 1056
1056 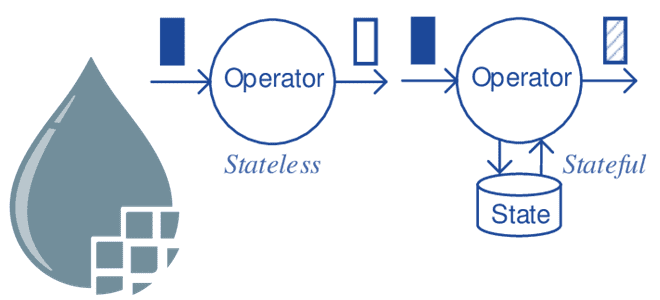
Чем Stateless-движок отличается от классического механизма потоковой обработки данных Apache NiFi, каковы его ключевые принципы работы и почему здесь особенно важна надежность источника.
Классический Apache NiFi: основные понятия
Приложение Apache NiFi можно рассматривать как два отдельных, но взаимосвязанных компонента: подлинности потока и его движок. Объединив их в одном приложении, NiFi позволяет дата-инженерам создавать поток данных и запускать его в режиме реального времени в одном пользовательском интерфейсе. Однако эти два понятия можно разделить. NiFi можно использовать для создания потоков, которые затем могут запускаться не только NiFi, но и другими совместимыми механизмами потоков данных: MiNiFi Java и C++ (подпроекты Apache NiFi) и NiFi Stateless. Каждый из этих механизмов потока данных имеет свои сильные и слабые стороны, обусловливающие их варианты использования.
Классический NiFi предназначен для запуска как большого многопользовательского приложения, поэтому стремится в полной мере использовать все предоставленные ему ресурсы, включая диски/хранилище и множество потоков. Обычно один экземпляр NiFi кластеризуется по множеству разных узлов, образуя большой связный поток данных, который может состоять из множества различных подпотоков. NiFi полностью отвечает за данные, которые ему доставляются: надежно хранит их на диске до тех пор, пока они не будут доставлены во все пункты назначения. Доставке этих данных может быть присвоен приоритет в разных точках потока, чтобы более важные для конкретного пункта назначения данные были доставлены туда прежде всего. Это обеспечивает целостное представление о том, как данные обрабатываются и проходят через все предприятие.
Однако, бывают сценарии, для которых можно использовать более легкое приложение, способное взаимодействовать со всеми различными конечными точками, с которыми может взаимодействовать NiFi, выполнять все преобразования, маршрутизацию, фильтрацию и обработку. Но при этом приложение работает с относительно небольшими потоками данных, которые не требуют сохранения состояния.
Напомним, основной концепцией в NiFi является FlowFile – информационный объект, который движется по потоку данных и состоит из атрибутов и содержимого. В классическом фреймворке каждый узел имеет набор внутренних репозиториев, которые хранятся на локальном диске. Репозиторий FlowFile содержит состояние каждого потокового файла, включая его атрибуты и расположение в потоке, а репозиторий содержимого хранит его содержимое. Подробнее про репозитории NiFi мы писали здесь. При каждом выполнении процессора дается ссылка на сеанс, который действует как транзакция для работы с FlowFile. Если все операции завершены успешно и сеанс зафиксирован, все обновления сохраняются в репозиториях NiFi. В случае перезапуска приложения все данные сохраняются в репозиториях, и поток начнет обработку с последнего зафиксированного состояния. В Stateless-движке подобное сохранение не обеспечивается. Как это работает, рассмотрим далее.
Stateless-движок: основные принципы работы
Многие концепции в Stateless-движка отличаются от концепций типичного движка Apache NiFi. Stateless обеспечивает механизм потока данных с меньшим размером. Он не включает пользовательский интерфейс для создания или мониторинга потоков данных, а вместо этого запускает потоки данных, созданные с помощью приложения NiFi. Хотя NiFi работает лучше всего при наличии доступа к быстрому хранилищу, такому как SSD и диски NVMe, Stateless может хранить все данные в памяти. В качестве альтернативы используется дисковый репозиторий для содержимого FlowFile, чтобы избежать необходимости использования очень больших куч Java. Однако, как и следует из названия, Stateless не сохраняет состояние. Поэтому данные не будут восстановлены после перезапуска: если Stateless-механизм будет остановлен, у него больше не будет прямого доступа к данным, которые находились в процессе передачи. Таким образом, Stateless можно использовать только для потоков данных, где источник данных является одновременно надежным и воспроизводимым, или в сценариях, где потеря данных не является критической проблемой. Например, чтение данных из Apache Kafka или JMS-брокеров, а затем выполнение некоторой маршрутизации/фильтрации/манипулирования и, наконец, доставка данных в другое место назначения. Если запускать такой поток данных в классическом NiFi, данные потребляются из источника, записываются во внутренние репозитории и попадают под ответственность NiFi, который будет отвечать за доставку по всем пунктам назначения, даже при перезапуске приложения. В случае с Stateless данные будут потребляться, а затем передаваться следующему процессору в потоке. Данные не записываются во внутренние репозитории и передаются следующим процессорам по потоку. Данные, полученные от источника, будут подтверждены только после того, как они достигнут конца всего потокового конвейера. Если Stateless перезапускается до завершения обработки, данные не подтверждены, а потому используются снова. Это позволяет обрабатывать данные в памяти, не опасаясь потери данных, но также возлагает на источник данных ответственность за их надежное хранение и обеспечение возможности их воспроизведения.
