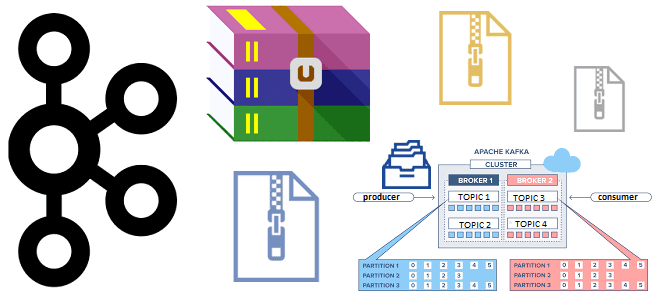
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования.
Сжатие сообщений в Kafka: причины использования и принципы работы
Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот раздел. Так обеспечивается высокая пропускная способность, которую можно сделать еще больше за счет эффективных алгоритмов сжатия передаваемых данных. Помимо сокращения сетевого трафика, подходящая стратегия сжатия позволяет лучше утилизировать емкость постоянного хранилища, т.е. жесткого диска, куда Kafka сохраняет все опубликованные сообщения. Поскольку на каждый раздел топика назначается один или несколько независимых друг от друга потребителей (с разным group.id), потребление в такой мультиарендной системе должно быть максимально эффективным, т.к. неравномерность загрузки приводит к возникновению узких мест в нижестоящей инфраструктурной службе.
Выделяют 2 ключевые причины неэффективности мультиарендной системы: чрезмерное копирование байтов и слишком много мелких операций ввода-вывода. Для устранения первой причины Kafka сериализует сообщения в стандартизированный двоичный формат, который используется продюсером, брокером и потребителем, поэтому фрагменты данных передаются без изменений. В отличие от типичной системы, в которой операционная система и приложение выполняют несколько операций чтения и записи, прежде чем данные будут отправлены по сети, Kafka ожидает наличия нескольких потребителей для одного топика. Используя оптимизацию нулевого копирования, предлагаемую современными операционными системами Unix и Linux с системным вызовом sendfile(), данные копируются в кэш страниц ровно один раз и повторно используются при каждом использовании, вместо хранения в памяти и копирования в пользовательское пространство. Это позволяет использовать сообщения со скоростью, приближающейся к пределу сетевого подключения. Благодаря вызову sendfile() и использованию страничного кэша в кластере Kafka практически отсутствует активность прямого чтения с дисков, поскольку потребители считывают данные исключительно из кэша.
Чтобы сократить количество операций ввода-вывода, протокол Kafka построен на абстракции пакетной группировки сообщений. Это позволяет сетевым запросам группировать сообщения и амортизировать накладные расходы на передачу данных по сети, а не отправлять по одному сообщению за раз. Сервер, в свою очередь, добавляет фрагменты сообщений в свой журнал за один раз, а потребитель получает за раз большие линейные фрагменты. Эта простая оптимизация увеличивает скорость на порядки. Пакетная обработка приводит к увеличению сетевых пакетов, более крупным последовательным операциям с диском и смежным блокам памяти. Все это позволяет Kafka превращать пакетный поток случайных записей сообщений в линейные записи, которые передаются потребителям. Подробнее о том, как устроена публикации сообщений в Kafka мы писали здесь.
Впрочем, иногда узким местом всей EDA-системы является не процессор или диск, а пропускная способность сети. Это особенно актуально для распределенного по нескольким дата-центрам конвейера обработки данных. Поэтому Kafka поддерживает сжатие пакетов сообщений, сжатого на стороне продюсера. Брокер распаковывает пакет для проверки соответствия фактического количества записей с тем, что указано в заголовке пакета. После проверки пакет сообщений записывается на диск в сжатом виде. Приложение-потребитель считывает пакет также в сжатом виде и распаковывает полученные данные на своей стороне. Сжатые сообщения идентифицируются специальным заголовком, который распознает потребитель и распаковывает все полученные сжатые сообщения. Результатом распаковки являются только распакованные сообщения, после чего приложение-потребитель может обрабатывать считанные сжатые и несжатые сообщения. О том, насколько потребитель может отставать от продюсера, читайте в нашей новой статье.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
20 января, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Чтобы отличить сжатые сообщения от несжатых, в заголовке сообщения есть байт атрибутов сжатия. Заголовок сообщения имеет следующий вид:
- байт сжатия (1- сообщение сжато, 0 – сообщение не сжато);
- однобайтовые атрибуты сжатия — младшие 2 бита в байте атрибутов выбирают кодек сжатия, используемый для сжатия данных;
- 4 байта CRC32 полезной нагрузки
Таким образом, приложение-потребитель может обрабатывать сообщения от продюсеров, которые отправляют как сжатые, так и несжатые сообщения. Но, несмотря на такую универсальность, для достижения оптимальной сквозной производительности рекомендуется по возможности использовать один тип сжатия на стороне всех приложений-продюсеров, чтобы исключить неравномерность нагрузки на загрузку ЦП, сети и диски из-за разных алгоритмов.
Apache Kafka поддерживает несколько кодеков сжатия: gzip, snappy, lz4 и zstd. Параметр none означает отсутствие сжатия. Кодек lz4 считается более производительным, чем gzip, который, хоть и дает высокую степень сжатия, не рекомендуется из-за высоких накладных расходов. Если необходима высокая степень сжатия, аналогичная gzip, но с меньшей нагрузкой на процессор, можно использовать zstd. Впрочем, для большинства вариантов использования подходит snappy. Таблицу сравнения разных кодеков сжатия для разных форматов данных смотрите здесь.
