиц рекомендуется использовать хэш-значение от бизнес-ключа, сгенерированный с помощью алгоритмов MD5 или SHA-1.
- Ссылка или связь (Link) — отношение между хаб-таблицами, которые имеют только ключи соединения. Это похоже на таблицу фактов в многомерной модели, но без самих фактов. У таблицы ссылок нет никаких атрибутов, а только внешние ключи. Таблица ссылок содержит те же метаданные, что и хаб-таблица: отметку времени и источник данных. Ключи связываемых хаб-таблиц образуют в таблице связей составной ключ.
- Спутник (Satellite) — таблица с контекстными данными для хаб-таблицы. Она похожа на нормализованную версию таблицы измерений и хранит новые или измененные детальные данные. Кроме единственного ключа родительской хаб-таблицы и ее контекстных данных спутник-таблица также содержит отметку времни загрузки данных в хранилище и их источник. Поэтому в таблицах-спутниках можно хранить историю изменения контекста, добавляя новую запись при обновлении данных в системе-источнике.
Главный плюс методологии Data Vault для хранилища данных – это уменьшение сложности рефакторинга ETL-заданий при изменении модели данных благодаря ориентации на запись. Поэтому подход Data Vault отлично подходит для озер и хранилищ данных, включая архитектуру Lakehouse. На платформе Databricks архитектура Lakehouse реализована с помощью возможности Delta Lake создавать хранилища сырых (необработанных) данных, и бизнес-хранилища, в котором хранятся обработанные данные, преобразованные по определенным бизнес-правилам.
Поскольку основная цель Data Vault — это создать масштабируемое и гибкое хранилище данных с устойчивой архитектурой, к модели можно добавлять новые таблицы-хабы и/или ссылки. А загрузка данных в таблицы может происходить параллельно, поскольку они не зависят друг от друга. Например, можно загружать хаб-таблицы клиентов и товаров независимо друг от друга, поскольку они имеют свои собственные бизнес-ключи. Даже таблица ссылок, связывающая клиенты и продукты, а также таблицы-спутники клиентов и товаров могут быть загружены параллельно, поскольку имеют все необходимые атрибуты из источника данных.
Рекомендации по реализации модели хранилища данных в Databricks Lakehouse
Вспомнив, что представляет собой методология Data Vault, рассмотрим, как использовать ее при проектировании архитектуры Lakehouse более эффективно. В качестве примера возьмем реализацию Lakehouse на платформе Databricks. Как уже было отмечено выше, в качестве первичных ключей для хаб-таблиц рекомендуется использовать хэш значение исходных бизнес-ключей. Для этого Databricks поддерживает алгоритмы хэширования MD5 и SHA.
Как и другие архитектуры построения корпоративного хранилища и озера данных, Lakehouse на Databricks имеет каноническую архитектуру Databricks Medallion, которая использует преимущества реализации формата Apache Delta в несколько слоев, когда данные последовательно очищаются и преобразовываются. Схематически это представляется набором слоев:
- бронза, где хранятся необработанные (сырые) данные из исходных систем;
- серебро, где данные с предыдущего слоя отфильтрованы, очищены и обогащены;
- золото, где располагаются агрегаты бизнес-уровня. По сути, это окончательные выходные таблицы, которые можно использовать непосредственно для визуализации данных и BI-запросов.
Когда исходные данные впервые поступают в хранилище в любых форматах (AVRO, CSV, Parquet, XML, JSON и пр.), они преобразуются в таблицы в формат Delta в промежуточной зоне «сырых» (необработанных) данных, чтобы повысить производительность последующего ETL-процесса. Дополнительные бизнес-правила ETL-процесса обычно не применяются при загрузке хранилища необработанных данных. Raw Vault хранит хаб-таблицы, таблицы-спутники и таблицы-ссылки, которые содержат необработанные данные, но тем не менее поддерживают единую версию истины.
