 685
685 
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей.
Что такое Databricks SQL
Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ данных с гибкостью и экономичностью озер данных. Подробнее о том, как она устроена, мы писали здесь и здесь. Databricks SQL описывает реляционное хранилище корпоративных данных, встроенное в платформу Databricks Lakehouse, которая предоставляет общие вычислительные ресурсы для бизнес-аналитики.
Платформа Databricks Lakehouse организует данные, хранящиеся в Delta Lake, в облачном объектном хранилище с помощью знакомых взаимосвязей, таких как схемы базы данных, таблицы и представления. Databricks рекомендует использовать многоуровневый подход к проверке, очистке и преобразованию данных для аналитики.
Databricks SQL предоставляет общие вычислительные ресурсы для SQL- запросов, визуализаций и панелей мониторинга, которые выполняются с таблицами в Lakehouse. В Databricks SQL эти запросы, визуализации и дэшборды разрабатываются и выполняются с помощью встроенного редактора SQL. Регулярно используемый код SQL можно сохранить в виде фрагментов для быстрого повторного использования, а результаты запросов можно кэшировать, чтобы сократить время выполнения. Кроме того, можно запланировать автоматическое обновление обновлений запросов, а также выдачу предупреждений при возникновении значимых изменений в данных. Databricks SQL также позволяет аналитикам анализировать данные с помощью визуализаций и дэшбордов с возможностью перетаскивания для быстрого специального исследовательского анализа.
Databricks SQL поддерживает три типа хранилищ, каждый из которых имеет разные уровни производительности и поддержки функций:
- Бессерверное хранилище поддерживает все функции хранилища SQL Pro, а также расширенные функции производительности Databricks SQL. Хранилища SQL запускаются в учетной записи Databricks клиента с использованием бессерверных вычислений. Хранилища SQL не поддерживают сквозную передачу учетных данных. Databricks рекомендует использовать Unity Catalog для управления данными, который обеспечивает централизованный контроль доступа, аудит, происхождение и возможности обнаружения данных в рабочих пространствах платформы.
- Хранилище Pro поддерживает дополнительные функции производительности Databricks SQL и все функции Databricks SQL.
- Классическое хранилище поддерживает функции производительности начального уровня и ограниченный набор функций Databricks SQL.
Как и в любом реляционном хранилище, Databricks SQL поддерживается кэширование — метод повышения производительности, позволяющий избежать необходимости многократного повторного вычисления или извлечения одних и тех же данных. В Databricks SQL кэширование может значительно ускорить выполнение запросов и минимизировать использование хранилища, что приводит к снижению затрат и более эффективному использованию ресурсов. Далее рассмотрим, как именно это работает.
Кэширование в Lakehouse: преимущества и принципы работы
Кэширование ускоряет выполнение запросов благодаря сохранению их результатов или часто используемых данных в памяти или других быстрых носителях. Это особенно полезно для повторяющихся запросов, поскольку система может быстро получать кэшированные результаты вместо их повторного вычисления. Кроме того, кэширование сводит к минимуму потребность в дополнительных вычислительных ресурсах за счет повторного использования ранее вычисленных результатов. Сокращение общего времени безотказной работы склада и потребности в дополнительных вычислительных кластерах, что приводит к экономии средств и улучшению качества ресурсов al__cpLocation.
Databricks SQL поддерживает несколько уровней кэширования:
- кэш пользовательского интерфейса для оптимизации взаимодействия с пользователем в GUI путем быстрого предоставления доступа к самым последним результатам запросов и информационной панели. Когда пользователи впервые открывают панель мониторинга или запрос SQL, в кэше отображается самый последний результат запроса, что снижает нагрузку на вычислительные ресурсы. Это приводит к сокращению времени отклика и более удобному использованию пользовательского интерфейса. Кэш пользовательского интерфейса важен для управления запланированными выполнениями. Когда запланировано обновление, в кэше сохраняются обновленные данные, гарантируя немедленный доступ к самой последней информации в дэшборде. Жизненный цикл кэша составляет не более 7 дней, и кэш становится недействительным после обновления базовых таблиц.
