455
455 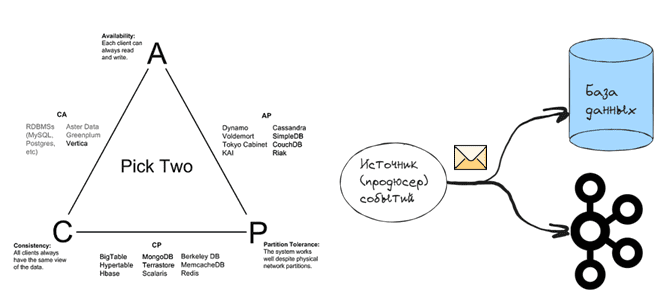
Содержание
Проклятье CAP-теоремы: проблема целостности данных в распределенной системе и варианты ее решения. 3 шаблона проектирования микросервисной EDA-архитектуры на Apache Kafka: transactional outbox, Event Sourcing и listen to yourself.
Что такое проблема двойной записи в распределенных гетерогенных системах
Согласно CAP-теореме, распределенная система в любой момент времени обеспечивает выполнение только 2-х требований из 3-х, например, целостность (Consistency) данных и доступность операций чтения и записи (Availability) или целостность и устойчивость системы к разделению (Partition Tolerance), или доступность и устойчивость к разделению. Несмотря на критику CAP-теоремы, о которой мы писали здесь, эта концепция хорошо описывает ключевую особенность распределенных систем: консистентность, т.е. целостность данных, расположенных на разных узлах, достигается не мгновенно. Если речь идет про гомогенную информационную систему, например, базу данных, развернутую в кластере для повышения надежности с репликацией записей по нескольким узлам, или брокеры в кластере Apache Kafka, консистентность обычно обеспечивается внутренними механизмами этой системы. Например, в Kafka это реализуется репликацией сообщений с брокера-лидера раздела на брокеры-подписчики. В распределенных СУБД с централизованной топологией, т.е. одним ведущим узлом, например, ClickHouse и Greenplum записи реплицируются с мастер-узла на другие машины кластера. А в СУБД с кольцевой топологией, таких как Cassandra, записи распространяются по кольцу от одного узла к другому.
Чтобы избежать неконсистентности данных, в Apache Kafka есть параметр ack у продюсера, установка которого в значение all означает необходимость ожидания подтверждения об успешной репликации сообщений, опубликованного в брокере-лидере раздела по всем брокерам-подписчикам, перед отправкой нового пакета данных. Это повышает надежность потокового конвейера, но снижает его быстродействие. В случае баз данных репликация изменений с мастер-узла или их распространение по кольцу тоже занимает какое-то время. Именно поэтому о NoSQL-СУБД часто говорят, что они обеспечивают согласованность в конечном счете (eventual consistency). Подробнее о дилемме CAP-теоремы в Apache Kafka читайте в новой статье.
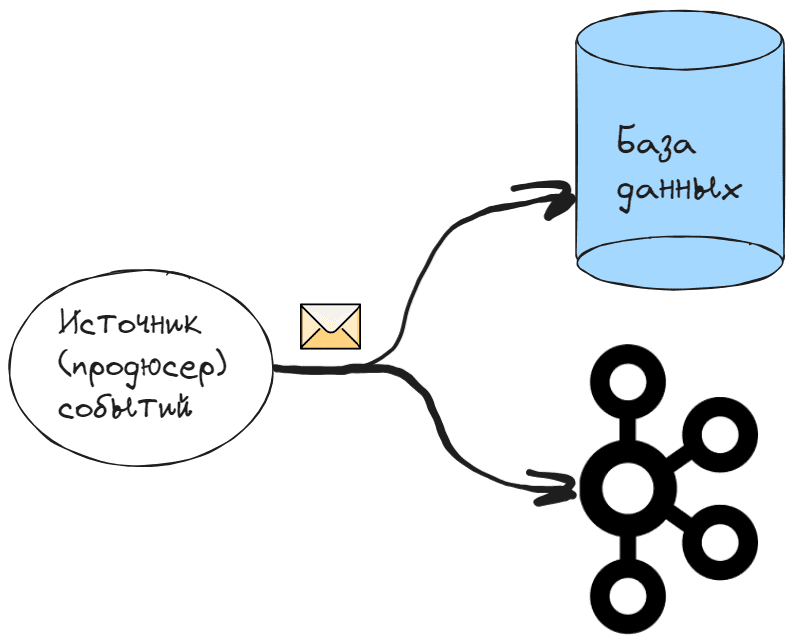
На самом деле проблема консистентности свойственна не только нереляционным хранилищам данных, а любым распределенным системам. А в гетерогенных системах, т.е. реализованных с использованием разных технологий, эта проблема возникает особенно остро, приобретая разные интерпретации. Одной из них является проблема двойной записи, когда две отдельные системы необходимо обновить атомарно, при этом успешно завершается только одна из этих операций.
