 1033
1033 
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций.
Постановка задачи
Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так и потоковую передачу. Еще одним достоинство таких платформ является демократизация обработки данных: благодаря множеству готовых коннекторов они позволяют получить и передать данных, а также выполнить операции преобразования без разработки сложного кода. Основным инструментом пользователя в этом случае является SQL, который знаком каждому аналитику. Таким образом, строить пакетные и потоковые конвейеры обработки данных могут даже исследователи и аналитики без профессионального владения Java/Scala и других языков промышленной разработки.
Одной из таких платформ данных является RisingWave – распределенная потоковая реляционная СУБД, которая обеспечивает простую, эффективную и надежную обработку потоковых данных. RisingWave позволяет оперировать результатами потоковой обработки, создавая постепенно обновляемые, согласованные материализованные представления. Это очень упрощает создание приложений потоковой обработки, позволяя выражать сложную логику потоковой обработки в виде каскадных материализованных представлений. Также можно сохранять данные в самой RisingWave, устраняя необходимость передачи результатов во внешние приемники. Впрочем, сегодня я покажу, как передать результаты потоковой обработки во внешнюю базу данных.
В качестве практической задачи рассмотрим обработку событий пользовательского поведения. Предположим, в Apache Kafka сохраняются результаты действий пользователя на веб-страницах:
- время события (event_timestamp);
- логин пользователя (user);
- адрес веб-страницы (page);
- событие пользовательского поведения (event), такое как клик, прокрутка, заполнение и отправка формы ввода, загрузка файла, фокус на каком-либо элементе GUI.
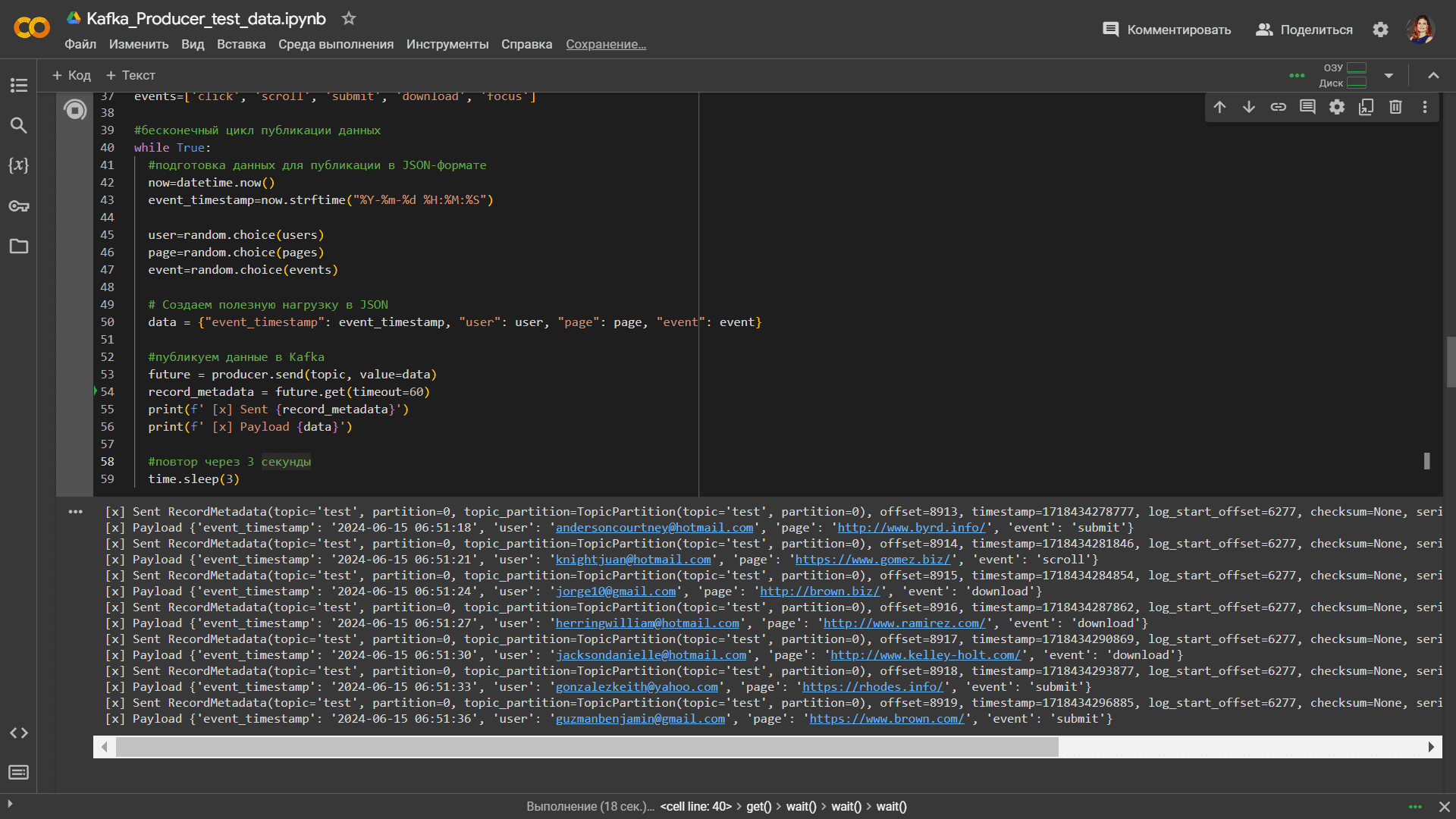