Stateless-движок придерживается того же API-интерфейса, что и классический фреймворк, позволяя работать с теми же процессорами и определениями потоков, но обеспечивает другую реализацию базового движка. Для этого в Stateless есть объект StatelessDataFlow, запускаемый для выполнения потока. Каждое выполнение потока дает результат, который можно считать успешным или неудачным. Сбой может произойти из-за того, что процессор выдает исключение, или из-за явной маршрутизации файлов потока на поименованный порт сбоя. Ключевое отличие Stateless-движка заключается в фиксации сеанса NiFi с помощью метода ProcessSession с сигнатурой void commitAsync(Runnable onSuccess). Это дает реализации сеанса контроль над тем, когда выполнять данный обратный вызов. В классическом NiFi сеанс может выполнить обратный вызов на последнем этапе commitAsync(), обеспечивая сохранность данных при перезапуске даже без фиксации того, что они достигли конечной точки потокового конвейера. Сеанс NiFi Stateless может удерживать обратный вызов и выполнять его только после успешного завершения всего потока.
Еще в выпуске 1.15.0 был представлен процессор ExecuteStateless для запуска движка Stateless из классического NiFi. Это позволяет управлять выполнением потока без сохранения состояния с помощью традиционного пользовательского интерфейса фреймворка, а также подключать выход Stateless-потока для последующей обработки в классическом потоке NiFi.
Чтобы использовать процессор ExecuteStateless, следует сначала в классическом NiFi создать группу процессов, содержащую поток, который надо выполнить с помощью Stateless-механизма. Затем надо загрузить определение потока или зафиксировать его в экземпляре реестра NiFi, а потом настроить для процессора ExecuteStateless местоположение определения потока.
Stateless-механизм можно использовать в качестве библиотеки и встраивать в другие приложения, а также запустить непосредственно из командной строки из сборки NiFi с помощью скрипта bin/nifi.sh. Для этого необходимы три файла: файл свойств конфигурации механизма, файл свойств конфигурации потока данных и сам поток данных, который может существовать в виде файла или указывать на поток в реестре NiFi. Stateless-движок принимает два отдельных файла конфигурации: файл конфигурации механизма и файл конфигурации потока данных, поскольку обычно конфигурация механизма одинакова для всех выполняемых потоков, поэтому ее можно создать только один раз. А вот конфигурация потока данных будет отличаться для каждого потока данных, который необходимо запустить.
Ключевым аспектом NiFi является разделение платформы и расширений, работающих с данными, поэтому должен быть механизм определения расположения этих расширений. При запуске Stateless-движка он анализирует предоставленный поток данных и определяет, какие пакеты/расширения необходимы для запуска потока данных. Если расширение недоступно или версия, на которую ссылается поток, недоступна, Stateless пытается загрузить расширения автоматически, используя предварительно настроенные клиенты расширения или те расширения, которые уже доступны, например, загружены вручную и скопированы в автономном режиме в каталогах, указанных в свойствах nifi.stateless.extensions.directory и nifi.stateless.readonly.extensions.directory.<suffix>
Конфигурация потока данных предоставляет Stateless-движку всю информацию о том, какой поток запускать. Местоположение потока указывается в URL-адресе реестра NiFi, идентификаторе сегмента и идентификаторе потока или в JSON-определении потока. На практике проще всего экспортировать поток из NiFi на локальный диск для использования Stateless-движком в GUI, через контекстное меню группы процессов или загрузить поток сразу на холст.
Разобравшись с основными принципами работы Stateless-движка, в следующей статье рассмотрим, его особенности и ограничения. А здесь вы узнаете, почему этот движок подходит только для работы с надежными и транзакционными источниками данных.
Узнайте больше про администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

