 673
673 
Содержание
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data.
Что не так с архитектурой конвейеров обработки данных на Apache Flink и Kafka
Чтобы совмещать обработку данных в реальном времени с историческими данными, например, в конвейерах расширенной аналитики или машинном обучении, необходима соответствующая архитектура. Именно поэтому возникли такие подходы, как Data LakeHouse, которые можно рассматривать как гибрид традиционного DWH и Data Lake. Однако, чтобы реализовать этот архитектурный подход, требуется довольно много инструментов и промежуточных слоев. Немецкая компания Ververica, которая продвигает и коммерциализирует Apache Flink предлагает оптимизировать инструментальный ландшафт, реализовав LakeHouse новое потоковое хранилище для Flink-приложений обработки данных. Fluss бесшовно поддерживает обработку данных в реальном времени и исторические данные, устраняя необходимость в промежуточных топиках Kafka и инструментах потоковой обработки.
Flink-приложения часто развертываются вместе с потоковым уровнем хранения, таким как Apache Kafka, и сочетаются с OLAP-системами аналитической обработки в реальном времени, такими как Clickhouse. Это позволяет создавать архитектуры данных, ориентированные на потоковую передачу, которые обрабатывают все входящие данные как неограниченные потоки, с возможностью обработки и анализа данных по мере их поступления.
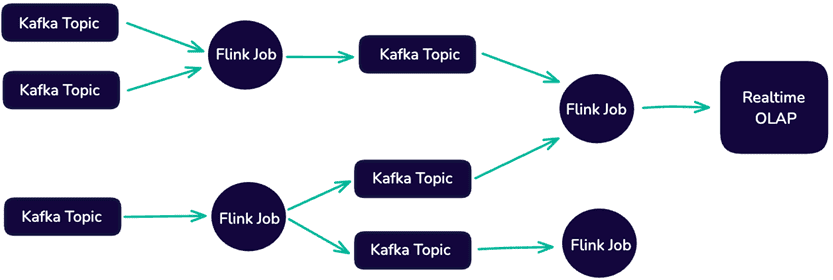
Apache Kafka играет центральную роль в таких архитектурах, выступая в качестве основы для хранения и передачи данных в реальном времени. Высокая пропускная способность, отказоустойчивость и масштабируемость Kafka обусловливают ее популярность для создания крупномасштабных конвейеров данных в реальном времени, в т.ч. с помощью заданий Flink. Универсальная архитектура Flink позволяет обрабатывать непрерывные потоки данных в событийно-управляемых приложениях с минимальной задержкой, включая stateful-вычисления, аналитическая обработка и агрегации в реальном времени. Это востребовано в задачах обнаружения мошенничества, формирования персонализированных рекомендаций, систем мониторинга и т.д.
Будучи распределенным append-only логом, журналы Kafka отлично работают как временное хранилище строковых данных. Однако, для сложной потоковой аналитики в реальном времени этого недостаточно по следующим причинам:
- Отсутствие обновлений и вставок. Upsert-операции часто встречаются в реальной жизни. Kafka изначально не поддерживает upsert-операции так, как того требуют потоковые процессоры Flink. Apache Flink необходимо генерировать журналы изменений для отслеживания обновлений, что может привести к задержке и сложности для обеспечения согласованности состояния. Это приводит к проблемам с корректностью результатов и более медленной обработке, особенно для крупномасштабных или высокопроизводительных систем.
- Отсутствие прямых запросов без дополнительных уровней инфраструктуры, таких как топики и коннекторы. Это усложняет обработку данных в реальном времени, поскольку требует перемещения данных во внешнюю систему, такую как хранилище или озеро данных, для выполнения сложных запросов и аналитики. Возникает необходимость хранения промежуточных результатов в соответствующих топиках Kafka, что приводит к росту фактических затрат на инфраструктуру.
- Длительная обработка исторических данных: для проведения исторического анализа данных в Kafka необходимо считывать данные из лога с какого-то смещения или момента времени, фактически воспроизводя целый журнал. Это отнимает много времени и требует больших вычислительных затрат, а также повышает сложность отладки.