- кэширование результатов включает в себя локальный и удаленный кэш результатов, которые совместно повышают производительность запросов, сохраняя результаты запросов в памяти или на удаленных носителях данных. Локальный кэш находится в памяти, где сохраняются результаты запросов в течение всего срока службы кластера или при заполнении кэша, в зависимости от того, что наступит раньше. Этот кэш полезен для ускорения повторяющихся запросов, устраняя необходимость повторного вычисления одних и тех же результатов. Однако, после остановки или перезапуска кластера кэш очищается и все результаты запросов удаляются. Удаленный кэш результатов появился в в первом квартале 2023 года и представляет собой бессерверную систему кэширования, которая сохраняет результаты запросов, сохраняя их в облачном хранилище. Удаленный кэш результатов решает распространенную проблему кэширования результатов запросов в памяти, которая остается доступной только до тех пор, пока работают вычислительные ресурсы. Удаленный кэш является постоянным общим для всех хранилищ в рабочей области Databricks. Для доступа к удаленному кэшу требуется работающее хранилище. При обработке запроса кластер сначала просматривает свой локальный кэш, а затем при необходимости — удаленный. Только если результат запроса не кэшируется, он будет выполнен. Пока удаленный кэш результатов доступен для запросов с использованием клиентов ODBC/JDBC и API операторов SQL. Локальный и удаленный кэш после обновления базовых таблиц становится недействительным. В противном случае максимальный жизненный цикл локального и удаленного кэша составляет 24 часа, который начинается с момента записи в кэш.
- Дисковый кэш (дельта-кэш) предназначен для повышения производительности запросов за счет хранения данных на диске, что позволяет ускорить чтение данных. Данные автоматически кэшируются при извлечении файлов с использованием быстрого промежуточного формата. Сохраняя копии файлов в локальном хранилище, подключенном к вычислительным узлам, дисковый кэш обеспечивает расположение данных ближе к рабочим процессам, что приводит к повышению производительности запросов. Также дисковый кэш автоматически обнаруживает изменения в базовых файлах данных, гарантируя актуальность. Дисковый кэш имеет те же характеристики жизненного цикла, что и локальный кэш результатов, т.е. при остановке или перезапуске кластера кэш очищается и его необходимо заполнить заново.
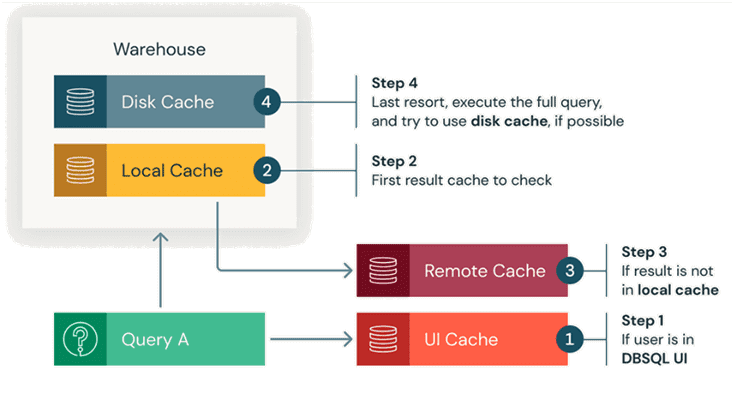
Все эти механизмы кэширования автоматически выделяются и управляются Databricks SQL на основе требований запроса и доступных ресурсов. Пользователю не нужно выполнять настройку вручную, но понимание типов кэширования может пригодиться для оптимизации производительности запросов и использование ресурсов.
Таким образом, кэширование в Databricks SQL может сильно улучшить производительность клиентов. Предлагая различные механизмы кэширования, такие как кэш пользовательского интерфейса, кэш результатов запросов и дисковый кэш, Databricks SQL гарантирует быструю и бесперебойную аналитику больших данных для своих клиентов.
Освойте администрирование и эксплуатацию Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

