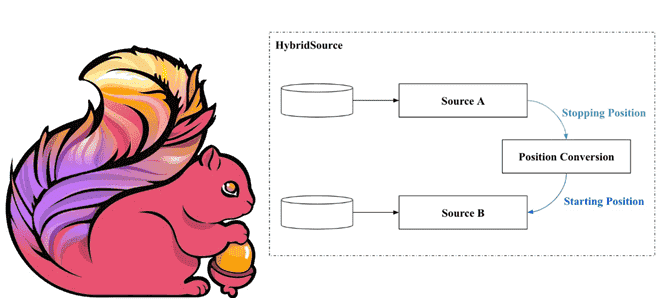
Как задание Apache Flink может читать информацию из разных источников данных в одном потоке. Что такое HybridSource и как с ним работать: разбираем на примере файла и топика Kafka. Что такое гибридный источник данных Иногда заданию Flink необходимо считывать данные из нескольких источников в последовательном порядке. Напомним, источником данных для...

23 октября 2024 года опубликован предварительный выпуск Apache Flink. Знакомимся с самыми яркими новинками этого мажорного релиза: удаленные API, коннекторы и конфигурации, динамическая оптимизация логических планов, а также дизагрегированное состояние и управление им. Критические изменения: удаление устаревших компонентов Начнем с критических изменений, связанных с удалением устаревших компонентов. В Apache Flink...
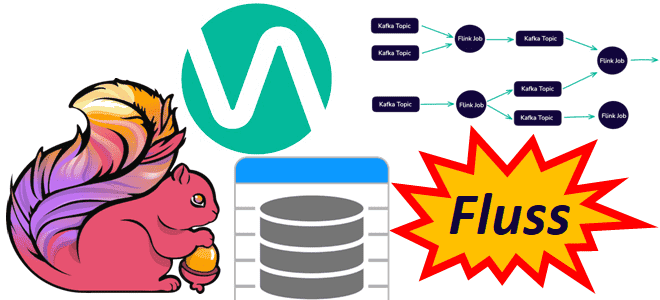
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data. Что не так с архитектурой конвейеров обработки данных...
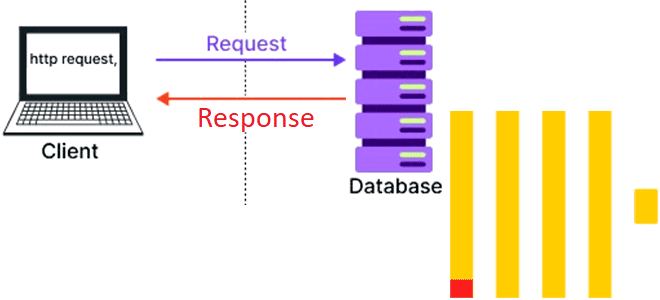
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....

Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...
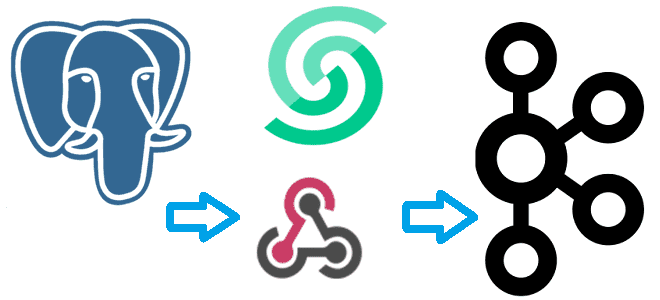
Что такое вебхук и как отправить событие из PostgreSQL в Apache Kafka, используя API Webhook на платформе Upstash. NoCode-интеграция БД и брокера сообщений: практический пример. Практический пример: CDC из PostgreSQL в Kafka через веб-хуки Веб-хук или перехватчик – это настраиваемый обратный HTTP-вызов из одной системы к другой. Он используется для...
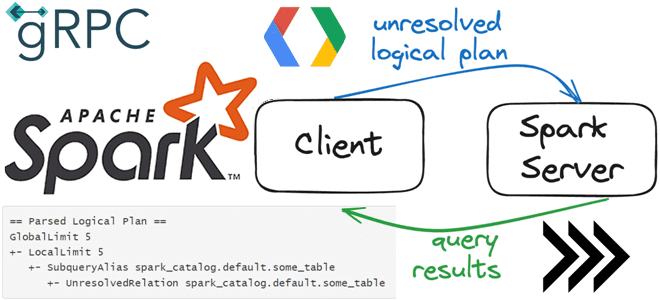
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...
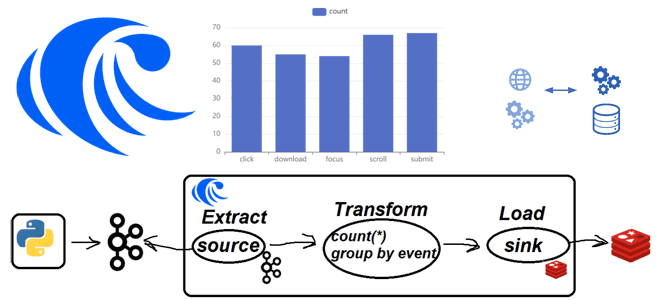
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций. Постановка задачи Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так...
Архитектура Data Lake: что не так с потоковыми обновлениями данных в Data Lake, как Apache Iceberg реализует эти операции и почему Upsolver решили улучшить этот формат Проблема потоковых обновлений в Data Lake и 2 подхода к ее решению Считается, что озеро данных (Data Lake) предлагают доступное и гибкое хранилище, позволяющее...
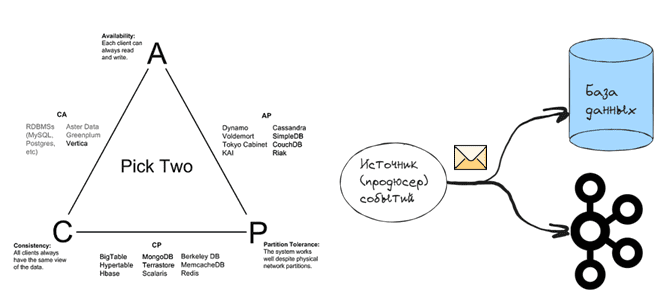
Проклятье CAP-теоремы: проблема целостности данных в распределенной системе и варианты ее решения. 3 шаблона проектирования микросервисной EDA-архитектуры на Apache Kafka: transactional outbox, Event Sourcing и listen to yourself. Что такое проблема двойной записи в распределенных гетерогенных системах Согласно CAP-теореме, распределенная система в любой момент времени обеспечивает выполнение только 2-х требований...