 1078
1078 
Содержание
Архитектура Data Lake: что не так с потоковыми обновлениями данных в Data Lake, как Apache Iceberg реализует эти операции и почему Upsolver решили улучшить этот формат
Проблема потоковых обновлений в Data Lake и 2 подхода к ее решению
Считается, что озеро данных (Data Lake) предлагают доступное и гибкое хранилище, позволяющее хранить данные любого типа. Однако, потоковая передача данных в больших масштабах вносит дополнительные сложности построения и эксплуатации таких хранилищ. В отличие от пакетной парадигмы обработки информации, при потоковой передаче изменений и большом объеме данных изменения должны эффективно фиксироваться практически в реальном времени. Но частые обновления создают много маленьких файлов. Это проблематично, поскольку небольшие файлы создают накладные расходы на доступ к данным, ведь операции дискового ввода/вывода (I/O, Input/Output) являются очень медленными. Это напрямую влияют на фиксацию данных и производительность запросов. Поэтому эффективное выполнение частых обновлений в озере данных – довольно не простая задача, которую можно решить разными способами.
Каноническим подходом к фиксации обновлений в озере является копирование при записи (CoW, Copy-on-Write), при котором обновляемые данные копируются и перезаписываются в новый файл, включая изменения. При этом в большинстве случаев приходится заменять весь файл, чтобы включить одну обновленную запись. Это становится весьма ресурсоемким и дорогостоящим процессом при частых обновлениях.
Альтернативой CoW для обновления данных является парадигма слияния при чтении (MoR, Merge-On-Read). Она упрощает решение проблемы небольших файлов, связанных с частыми обновлениями. В случае MoR обновления записываются в журнал изменений и объединяются только тогда, когда данные считываются из озера посредством запроса. Поскольку запись в файл журнала требует меньше накладных расходов, чем частое создание новых файлов данных, подход MoR применяется чаще, чем CoW в сценариях потоковой передачи.
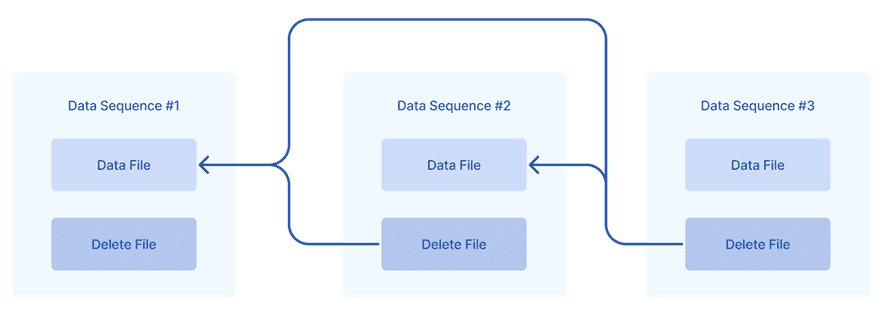
Каждая операция в озере генерирует порядковый номер данных (data sequence number), который добавляется ко всем файлам, связанным с этой операцией. Именно так в озере отслеживается порядок событий. Файлы данных имеют порядковые номера данных, как и файлы журналов изменений, включая файлы удаления данных. Например, выполняется три обновления с тремя порядковыми номерами данных. Второй файл удаления применяется только к первому файлу данных, тогда как третий применяется как к первому, так и ко второму файлам данных.
Чтобы записывать всю эту информацию о самих данных и их изменениях, в Data Lake применяются специальные форматы, например, Apache Iceberg, о котором мы писали здесь.
Как Apache Iceberg реализует обновления в озере данных и почему Upsolver решили это улучшить
Iceberg — это слой метаданных в хранилище объектов, который поддерживает ACID-транзакции в озере данных. Он предоставляет журнал транзакций для каждой таблицы, очень похожий на традиционную базу данных. Этот журнал отслеживает текущее состояние таблицы, включая любые изменения. Iceberg сохраняет текущий снимок файлов, принадлежащих таблице, и статистику о них, чтобы значительно уменьшить объем данных, которые необходимо прочитать во время запросов. Это заметно повышает производительность Data Lake.
MoR требует сканирования данных для определения положений удаляемых строк в файлах данных, чтобы добавить их в файл удаления. Хотя рабочая нагрузка по слиянию данных откладывается до момента их чтения, данные нужно сканировать заранее каждый раз, когда фиксируется позиционное удаление. Для потоковой передачи больших объемов данных выполнение такого сканирования всех данных каждый раз при их обновлении становится крайне неэффективным.
