 1061
1061 
Содержание
Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks.
Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake
В озере данных физическое расположение данных может оказать большое влияние на производительность запросов и вычислительных операций. По сути, расположение данных представляет собой способ хранения данных в памяти или на диске. Оно считается сбалансированным, когда данные равномерно распределены по носителю данных. Для Delta Lake необходимо оптимизировать размещение данных так, чтобы достичь одинакового размера файла и соответствующего количества файлов в заданном наборе данных. Сбалансированное расположение данных необходимо для эффективного пропуска данных во время выполнения запроса, чтобы игнорировать ненужные файлы и не считывать их в память для обработки запроса. Несовпадение данных и другие несоответствия могут привести к неоптимальному пропуску данных, увеличению времени выполнения и потенциальным сбоям при выполнении.
Изначально в Delta Lake расположение данных основано на стратегии их разделения, что означает выбор одного из 2-х вариантов при разработке таблиц в архитектуре Lakehouse:
- партиционирование в стиле Hive физически разделяет данные по папкам, позволяя быстрее выполнять запросы к озеру данных, если запрос допускает пропуск определенных файлов данных. Этот способ требует, чтобы данные хранились в отдельных файлах, даже если это всего лишь одна строка данных. Поэтому разделение в стиле Hive не подходит для озера данных с множеством небольших файлов: механизмы запросов работают слишком медленно при операциях со списком файлов. Поэтому Databricks рекомендует не разделять таблицы, содержащие менее терабайта данных.
- Z-упорядочение – метод размещения связанной информации в одном наборе файлов и направлено на создание равномерно сбалансированных файлов данных по количеству кортежей, но не обязательно по размеру данных на диске. Z-упорядочение не является идемпотентным, а представляет собой инкрементную операцию. Время, необходимое для Z-упорядочения, не гарантированно уменьшится за несколько прогонов. Однако, если в раздел, который был только что упорядочен по Z, не было добавлено никаких новых данных, повторное упорядочение по Z этого раздела не будет иметь никакого эффекта. Локальный характер Z-упорядочения автоматически используется Delta Lake в алгоритмах пропуска данных Databricks, уменьшая объем данных, которые необходимо прочитать. Для Z-упорядочения данных дата-инженер указывает столбцы для упорядочения в предложении ZORDER BY в выражении SQL:
OPTIMIZE events WHERE date >= current_timestamp() - INTERVAL 1 day ZORDER BY (eventType)
Можно указать несколько столбцов в виде списка, разделенного запятыми, но эффективность такого решения падает с каждым дополнительным столбцом из-за отсутствия актуальной статистики по нему.
Delta Lake использует Apache Parquet в качестве основного формата для хранения данных: таблицы Delta организованы подобно таблицам Parquet с помощью Apache Spark, который использует разделение в стиле Hive при сохранении данных в формате Parquet. Однако, разделение в стиле Hive не является частью протокола Delta Lake, и рабочие нагрузки не должны полагаться на эту стратегию партиционирования для взаимодействия с таблицами Delta.
Считается, что разделение ускоряет выполнение запросов к Data Lake, однако, этот прием имеет и недостатки:
- хранение информации о разделах как части пути к файлу вводит физические границы между разделами и делает партиционирование менее гибким и статическим методом компоновки, усложняя управление разделами и их обновление с полной перезаписью данных.
- разделение может привести к неравномерности данных, когда некоторые разделы намного больше других. Разделение эффективно применяться к полям с низкой кардинальностью, т.е. к столбцам с небольшим количеством различных значений. А разделение по столбцам с большим количеством элементов приведет к созданию множества небольших файлов, которые невозможно объединить. Это удлиняет время выполнения запросов из-за падения производительности сканирования.
Таким образом, при некорректно выбранной стратегии разделения некоторые разделы могут содержать мало данных или вообще не содержать их, а другие будут содержать несколько больших файлов, которые лучше разбить на более мелкие части. Некоторые разделы могут включать несколько небольших файлов, которые следует объединить, исключив ненужное разделение.
Как работает Liquid Clustering от Databricks
Чтобы упростить выбор и реализацию стратегии разделения данных, в новом релизе Delta Lake 3.0 от Databricks, выпущенном в конце июня 2023 года, была представлена так называемая жидкая кластеризация (Liquid Clustering). Это новый метод оптимизации размещения данных в таблицах Delta Lake. Он направлен на повышение эффективности операций чтения и записи, а также упрощение настройки и сокращение накладных расходов на управление данными. Этот метод специально разработан для решения проблем, возникающих при разделении данных в стиле Hive и Z-упорядочении. Он обеспечивает высокую адаптивность решения к изменяющимся шаблонам данных, требований масштабирования и сложностей с неравномерностью распределения.
