Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки.
Что такое мультиарендность и как реализовать эту модель для кластера Kafka
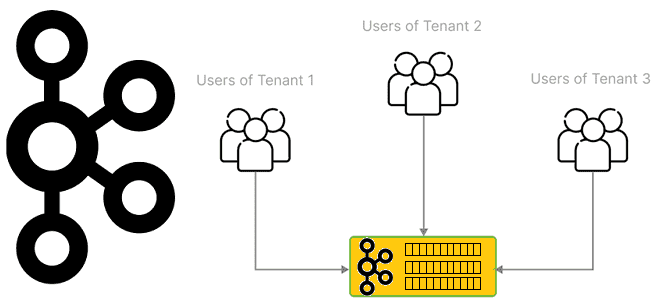
Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими независимыми клиентами (арендаторами). В отличии от виртуализации, когда каждый экземпляр приложения запускается на выделенной логической машине, в мультиарендной среде один экземпляр ПО используется множеством пользователей в одной операционной системе и на одном оборудовании. Такая модель позволяет реализовать разделение ресурсов и изолировать работу пользователей. С точки зрения поставки продукта мультиарендность может увеличить экономическую эффективность благодаря возможности быстрого выпуска с разными фичами. Обратной стороной этого достоинства является сложность настройки и администрирования, поскольку система работают одновременно с несколькими конфигурациями и наборами данных многих клиентов, каждый из которых фактически имеет дело со своим экземпляром виртуального приложения и видит только собственные ресурсы: конфигурацию и набор данных.
Технически реализовать мультиарендность можно несколькими способами:
- на уровне ядра с единым пулом ресурсов и единым хранилищем данных, одним развертыванием и разделение на программном уровне;
- на уровне инфраструктуры с единым хранилищем данных и развертыванием, но с разделением ресурсов. Каждый арендатор подключается к собственному серверу, используя гарантированные вычислительные мощности.
- без разделения, когда у каждого арендатора свое развертывание, хранилище и собственные ресурсы. По сути, этот вариант противоречит самой идее мультиарендности, т.к. каждый пользователь арендатор получает собственную копию приложения, которая отдельно поддерживается и сопровождается.
Для использования кластера Apache Kafka в мультиарендном режиме администратору необходимо выполнить следующие действия:
- создать пользовательские пространства (пространства имен) для арендаторов;
- настроить политики хранения данных в топиках;
- обеспечить защиту топиков и самого кластера с помощью шифрования, аутентификации и авторизации пользователей;
- изолировать арендаторов с помощью квот и ограничений;
- организовать мониторинг и учет системных метрик;
- настроить георепликацию между кластерами.
Далее рассмотрим, как это сделать.
6 этапов настройки мультиарендного кластера
Создание пользовательского пространства для каждого арендатора в мультиарендном кластере Kafka сводится к определению набора топиков, сгруппированных под управлением одного объекта или пользователя. Поскольку непосредственное переименование топиков не допускается, рекомендуется определять логические пространства на основе иерархической структуры их именования, включая средства обеспечения безопасности, такие как ACL-списки с префиксами, для изоляции различных пространств и клиентов. Напомним, топик Kafka – это логическое, а не физическое хранилище данных, поэтому эти пользовательские пространства можно определить по-разному. Например, привязать к команде, подразделению, проекту, продукту или бизнес-направлению. При этом не стоит размещать в названии топика информацию, которая может измениться со временем, технические метаданные, счетчики и параметры конфигурации. Для автоматизации процессов управления топиками можно использовать префиксы, например, команда А из проекта платежной системы может создавать только топики, названия которых начинаются с payments.teamA.
Чтобы обеспечить соблюдение строгих шаблонов именования топиков, следует определить политику создания топика (CreateTopicPolicy) с помощью параметра create.topic.policy.class.name. Отключите создание топиков для обычных пользователей можно, запретив это с помощью ACL-списков, автоматизировав этот процесс скриптами с проверкой согласно ранее заданным правилам. Также следует отключить функцию Kafka для автоматического создания топиков по требованию, задав параметру auto.create.topics.enable значение false в конфигурации брокера (auto.create.topics.enable=false).
Помимо этого следует определить параметры хранения данных в каждом топике, настроив конфигурации retention, о которых мы писали здесь. Также следует настроить шифрование данных, передаваемых между всеми узлами распределенной мультиарендной системы: брокерами и клиентами Kafka, узлами ZooKeeper и дополнительными инструментами, такими как средства логирования и мониторинга. Необходимо обеспечить аутентификацию подключений и авторизацию клиентских операций согласно ранее определенным политикам создания топиков и изменения их конфигураций с помощью create.topic.policy.class.name и alter.config.policy.class.name соответственно. Для настройки авторизаций, т.е. прав на выполнение определенных операций администратору кластера Kafka надо настроить ACL-списки доступа к топикам с шаблонами префиксов через флаг –resource-pattern-type Prefixed. Например, следующий набор команд предоставляет пользователю Anna из команды разработки BigDataSchool права на запись данных во все топики, названия которых начинаются с bidataschool.development, например, bidataschool.development.orders, bidataschool.development.events и пр.
$ bin/kafka-acls.sh \
--bootstrap-server BDSbroker:9092 \
--add --allow-principal User:Anna \
--producer \
--resource-pattern-type prefixed --topic bidataschool.development.
Аналогичный подход можно использовать для изоляции разных клиентов в одном общем кластере. Кроме того, мультиарендные кластеры Apache Kafka рекомендуется настраивать с помощью квот, чтобы избежать ситуации, когда некоторые арендаторы потребляют слишком много ресурсов, публикуя или потребляя очень большие объемы данных и чрезмерно часто обращаясь к брокерам. Kafka поддерживает различные типы клиентских квот, которые можно настроить для каждого пользователя. Например, квоты скорости запросов помогают ограничить влияние пользователя на использование ЦП брокера, ограничивая время обработки его запросов. Такое квотирование лучше ограничений входящей или исходящей пропускной способности сети. Также с помощью квоты controller_mutation_rate администратор кластера Kafka может ограничить количество операций с топиками, включая создание, удаление и изменение конфигурации, чтобы предотвратить перегрузку конкурирующими запросами. Кроме того, можно установить ограничение на скорость, с которой брокер принимает новые подключения, задать максимальное количество подключений на каждого брокера или определить максимальное количество разрешенных подключений с определенного IP-адреса. Подробнее про механизм квотирования в Apache Kafka мы ранее писали здесь.
В заключение отметим особенную важность мониторинга системных метрик для мультиарендной среды. Kafka отслеживает частоту неудачных попыток аутентификации, задержку запроса и потребителей, общее количество групп потребителей, показатели квот и другие важные показатели. Например, отслеживать размеры топика позволяет метрика JMX kafka.log.Log.Size. Также надо настроить оповещения, чтобы предупредить арендаторов о приближении к предельным значениям, например, при потреблении большого объема дискового пространства, поскольку Apache Kafka записывает данные на диск.
Наконец, для повышения надежности распределенной платформы потоковой обработки событий рекомендуется настроить георепликацию данных между ЦОДами в разных географических регионах. Эта задача сводится к межкластерному зеркалированию данных с помощью утилиты Mirror Maker 2. Еще одним вариантом управления мультипользовательским кластером Kafka с изоляцией данных между арендаторами является развертывание этой платформы потоковой передачи событий на Kubernetes. Для этого используется фреймворк Strimzi, о чем мы рассказываем в новой статье.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Администрирование Apache Kafka в Kubernetes
- Apache Kafka для инженеров данных
Источники