- Высокие сетевые затраты – как мы уже отмечали здесь, расходы на передачу данных между узлами кластера Kafka являются основным источником затрат. Распределенная архитектура этой платформы потоковой передачи событий требует интенсивного перемещения данных по сетям, что приводит к значительным затратам на инфраструктуру и узким местам в производительности, особенно при масштабной аналитики в реальном времени.
Как фреймворк для разработки распределенных stateful-приложений Apache Flink использует RocksDB для хранения состояния, но ему не хватает надежного уровня хранения потоковых данных, который напоминает хранилище, будучи нативным для Flink. Поэтому Ververica разработала Fluss – потоковое хранилище для аналитики данных в реальном времени. Что это такое и как работает, рассмотрим далее.
Fluss как универсальное хранилище потоковых данных
Fluss – это специальный слой хранения, оптимизированный для потоковой обработки. Ключевыми возможностями Fluss как унифицированного уровня потокового хранения являются следующие:
- Низкая задержка (менее секунды) — Fluss обеспечивает быструю потоковую передачу данных, позволяя выполнять операции чтения и записи практически немедленно. Это идеально подходит для приложений, чувствительных ко времени, таких как мониторинг и финансовые платформы, поскольку доставляет данные сразу после их получения.
- Обновления и журналы изменений — Fluss поддерживает дуальность потоков и таблиц Flink, что позволяет проводить эффективные обновления с журналами изменений. Это обеспечивает согласованный поток данных, предоставляя полную видимость изменений потоков для точного анализа в реальном времени и исторических данных в рамках одной системы.
- Специальные интерактивные запросы – Fluss позволяет запрашивать данные напрямую данных без дополнительных слоев обработки. Это снижает сложность проектирования и реализации, упрощает отладку и обеспечивает немедленный доступ к данных в реальном времени.
- Унифицированная пакетная обработка и потоковая передача позволяет эффективно обрабатывать исторические данные вместе с информацией в реальном времени, оптимизируя инфраструктуру для рабочих нагрузок ИИ, машинного обучения и расширенной аналитики Big Data.
- Проекция Pushdown для оптимизации потоковых чтений извлекает только необходимые поля для запросов. Это сокращает передачу данных, повышая производительность в десятки раз и снижая сетевые расходы.
- Колоночные потоковые чтения и хранение данных. Это улучшает сжатие и ускоряет аналитику больших объемов данных в реальном времени.
Fluss также предоставляет многоуровневое хранилище в стиле колоночных форматов хранения данных для LakeHouse типа Apache Paimon или Iceberg, позволяя потоковому заданию загружать состояние из пакетных источников, что обеспечивает бесшовную инициализацию состояния и синхронизацию между пакетной и потоковой обработкой.
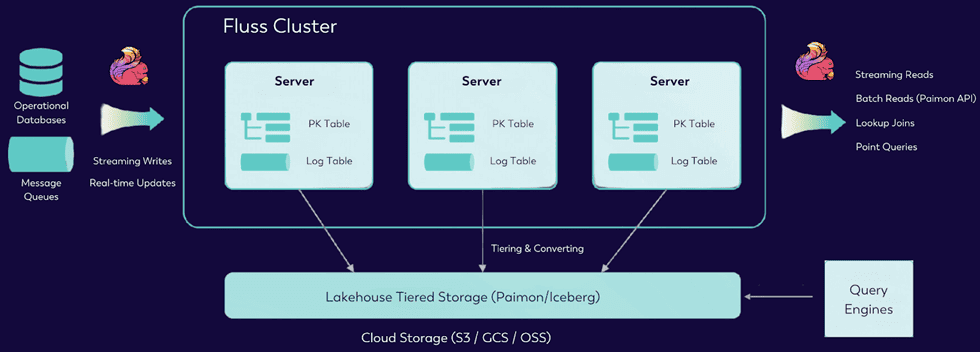
В ближайшем будущем (до конца 2024 года) Ververica планирует открыть код Fluss и передать его в Apache Software Foundation.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