При запросе таблиц Iceberg перекладывает ответственность за выбор стратегии слияния во время MoR на механизмы запросов: Presto и Trino. Эти движки запросов с открытым исходным кодом, которые используют одну и ту же реализацию планирования запросов. При отправке запросов к озеру данных, где они хранятся в формате Iceberg, система запросов планирует путь запроса, используя архитектуру этого табличного формата. Эта архитектура подробно описывает, как хранятся данные, манифесты и метаданные.
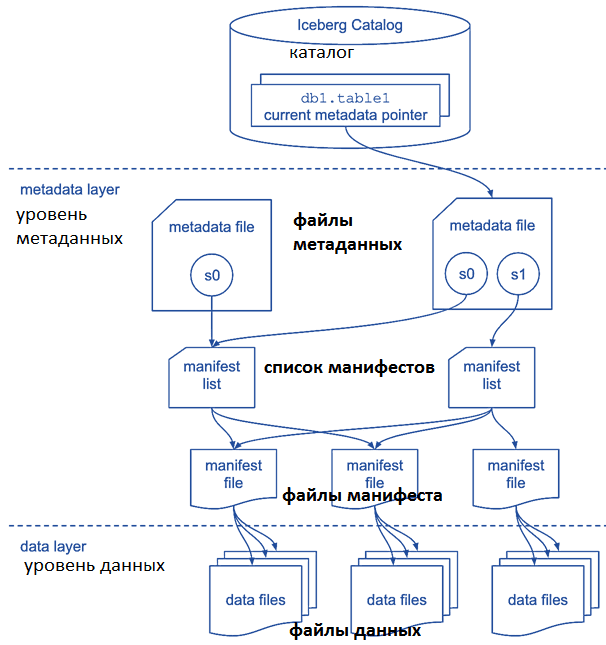
Каждый раз, когда выполняется изменение таблицы Iceberg (вставка, обновление, удаление и т.д.), создается новый снимок таблицы. Когда клиент Iceberg, например, движок запросов Trino или Presto, хочет запросить таблицу, считывается последний снимок и файлы, которые ему принадлежат. Это позволяет отслеживать изменения данных, поскольку таблица в любой заданной точке содержит набор снимков с течением времени, которые можно запросить.
Ключевая проблема при передаче потоковых данных в том, что их последовательные обновления могут поступать очень близко друг к другу или даже с одной и той же полезной нагрузкой. Чтобы сохранить целостность данных, обновления необходимо применять в правильном порядке. Например, удаление должно применяться ко всем предыдущим данным, но никогда к будущим данным, иначе возникнут дубли или пропуски.
Хотя обновление включает в себя только вставку и удаление файла, при его фиксации Iceberg создает несколько дополнительных файлов, представляющих изменения метаданных:
- файл манифеста, указывающий на каждый файл (вставка и удаление);
- список манифестов, указывающий на файлы манифеста;
- файл метаданных с новым снимком, указывающим на список манифестов, файлы манифестов и файлы данных.
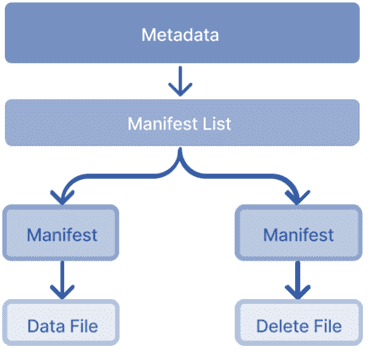
Фактически, даже при фиксации несколько обновлений в одной транзакции, Iceberg все равно создает один файл манифеста для каждой вставки и удаления. Это не только замедляет запись данных, но и оставляет после себя множество мелких файлов, которые впоследствии необходимо очистить. Проблема усугубляется при работе с частыми обновлениями.
Поэтому разработчики сервиса Upsolver решили повысить производительность потоковых коммитов данных в Iceberg, изменив шаблон этого формата по умолчанию. В решении Upsolver используется новый API потоковых обновлений. Этот API позволяет записывать обновления для нескольких порядковых номеров данных за один коммит. При выполнении одной операции несколько вставок или удалений — каждая со своим порядковым номером данных — могут быть представлены в одном файле манифеста. Для одновременных обновлений новый API потоковых обновлений создает один файл манифеста для всех вставок и один для всех удалений, которые будут применяться в рамках коммита. Это возможно благодаря назначению обновлениям разных порядковых номеров данных, даже если многие из них зафиксированы вместе. Результаты тестирования показали рост скорости выполнения операций в несколько раз.
Узнайте больше про построение надежных архитектур для мощных дата-платформ в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, архитекторов, инженеров, администраторов, Data Scientist’ов, менеджеров и аналитиков Big Data в Москве:
Источники

