Недавно мы писали, что такое Apache NiFi без сохранения состояния и чем он отличается от классического приложения потокового конвейера обработки данных. Сегодня рассмотрим особенности и ограничения Stateless-механизма и наилучшие сценарии использования в сравнении с классическим движком.
Особенности и ограничения Stateless-движка
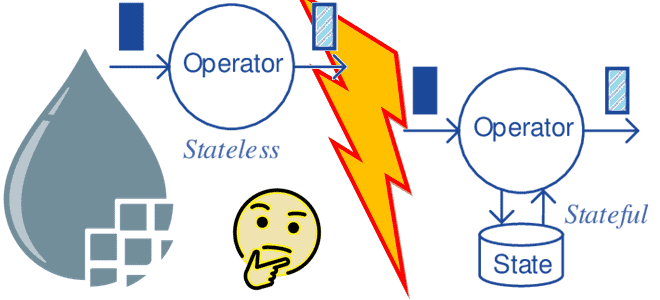
Напомним, классический NiFi предназначен для запуска большого многопользовательского приложения, в полной мере использует все предоставленные ресурсы, обеспечивая надежность потокового конвейера за счет сохранения данных на каждом этапе. Stateless-движок поддерживает тот же API, позволяя работать со всеми процессорами и определениями потоков базового фремворка, но выполняет фиксацию данных только после успешного завершения всего потока.
Поэтому Stateless-механизм требует, чтобы источник данных был надежным и воспроизводимым, что гарантируют не все системы. Кроме того, каждый поток данных, запускаемый в Stateless-режиме, должен храниться в одном источнике и одном приемнике или пункте назначения, чтобы избежать дублирования данных. Поскольку данные в NiFi Stateless проходят через поток данных синхронно от начала до конца, использовать процессоры, которым требуется несколько FlowFile, не получится. Например, MergeContent и MergeRecord, которым нужны все данные для выполнения слияния. Если процессор имеет данные в очереди и запускается, но не может добиться какого-либо прогресса, Stateless-механизм снова запускает исходный процессор, чтобы ему дополнительные данные. Иногда это может привести к ситуации, когда данные будут поступать постоянно, в зависимости от поведения процессора. Чтобы избежать этого, объем данных, которые могут быть переданы при одном вызове потока данных, ограничивается с помощью настроек конфигурации.
Например, если конфигурация потока данных ограничивает объем данных на один вызов, а процессор MergeContent настроен так, что ожидает определенного количества данных, поток будет продолжать запускать MergeContent без какого-либо прогресса до тех пор, пока истечет максимальный срок хранения или время потока данных.
Кроме того, в зависимости от контекста, в котором выполняется Stateless, запуск исходных компонентов может не предоставить дополнительные данные. Например, если Stateless запускается в среде, где данные ставятся в очередь во входном порту, а затем запускается поток данных, последующий запуск входного порта не приведет к созданию дополнительных данных. Поэтому дата-инженер должен убедиться, что все потоки данных, содержащие логику для объединения FlowFiles, настроены с использованием максимального срока хранения для MergeContent и MergeRecord. В стандартном развертывании NiFi в этой ситуации обычно происходит зацикливание ошибочного соединения от исходного процессора обратно к нему же. Это приводит к тому, что процессор постоянно пытается обработать FlowFile, пока не добьется успеха. В классическом приложении NiFi получает данные и отвечает за владение ими, храня их до тех пор, пока нижестоящие службы не смогут получить эти данные. Однако, в случае с Stateless NiFi хранение не реализуется, а источник данных считается надежным и воспроизводимым, что не всегда соответствует действительности.
Кроме того, Stateless-движок не сохраняет данные после перезапуска, поэтому алгоритмы обработки сбоев могут быть разными. При использовании Stateless-механизма в случае невозможности доставить данные в нижестоящую систему следует направить FlowFile на выходной порт, а затем пометить его как порт сбоя.