Liquid Clustering позволяет установить ключи жидкой кластеризации для наиболее часто запрашиваемых столбцов, чтобы использовать их как ключи разделения, не беспокоясь о кардинальности столбца и порядке партиционирования. Этот метод постепенно кластеризует новые данные, обеспечивая стабильно высокую производительность чтения, и отличается гибкостью: можно быстро изменить столбцы, кластеризуемые таким образом, без перезаписи существующих данных.
В отличие от Hive-разделения и Z-упорядочения, ключи жидкой кластеризации можно выбирать исключительно на основе шаблона предикатов запроса и менять их без перестройки всей таблицы. Этот метод устраняет концепцию разделов и может динамически объединять или дополнительно разделять файлы, чтобы получить сбалансированный набор данных с идеальным количеством и размером файлов. Такой эффект достигается за счет использования древовидного алгоритма для постепенного сопоставления структуры данных и сохранения связанных метаданных как части журналов Delta Lake таблицы.
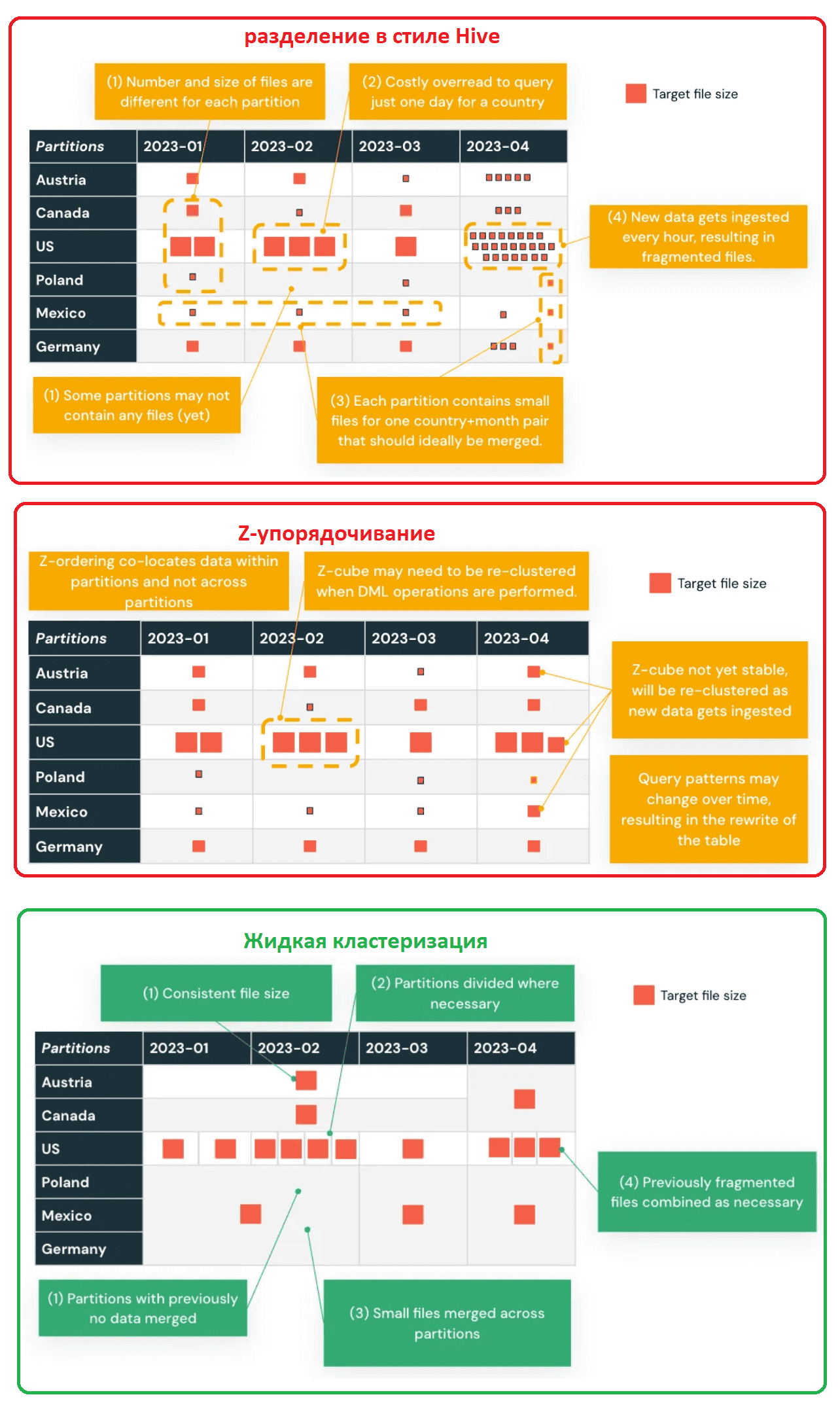
Следовательно, жидкая кластеризация учитывает состояние и не требует повторного расчета каждый раз при выполнении команды OPTIMIZE. Это свойство также делает возможной по-настоящему инкрементальную кластеризацию, когда вновь принимаемые данные кластеризуются по мере необходимости, игнорируя ранее кластеризованные данные. Работа с более крупными блоками по сравнению с Z-упорядочением также делает обслуживание таблиц значительно более эффективным. Более того, благодаря этому подходу становится возможной кластеризация при записи как часть приема данных. Устранение необходимости в физических границах разделов и динамическом объединении/разделении файлов данных улучшает пропуск ненужных столбцрв, ускоряя время выполнения запросов к Data Lake. Сохранение метаданных также позволяет обнаруживать и исправлять искажения, а также улучшать поддержку параллелизма на уровне записи, а не на уровне раздела. Можно сказать, что жидкая кластеризация обеспечивает гораздо более высокую степень гибкости в пределах границ предыдущих разделов, достигая желаемого размера файла более последовательным способом.