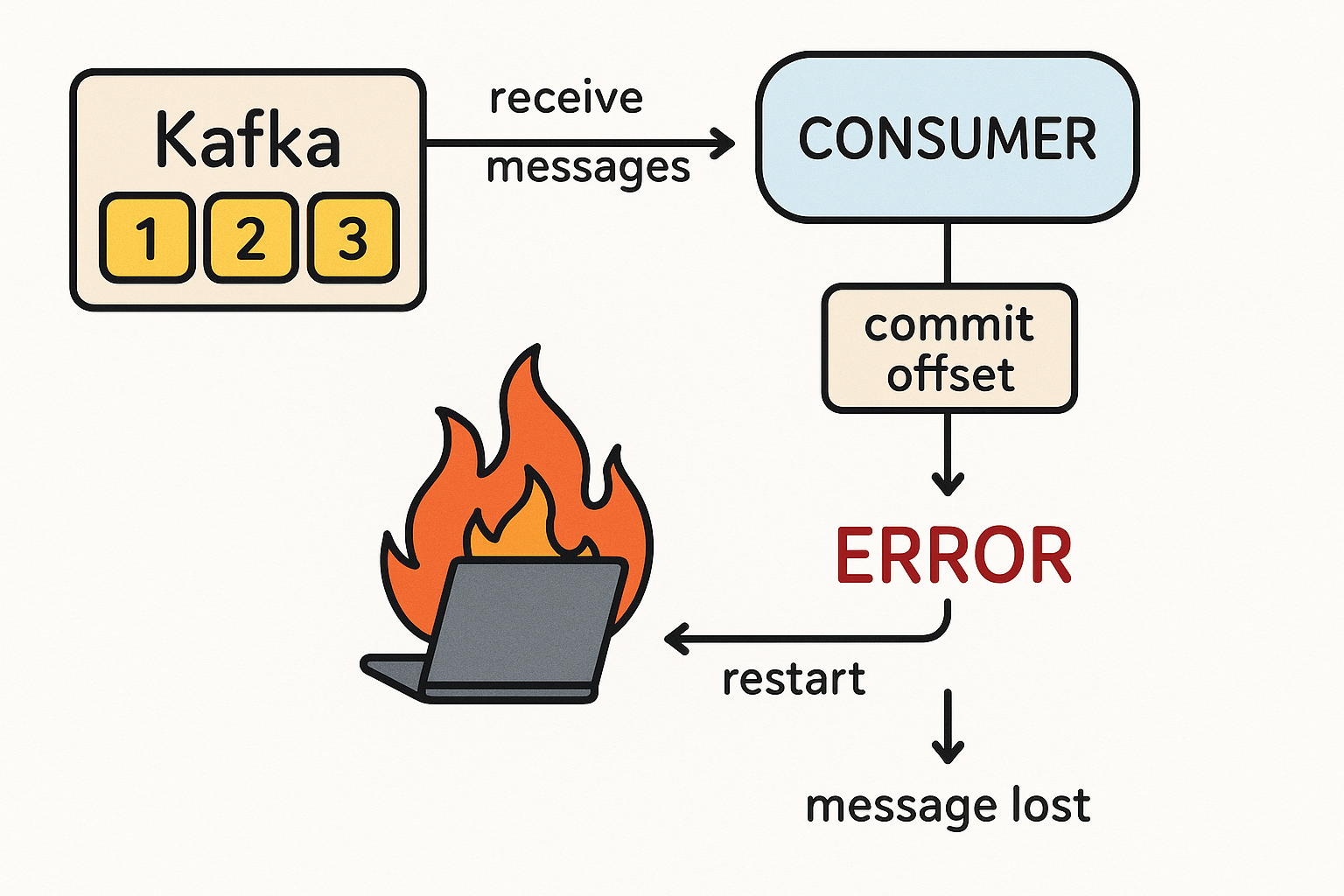
Например, нужно отразить некоторое событие в Kafka и в базе данных. Если обновление базы данных завершается успешно, но событие в Kafka не опубликовано, система окажется в несогласованном состоянии. Проблема возникает между сохранением в базе данных и отправкой события. Если сбой произошел после того, как данные были сохранены, но до того, как событие попадет в Kafka, система окажется в несогласованном состоянии: изменения будут отражены в базе данных, но событие об этом будет потеряно.
