Как задание Apache Flink может читать информацию из разных источников данных в одном потоке. Что такое HybridSource и как с ним работать: разбираем на примере файла и топика Kafka.
Что такое гибридный источник данных
Иногда заданию Flink необходимо считывать данные из нескольких источников в последовательном порядке. Напомним, источником данных для Flink могут быть реляционные или нереляционные базы, файловые системы или топики Apache Kafka. Вообще источник данных в Apache Flink состоит из трех основных компонентов: Split, SplitEnumerator и SourceReader. Splits — это часть данных, используемых источником, например, файл или раздел лога. Это степень детализации, с которой источник распределяет работу и распараллеливает чтение данных. SourceReader запрашивает разделения и обрабатывает их, например, читая файл или раздел лога. Считыватели источника работают параллельно с диспетчерами задач и создают параллельный поток событий/записей. SplitEnumerator генерирует разделения и назначает их считывателям источника. Он работает как отдельный экземпляр в Диспетчере заданий и отвечает за сохранение незавершенных операций разделения и их сбалансированное назначение читателям. Подробнее об этом мы писали здесь.
Возвращаясь к гибридным источникам, рассмотрим примеры сценариев, когда они нужны. Например, чтобы собрать данных об изменениях или заполнить значения фичей для машинного обучения. Пользователи могут хранить снимок в HDFS/S3 и логировать изменения в базе данных binlog или Kafka. А когда в ML-модель добавляется новый признак, его необходимо вычислить на основе необработанных данных за несколько месяцев до настоящего момента. Обычно исторические данные и данные в реальном времени хранятся в разных системах хранения, например, HDFS и Kafka соответственно. До версии Flink 1.14 дата-инженеру приходилось запускать два разных задания Flink, создавать свой источник данных или использовать SourceFunction. Однако, это не так просто, поскольку переключаться между несколькими источниками данных ограничено разными коннекторами. Кроме того, важно контролировать конкретное состояние вышестоящего источника перед переключением и то, как нижестоящий источник преобразует состояние.
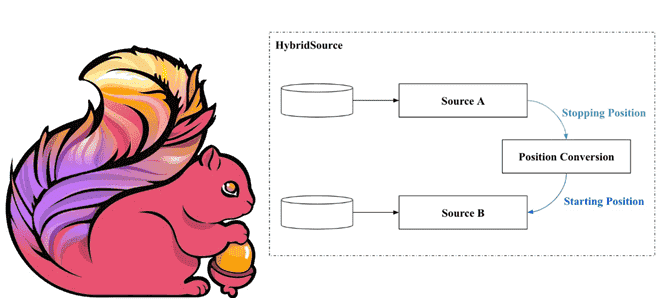
Чтобы реализовать это, нужно автоматически переключать источники данных, обеспечивая их целостность и согласованность. Для этого в Apache Flink 1.14 введен API гибридного источника (Hybrid Source) поверх API Source. Он позволяет повторно использовать существующие Source-коннекторы и поддерживает пользовательские комбинации источников данных. Гибридный источник включает несколько источников и считывает данные каждого из них в определенном порядке. Он переключается с одного источника на следующий, когда первый заканчивается. Таким образом, с точки зрения пользователя, все источники действуют как один.
Чтобы организовать несколько источников в HybridSource, все источники, кроме последнего, должны быть ограничены. Поэтому источникам обычно необходимо назначить начальную и конечную позицию. Последний источник может быть ограничен, в этом случае HybridSourceограничен и не ограничен в противном случае. Детали зависят от конкретного источника и внешних систем хранения.
Чтобы понять, как это работает, рассмотрим небольшой пример чтения исходных данных из файла до предопределенного момента времени (14:48 по UTC 5 октября 2024 года), а затем продолжение чтения из Kafka. Каждый источник данных содержит заранее известный диапазон. Поэтому источники данных могут быть созданы заранее, как если бы они использовались напрямую. Например, на Python это выглядит так:
switch_timestamp = ‘2024-10-05T14:48:00Z’
file_source = FileSource \
.for_record_stream_format(StreamFormat.text_line_format(), test_dir) \
.build()
kafka_source = KafkaSource \
.builder() \
.set_bootstrap_servers('localhost:9092') \
.set_group_id('MY_GROUP') \
.set_topics('quickstart-events') \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_starting_offsets(KafkaOffsetsInitializer.timestamp(switch_timestamp)) \
.build()
hybrid_source = HybridSource.builder(file_source).add_source(kafka_source).build()
Экземпляр класса HybridSource создаёт гибридный источник данных, начиная с файла и добавляя к нему топик Kafka. Базовая реализация гибридного источника переключает базовые источники на основе настроенной цепочки источников, созданной из HybridSourceBuilder. HybridSourceBuilder добавляет источник с отложенным созданием экземпляра на основе предыдущего перечислителя для построения цепочки источников через SourceFactory для базовых источников гибридного источника. SourceFactory позволяет строить источник во время построения направленного ациклического графа или откладывать во время переключения и предоставляет возможность устанавливать начальную позицию способом, разрешенным определенным источником. Когда текущий перечислитель завершается, SourceFactory создает следующий источник из предыдущего перечислителя до того, как будет создан следующий перечислитель, и требуется только для динамической передачи позиции во время переключения. Таким образом, конечное состояние разделенного перечислителя используется для установки начальной позиции следующего источника.