Чтобы использовать жидкую кластеризацию, необходимо создать таблицу Delta Lake, указав столбцы кластеризации с помощью ключевого слова CLUSTER BY. Например, следующий SQL-запрос создает таблицу транзакций для хранения данных о транзакциях, такие как идентификатор, страна, месяц, отправитель, получатель, сумма и комментарий. Выражение CLUSTER BY (country, month) указывает, что данные в таблице будут кластеризоваться, т.е. группироваться и сортироваться по стране и месяцу для оптимизации запросов.
CREATE TABLE transactions ( id BIGINT, country STRING, month DATE, transactionTime TIMESTAMP, senderId INT, recipientId INT, amount DECIMAL, note STRING ) CLUSTER BY (country, month)
Databricks рекомендует жидкую кластеризацию для всех новых таблиц Delta в следующих сценариях:
- таблицы часто фильтруются по столбцам разной мощности;
- таблицы имеют значительный перекос в распределении данных;
- таблицы быстро растут и требуют усилий по обслуживанию и настройке;
- таблицы имеют требования к одновременной записи;
- таблицы имеют шаблоны доступа, которые меняются со временем;
- таблицы, в которых типичный ключ раздела может оставить таблицу со слишком большим или слишком малым количеством разделов.
Таким образом, жидкая кластеризация может значительно повысить производительность операций чтения и записи в таблицах Delta Lake по сравнению с разделением в стиле Hive и Z-упорядочением, обеспечивает лучшую поддержку параллелизма и более эффективна при обслуживании данных благодаря инкрементальному подходу. Жидкой кластеризацией легче управлять и обновлять, она поддерживает эволюцию ключей кластеризации и снижает необходимость обслуживания таблиц, а также сокращает искажение и фрагментацию данных, что повышает производительность запросов.
Пока эта функция Delta Lake 3.0 находится в статусе бета-версии и имеет следующие ограничения:
- можно указать только столбцы со статистикой, собранной для ключей кластеризации. Но по умолчанию статистика собирается в первых 32 столбцах таблицы Delta.
- в качестве ключей кластеризации можно указать до 4 столбцов;
- рабочие нагрузки структурированной потоковой передачи не поддерживают кластеризацию при записи.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://www.databricks.com/blog/announcing-delta-lake-30-new-universal-format-and-liquid-clustering
- https://medium.com/closer-consulting/liquid-clustering-first-impressions-113e2517b251
- https://medium.com/@stevejvoros/liquid-clustering-an-innovative-approach-to-data-layout-in-delta-lake-1a277f57af99
- https://docs.databricks.com/en/tables/partitions/