3 простых варианта решения, которые не работают
Самым простым решением проблемы несогласованности данных в БД и в Kafka кажется изменение порядка записи. Можно сперва опубликовать событие в Kafka, а затем сохранить в базе данных. Но сбой может произойти при попытке обновления базы данных, что тоже приведет к рассогласованию, т.к. событие в Kafka уже опубликовано и удалить его оттуда нельзя. Поэтому изменение порядка операций не решит проблему, поскольку нужно обеспечить атомарность записи данных в 2 разные системы, независимо от порядка их выполнения. Поскольку обе операции должны завершиться успешно или считаются невыполненными, если хотя бы одна из них потерпит сбой, их являются транзакционными. А базы данных отлично решают задачи транзакционных операций. Однако, даже если объединить запись в базу и в Kafka в одну транзакцию базы данных, это не решит проблему, т.к. сбой может произойти после создания события, но до фиксации транзакции. Это снова приведет к опубликованному в Kafka событию без его отражения в базе данных, т.е. неконсистентной системе.
Еще одной альтернативой является использование механизма повтора с ожиданием подтверждений об успешной записи в Kafka. Если публикация сообщений завершилась сбоем, ее можно повторять до тех пор, пока она не завершится успешно. Однако, это предполагает наличие в системе знаний о том, что именно следует повторить. Если проблема связана с временной сетевой ошибкой, потерявшееся событие может храниться в памяти, и будет отправлено повторно. Но если приложение-продюсер, т.е. источник событий вышло из строя, все данные, которые хранились в его оперативной памяти, будут потеряны. Поэтому механизм повтора требует записи события в долговременное хранилище, чтобы его можно было получить в случае сбоя системы. Однако, это приводит к еще одной записи, усложняя систему и не устраняя проблему. Таким образом, изменение порядка операций, транзакции в БД и повторная публикация будут, скорее антипаттернами для решения проблемы двойной записи. А подходящим шаблоном может стать transactional outbox, о котором мы поговорим далее.
Паттерны проектирования микросервисной архитектуры и Apache Kafka для решения проблемы двойной записи
Ключевым моментом является разделение двух операций записи и введение зависимости между ними. Первая запись выполняется независимо от второй, а потом запускает отдельный процесс, который постоянно повторяет вторую попытку, пока она не увенчается успехом. Если первая запись завершается неудачей, вторая никогда не запускается. И только после успеха первой операции выполняется вторая. Для этого можно использовать паттерн проектирования микросервисной архитектуры под названием шаблон транзакционных исходящих сообщений (transactional outbox). Он использует транзакции базы данных и механизм повторных попыток. Транзакции базы данных обеспечивают атомарную запись между двумя таблицами, откуда отдельный процесс использует исходящие сообщения и обновляет внешнюю систему по мере необходимости. Этот процесс можно написать вручную или использовать такие CDC-инструменты типа Debezium или коннекторы Kafka, о чем я писала здесь и здесь на примере практической реализации потоковой репликации событий из PostgreSQL в Elasticsearch.