Наконец, при использовании механизма без сохранения состояния потоки не должны загружать большие файлы, поскольку, в отличие от классического NiFi, содержимое FlowFile хранится не на диске, а в памяти, в куче JVM. А память не предназначена для долговременного хранения больших объемов данных. Поэтому не рекомендуется загружать большие файлы, такие как набор данных размером 100 ГБ, в NiFi Stateless. Это приводит к ошибке OutOfMemoryError или к значительной сборке мусора, что сильно снижает производительность. Впрочем, частично обойти это ограничение можно, настроив Stateless-движок на использование репозитория контента с диска.
Классический Apache NiFi vs Stateless-механизм: ключевые отличия
Чтобы резюмировать отличия классического механизма Apache NiFi от Statless-движка, сравним их по следующим критериям:
- Ключевое назначение;
- Долговечность хранения данных;
- Порядок обработки данных;
- Работа с памятью (кучей JVM);
- Работа в режиме клиента или сервера;
- Особенности потребления ресурсов;
- Надежность происхождения данных;
- Варианты использования.
Для наглядности сравнения составим таблицу.
| Критерий | Классический NiFi | NiFi Stateless |
| Ключевое назначение | Позволяет создавать поток данных и запускать его в режиме реального времени в наглядном GUI | Не включает пользовательский интерфейс для создания или мониторинга потоков данных, а просто запускает потоки данных, созданные с помощью классического приложения NiFi |
| Долговечность хранения данных | Данные надежно хранятся на диске в репозиториях FlowFile и Content | Данные хранятся в памяти и должны быть снова использованы из источника при перезапуске |
| Порядок обработки данных | Данные упорядочиваются независимо в каждом соединении на основе выбранных приоритетов | Данные проходят через систему в порядке их получения по принципу FIFO (First In – First Out) |
| Работа с памятью (кучей JVM) | Большинство процессоров могут использоваться множеством пользователей. Но содержимое FlowFile не следует загружать в кучу JVM, поскольку это может привести к ее исчерпанию | Меньшие по объему потоки данных используют меньше памяти в кечу JVM. Поток работает только с одним или несколькими FlowFile одновременно и хранит их содержимое в памяти кучи JVM |
| Работа в режиме клиента или сервера | Поддерживает все возможности, включая роли сервера и клиента | Может отправлять или извлекать экземпляр NiFi, но не может получать входящие соединения, работая как клиент, а не как сервер |
| Особенности потребления ресурсов | Использует все преимущества многоядерных ЦП и жестких дисков | Однопоточная обработка |
| Надежность происхождения данных | Поддерживает полностью сохраненные, индексированные данные о происхождении, которые можно просматривать через пользовательский интерфейс и экспортировать с помощью задач отчетности | Ограниченные возможности происхождения данных, события сохраняются в памяти. Нет возможности просмотра, но можно экспортировать с помощью задач отчетности. Но эта возможность имеет ограниченный срок действия, поскольку данные находятся в памяти и будут потеряны при перезапуске, а также могут исчезнуть при сбое |
| Варианты использования | Подходит для работы с ненадежными источниками данных, отлично работает при наличии доступа к быстрому хранилищу, такому как SSD и диски NVMe, гарантируя надежность сохранения данных до их передачи в системы-приемники.
Хотя технически возможно встроить стандартный движок NiFi в другие приложения, это не рекомендуется из-за тяжеловесного пользовательского интерфейса, сложной аутентификации и |
Подходит для потоков данных, где источник данных является надежным и воспроизводимым, или в сценариях, где потеря данных не критична. Например, чтение данных из Apache Kafka или JMS-брокеров, а затем выполнение маршрутизации, фильтрации или обработки с последующей доставкой данных в место назначения. Почему возникло это ограничение, мы рассказываем здесь.
Имеет минимальные внешние зависимости (каталог, содержащий расширения, и рабочий каталог для временного хранения), и им гораздо проще управлять. Поэтому отлично встраивается в другие приложения. |
Освойте администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