Все бизнес-правила ETL-процессов, проверки и обеспечения качества данных, очистки и соответствия применяются между Raw и Business хранилищами. После того как хаб-таблицы, таблицы-спутники и таблицы-ссылки будут помещены в Raw Vault, на их основе можно будет создавать объекты Business Vault. Это необходимо для применения дополнительных преобразования к объектам данных и подготовки к более простому использованию на более позднем этапе. Таблицы Business Vault могут быть организованы по доменам, которые служат корпоративным центральным хранилищем стандартизированных очищенных данных.
Для уровня представления поверх бизнес-хранилища создаются вспомогательные таблицы запросов, такие как таблицы Point-in-Time (PIT) и Bridge. PIT-таблицы повышают производительность SQL-запросов, поскольку некоторые хаб-таблицы и таблицы-спутники предварительно соединены, и предоставляют условия WHERE с фильтрацией по моменту времени. Bridge-таблицы предварительно объединяют хаб-таблицы, чтобы создать плоскую таблицу измерений, например представления для сущностей. Динамические Delta-таблицы аналогичны материализованным представлениям и могут использоваться для создания таблиц на момент времени, а также таблиц-мостов на уровне презентации поверх хранилища бизнес-данных.
По мере изменения и адаптации бизнес-процессов модель Data Vault можно легко расширить без масштабного рефакторинга, как в случае многомерных моделей. В частности, можно добавить дополнительные предметные области в виде хаб-таблиц, вместе с таблицами-ссылками, которые представляют собой чистые таблицы соединений. А затем можно с минимальными изменениями добавить дополнительные таблицы-спутники к хабу. Например, если в хаб-таблице хранятся данные о клиентах, то в таблице-спутнике можно хранить сведения об их сегментации.
Представления Data Vault загружаются на определенный момент времени и витрины данных для удобства использования на последнем уровне, направленном на простое использование и высокую производительность при чтении. Для большинства простых таблиц достаточно создать представления поверх хабов или спутников. Также можно загрузить подходящую звездообразную схему, например, многомерную модель.
Благодаря модели Data Vault загрузка хранилища данных многомерной модели в золотом слое архитектуры Lakehouse становится проще по следующим причинам:
- таблицы-хабы упрощают управление ключами: естественные ключи от хабов можно преобразовать в суррогатные с помощью столбцов Identity;
- таблицы-спутники упрощают загрузку измерений, поскольку содержат все атрибуты;
- таблицы-ссылки упрощают загрузку таблиц фактов, поскольку содержат все связи.
В заключение перечислим несколько рекомендаций по повышению производительности модели Data Vault в Databricks Lakehouse:
- использовать формат Delta для всех таблиц на каждом слое хранилища данных (Raw Vault, Business Vault и Gold Layer);
- использовать индексы OPTIMIZE и Z-порядок для всех ключей соединения таблиц-хабов, ссылок и спутников;
- не делить таблицы слишком сильно, особенно таблицы-спутники небольшого размера;
- индексировать с помощью фильтра Блума для столбцов даты, текущих флагов и предикатов, которые обычно фильтруются для максимальной производительности, особенно если нужно создать дополнительные индексы помимо Z-порядка;
- материализованные представления (Delta Live Tables) значительно упрощают создание PIT-таблиц и управление ими;
- уменьшить оптимальный размер файла (maxFileSize) со значения по умолчанию, равного 1 ГБ, до 32–64 МБ, чтобы сократить количество операций ввода-вывода при получении данных, которые необходимо соединить;
- использовать подсказки для JOIN-операторов только при необходимости, например, для расширенной настройки производительности.
- Чтобы избежать проблем со множеством соединений, особенно когда есть сложный запрос или факт, требующий атрибутов из нескольких таблиц, лучше предварительно соединить таблицы и сохранить рассчитанные метрики, чтобы не пересчитывать их много раз на лету.
Освойте работу с современными архитектурными паттернами и инструментами для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