Следует отметить, что тип сжатия в заголовке не доходит до потребителя, поэтому можно использовать инструмент DumpLogSegments для проверки файлов в брокере, вызвав команду
kafka-run-class kafka.tools.DumpLogSegments --files /path/to/log/file --print-data-log
Результат покажет используемый кодек сжатия:
compresscodec: <CODEC>
Побочным эффектом сжатия является усложнение кода на стороне приложения-потребителя. В частности, обслуживание смещения становится немного сложнее: Zookeeper обновляет потребляемое смещение каждый раз, когда сообщение потребляется. Для несжатых данных потребляемое смещение будет увеличиваться на 1 после однократного считывания одного сообщения. Для сжатых данных потребляемое смещение увеличивается на одно сжатое сообщение, что может привести к дублированию данных в случае сбоя потребителя.
Разобравшись с тем, как работает сжатие сообщений в Apache Kafka, далее рассмотрим, как и где настроить соответствующие конфигурации.
Как настроить сжатие
Как уже было отмечено выше, за сжатие данных отвечают приложения-продюсеры, публикующие сообщения в один и тот же раздел топика Kafka. Для настройки параметров сжатия есть целый ряд конфигураций, причем как на стороне продюсера, так и на стороне самого топика.
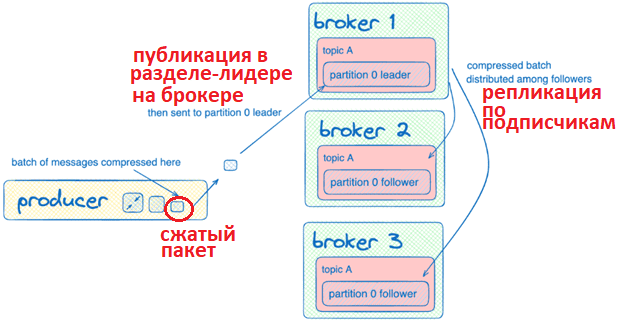
Если данные сжимаются для нескольких разделов в одном пакете, этот пакет придется отправить нескольким лидерам, которые отправят больше данных по сети, что нивелирует положительный эффект от сжатия. Поскольку брокеры всегда выполняют некоторую пакетную распаковку для проверки данных, следует использовать один и тот же коде, а также настроить размер пакета для продюсера, задав значения конфигурациям batch.size и linger.ms. Небольшой размер пакета экономит память и уменьшает временную задержку публикации, а большой размер пакета увеличивает пропускную способность, но требует больше памяти.
Производительность сжатия важна для продюсера, а производительность распаковки – для потребителя и брокеров. Также производительность сжатия имеет значение, если конфигурация топика compression.type отличается от того, что установлено для сжатия на уровне продюсера.
Параметр сжатия на уровне топика можно настроить так, чтобы он подчинялся аналогичной конфигурации продюсера. Остальные типы сжатия на уровне топика имеют приоритет над типом сжатия на уровне продюсера и переопределяют его с точки зрения кодека, используемого для хранения сообщений в брокере и отправки их потребителям. В следующей таблице приведены рекомендации по наиболее часто используемым комбинациям типов сжатия, а также сценарии их использования.
|
Тип сжатия на уровне топика (Topic compression.type) |
Тип сжатия на уровне продюсера (Producer compression.type) |
Тип сжатия для связи продюсера с брокером |
Тип сжатия для хранения данных у брокера и его взаимодействия с потребителем |
Сценарий использования и особенности применения |
|
producer |
none |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне продюсера |
Это ненастроенное значение по умолчанию. Считается подходящим для разработки, но не рекомендуется для производства, если не подтверждено тестированием производительности |
|
producer |
gzip, snappy, lz4, zstd |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне продюсера |
Это распространенное сочетание, возлагающее ответственность на продюсера |
|
gzip, snappy, lz4, zstd |
Отличается от типа сжатия на уровне топика, но не может быть none |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне топика |
В этой ситуации брокеру придется выполнить повторное сжатие, используя Compression.type топика. Обычно это нежелательный результат, но он может применяться в определенных сценариях, например, устаревшие продюсеры используют другие подходы к сжатию, и надо применить новый тип сжатия на уровне кластера |
|
gzip, snappy, lz4, zstd |
Такой же как на уровне топика |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне топика |
Не рекомендуется, поскольку если в конечном итоге будет изменен тип сжатия продюсера, брокер переопределит его, что обычно нежелательно. Вместо этого лучше использовать сжатие на уровне топика со значением compress.type = Producer |
|
gzip, snappy, lz4, zstd |
none |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне топика |
Эти комбинации встречаются редко, но могут применяться в некоторых крайних случаях, например, когда продюсер или потребитель ограничен ЦП, но не является узким местом сети. В первом случае продюсер не сжимает данные, но это делается на уровне топика при хранении или передаче потребителю. Не рекомендуется в качестве первоначальной конфигурации, но может рассматриваться только после тщательного сквозного анализа пропускной способности. |
|
uncompressed |
gzip, snappy, lz4, zstd |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне топика |
|
|
uncompressed |
none |
Тип сжатия на уровне продюсера |
Тип сжатия на уровне топика |
Не рекомендуется, поскольку при изменении типа сжатия продюсера брокер переопределит его и сохранит/передаст данные потребителю в несжатом виде. Вместо этого лучше использовать сжатие на уровне топика со значением compress.type = Producer. |
Разумеется, при использовании значений конфигурации по умолчанию, следует проверить, соответствуют ли они ожидаемому результату. В заключение отметим, что зашифрованные данные не следует сжимать из-за случайного характера алгоритмов шифрования, поскольку это снижает эффективность сжатия. С другой стороны, можно шифровать уже сжатые данные, чтобы обеспечить их безопасность.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.confluent.io/blog/apache-kafka-message-compression/
- https://docs.confluent.io/kafka/design/efficient-design.html
- https://cwiki.apache.org/confluence/display/KAFKA/Compression