Для генерации событий, как обычно, пишу небольшой Python-скрипт и запускаю его в Google Colab:
#установка библиотек
!pip install kafka-python
!pip install faker
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
# Импорт модуля faker
from faker import Faker
#################################### публикация сообщений в Kafka###########################################
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
#batch_size=300
)
topic='test'
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker()
#списки веб-страниц
k=100 #количество веб-страниц
pages = [] # Инициализация списка для элементов заказа
for i in range(k):
wpage=fake.url()
pages.append(wpage)
#списки пользователей
u=1000 #количество пользователей
users=[]
for i in range(u):
username=fake.ascii_free_email()
users.append(username)
#списки событий
events=['click', 'scroll', 'submit', 'download', 'focus']
#бесконечный цикл публикации данных
while True:
#подготовка данных для публикации в JSON-формате
now=datetime.now()
event_timestamp=now.strftime("%Y-%m-%d %H:%M:%S")
user=random.choice(users)
page=random.choice(pages)
event=random.choice(events)
# Создаем полезную нагрузку в JSON
data = {"event_timestamp": event_timestamp, "user": user, "page": page, "event": event}
#публикуем данные в Kafka
future = producer.send(topic, value=data)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
print(f' [x] Payload {data}')
#повтор через 3 секунды
time.sleep(3)
Предположим, необходимо в режиме онлайн знать актуальную информацию о количестве событий каждого вида: сколько кликов было сделано, сколько загрузок и т.д. Эту агрегацию по полю event будем вычислять с помощью SQL-запроса в RisingWave и передавать в NoSQL-хранилище типа ключ-значение Redis.
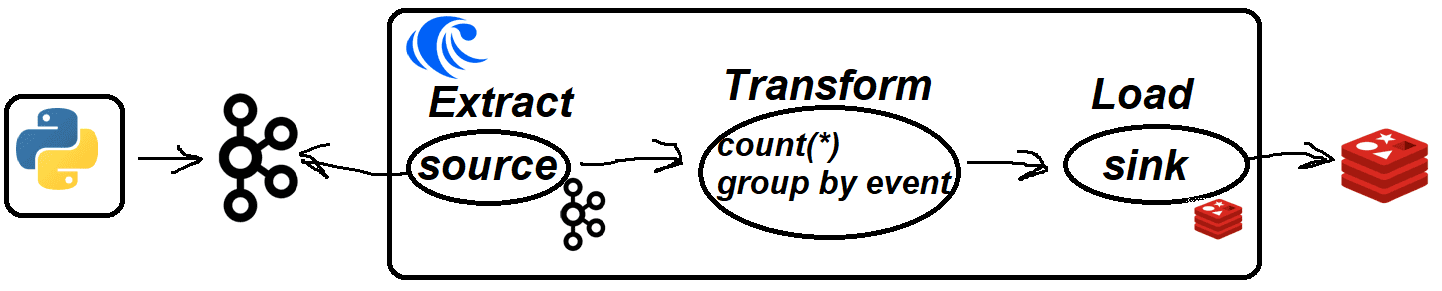
Реализация потокового конвейера с Apache Kafka и Redis