Динамическое переключение между источниками данных Apache Flink
Однако, иногда нужно динамически переключать начальную позицию считывания данных во время выполнения. Например, файловый источник данных очень большой, и его считывание может занять больше времени, чем доступное для следующего источника удержание. Переключение должно произойти в определенный момент. Для этого нужно, чтобы время начала для следующего источника было установлено во время переключения. Здесь требуется передача конечной позиции из предыдущего перечислителя файлового источника для отложенного построения KafkaSource путем реализации SourceFactory. Перечислители должны поддерживать получение конечной временной метки. Python API это не поддерживает, а код на Java выглядит так:
FileSource<String> fileSource = CustomFileSource.readTillOneDayFromLatest();
HybridSource<String> hybridSource =
HybridSource.<String, CustomFileSplitEnumerator>builder(fileSource)
.addSource(
switchContext -> {
CustomFileSplitEnumerator previousEnumerator =
switchContext.getPreviousEnumerator();
long switchTimestamp = previousEnumerator.getEndTimestamp();
KafkaSource<String> kafkaSource =
KafkaSource.<String>builder()
.setStartingOffsets(OffsetsInitializer.timestamp(switchTimestamp + 1))
.build();
return kafkaSource;
},
Boundedness.CONTINUOUS_UNBOUNDED)
.build();
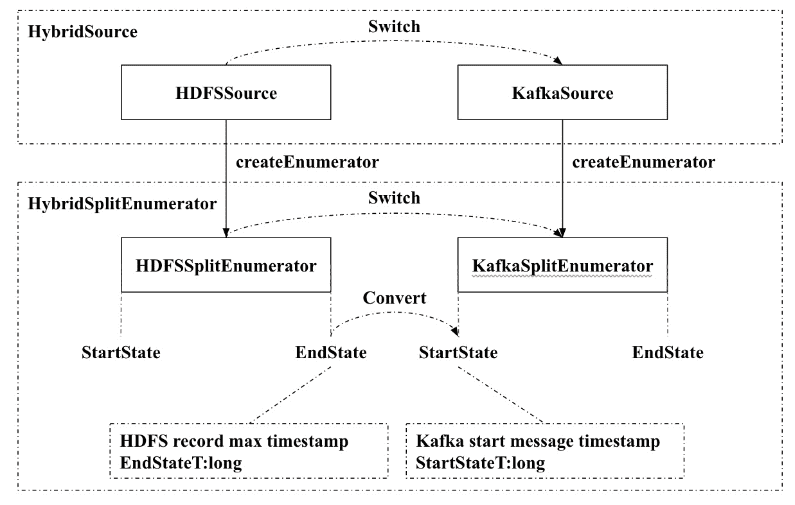
Сперва создается источник данных fileSource, который считывает из файла данные за последний день. Как только все данные из файла будут прочитаны, добавляется новый источник данных. Каким он будет, определяется через лямбда-функцию, внутри которой возвращается предыдущий перечислитель (enumerator) с информацией о ранее прочитанном файле. Также в этой лямбда-функции извлекается конечная отметка времени по данным, ранее считанным из файла. Поскольку гибридный источник после файла считывает данные из Kafka, начиная с последнего момента времени, надо указать, что топик Kafka будет непрерывным и неограниченным. Это делается с помощью параметра Boundedness.CONTINUOUS_UNBOUNDED.
Когда используется файловый источник FileSource, FileSplitEnumerator берет максимальную временную метку записей файла в качестве возвращаемого значения метода getEndState(), которое рассматривается как конечная позиция END_POSITION файлового источника. Когда в качестве источника данных используется Kafka, KafkaSplitEnumerator берет максимальную временную метку вышестоящего источника в качестве значения параметра метода setStartState(), которое считается начальной позицией START_POSITION потребителя Kafka.
Таким образом, гибридный источник данных в Apache Flink позволяет считывать информацию из разных мест, комбинируя пакетную и потоковую обработку. Это удобно при реализации лямбда-архитектуры данных для анализа исторической информации с данными, поступающими в реальном времени. Однако, когда критически обработка данных в реальном времени, т.е. без задержек, гибридные источники могут ввести дополнительные задержки из-за необходимости согласования и обработки данных из различных источников.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