Для реализации этого шаблона в базе данных создается таблица исходящих сообщений, куда записываются события, которые необходимо доставить в Kafka. Поскольку обе операции записи выполняются в одну и ту же базу данных, это можно выполнить транзакционно для обеспечения атомарности. Такой прием гарантирует, что каждое обновление базы данных будет иметь соответствующее событие в таблице исходящих сообщений. А чтобы опубликовать события в Kafka, надо написать потребитель или настроить коннектор, который будет считывать события из таблицы исходящих сообщений и публиковать в Kafka, повторяя попытку в случае сбоя. После успешной публикации события в Kafka, оно помечается как завершенное и даже может быть удалено из таблицы исходящих сообщений.
Паттерн transactional outbox отлично решает проблему двойной записи, но он имеет существенное ограничение: база данных должна поддерживать транзакции. Если хранилище не поддерживает транзакции, можно применить альтернативный микросервисный паттерн – источник событий (Event Sourcing). Это шаблон хранения состояния объекта в виде серии событий. Каждый раз, когда объект обновляется, новое событие записывается в лог, доступный только для добавления. Когда объект загружается из базы данных, события воспроизводятся по порядку, повторно применяя необходимые изменения. Преимущество этого подхода в том, что он сохраняет полную историю объекта. Это полезно для отладки, аудита и создания новых моделей, а также для решения проблемы двойной записи в системах с архитектурами, управляемыми событиями (EDA, Event Driven Architecture).
Как и transactional outbox, в паттерне Event Sourcing, отдельный процесс CDC-коннектор считывает события из БД и отправляет их в Kafka. Однако, эти события никогда не удаляются из источника, а только специальный флаг указывает на то, было ли событие опубликовано. Модификацией паттерна Event Sourcing является шаблон Слушай себя (listen to yourself), который реализуется путем отправки микросервисом события в брокер сообщений, т.е. Apache Kafka, а затем использует эти события для выполнения внутренних обновлений. В отличие от Event Sourcing, который записывает событие в базу данных и позже публикует его в Kafka, шаблон listen to yourself сразу записывает события непосредственно в Kafka. Порядок операций меняется: сперва в Kafka публикуется событие, а затем оно прослушивается, чтобы изменить состояние базы данных. Это решает проблему согласованности: только опубликованное событие можно использовать для записи изменений в БД. Если событие опубликовано, но его нельзя обработать и внести изменения в базу, то можно повторить попытку и повторно обработать сообщения.
В отличие от шаблона transactional outbox или Event Sourcing, в паттерне listen to yourself обновления базы данных являются согласованными в конечном счете. Это означает, что существует период, когда команда завершила обработку, но база данных не была обновлена. Впрочем, на практике такая рассинхронизация обычно длится недолго. Паттерн listen to yourself разделяет записи Kafka и записи в базу данных на разные процессы, позволяя микросервисам быстро реагировать на запросы благодаря отложенной обработке данных.
Разумеется, есть и другие решения проблемы двойной записи, например, двухфазная фиксация (2PC), транзакции расширенной архитектуры (XA) и шаблон Sage. Однако, их реализация довольно сложна и возможно не на всех технологиях. Как это сделать, рассмотрим в следующий раз.
Освоить приемы построения надежных распределенных архитектур с помощью Apache Kafka вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- Книга Мартина Клеппмана «Высоконагруженные приложения. Программирование, масштабирование, поддержка», 2018 г.
- https://www.confluent.io/blog/dual-write-problem/
- https://developer.confluent.io/courses/microservices/the-transactional-outbox-pattern/
- https://microservices.io/patterns/data/transactional-outbox/
- https://developer.confluent.io/courses/microservices/event-sourcing/
- https://microservices.io/patterns/data/event-sourcing/
- https://developer.confluent.io/courses/microservices/the-listen-to-yourself-pattern/
- https://codeopinion.com/listen-to-yourself-pattern-is-it-an-alternative-to-the-outbox-pattern/