В отличие от других подобных платформ, например, Decodable, о работе с которой я писала здесь, в RisingWave источники и приемники данных нужно создавать с помощью SQL-инструкций, а не в GUI. Для чтения данных из Kafka необходимо объявить ее как источник данных, используя одноименный коннектор. Поскольку данные в Kafka записываются в формате JSON, это тоже необходимо указать при подключении к источнику, которое позволит обращаться к потребленным данным как к записям таблицы user_events. Код в RisingWave для этого выглядит так:
CREATE SOURCE IF NOT EXISTS user_events (
event_timestamp TIMESTAMP,
user VARCHAR,
page VARCHAR,
event VARCHAR
) WITH (
connector='kafka',
topic='test',
properties.bootstrap.server='your-host:your-port',
scan.startup.mode='latest',
properties.sasl.mechanism='SCRAM-SHA-256',
properties.security.protocol='SASL_SSL',
properties.sasl.username='your-username',
properties.sasl.password='your-password'
) FORMAT PLAIN ENCODE JSON;
Поскольку RisingWave оперирует материализованными представлениями, создадим материализованное представление event_statistics_mv, сразу выполнив количественную агрегацию по событиям пользовательского поведения:
CREATE MATERIALIZED VIEW IF NOT EXISTS events_statisics_mv AS
SELECT event, COUNT(*)
FROM
user_events
GROUP BY event;
Далее подключимся к Redis, объявив ключи и значения как строки:
CREATE SINK IF NOT EXISTS redis_sink
FROM events_statisics_mv WITH (
connector = 'redis',
primary_key = 'event',
redis.url= 'redis://your-username:your-password@your-host:your-host'
) FORMAT PLAIN ENCODE TEMPLATE (
force_append_only='true',
key_format = '{event}',
value_format = '{count}'
);
После этого выведем агрегированную информацию о количестве событий каждого типа:
SELECT * FROM events_statisics_mv;
Запуск всех этих инструкции в RisingWave приводит к созданию источника, приемника и материализованного представления:
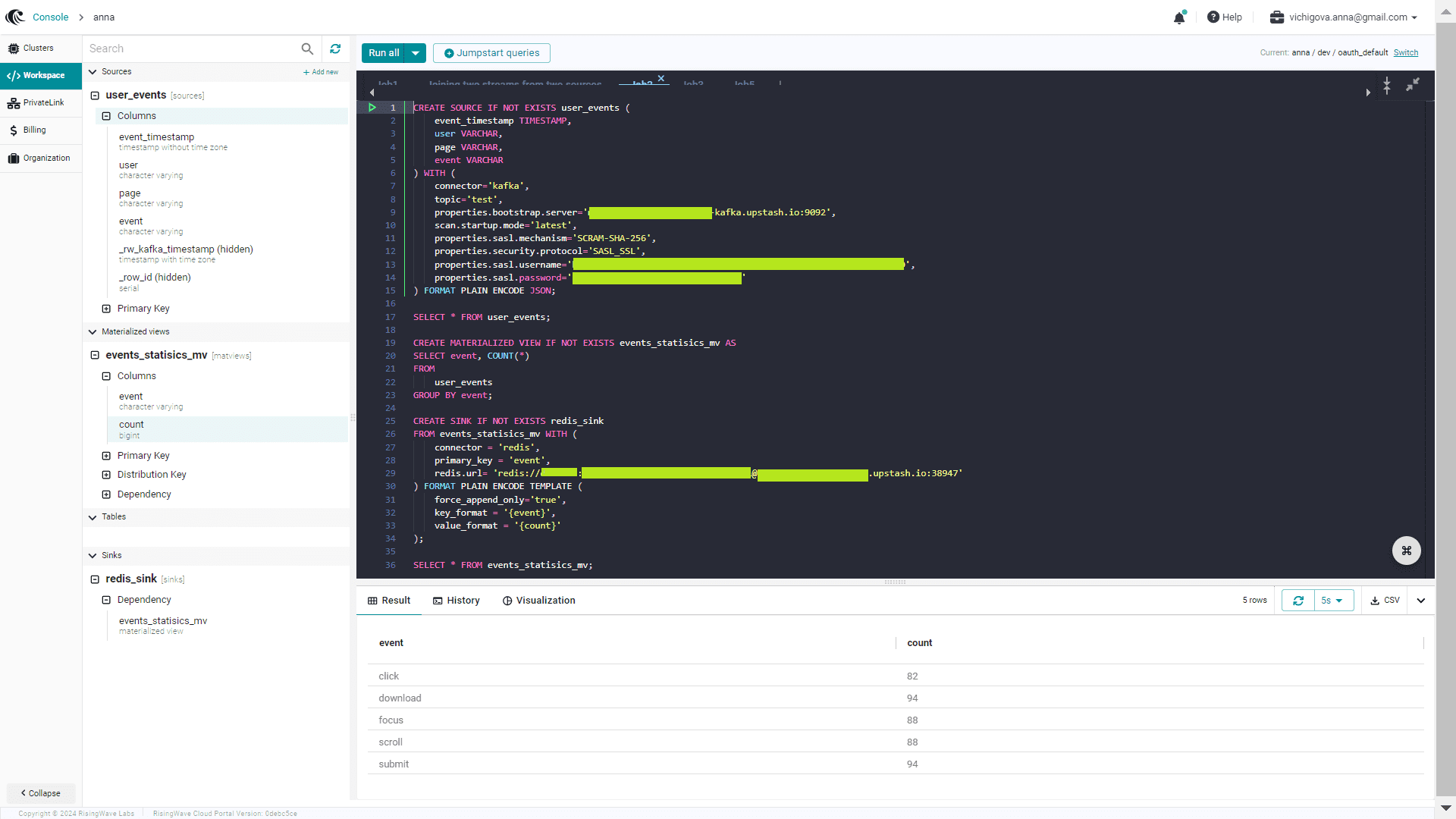
Также в интерфейсе платформы можно просмотреть визуализацию агрегированных метрик.
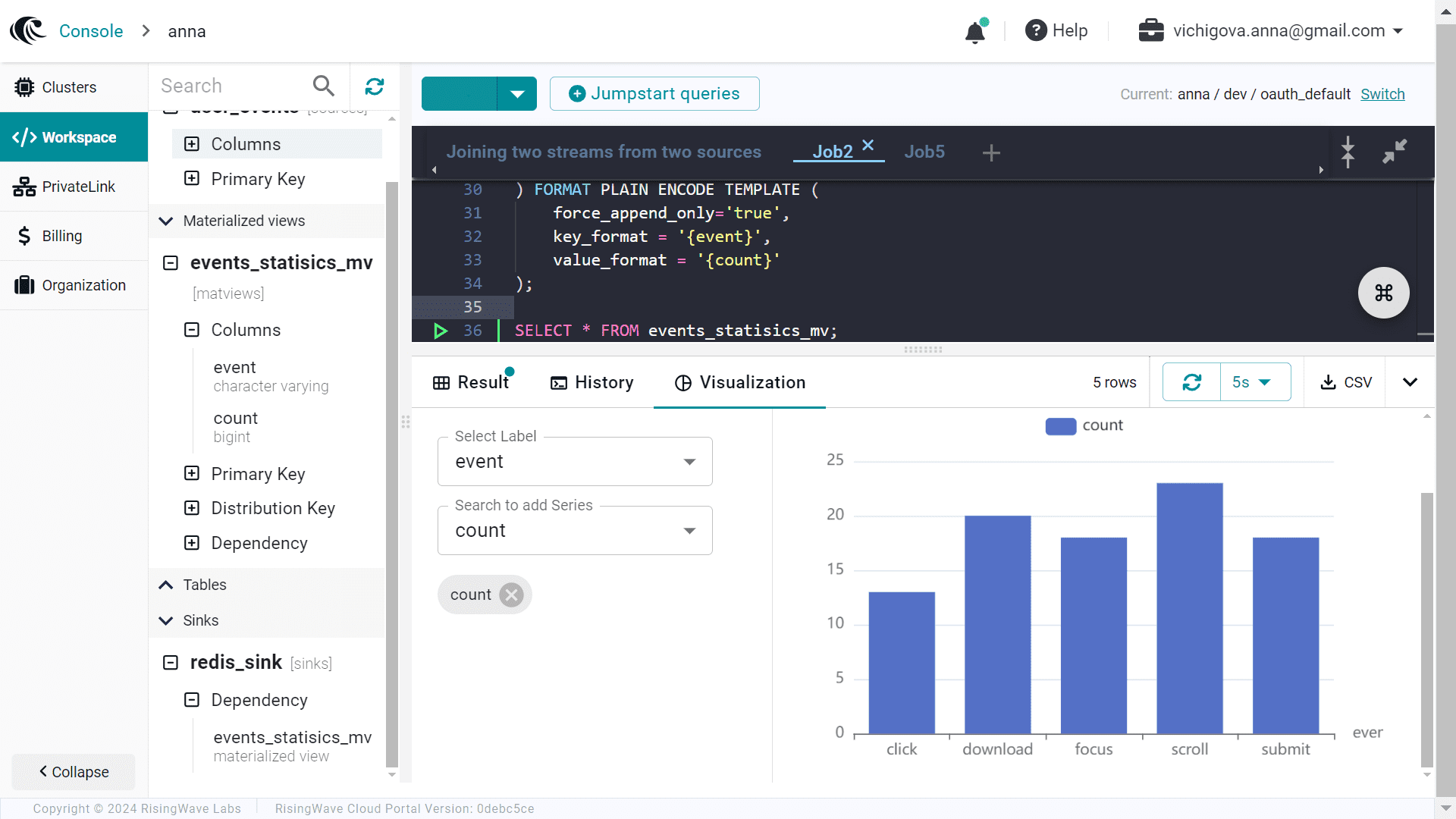
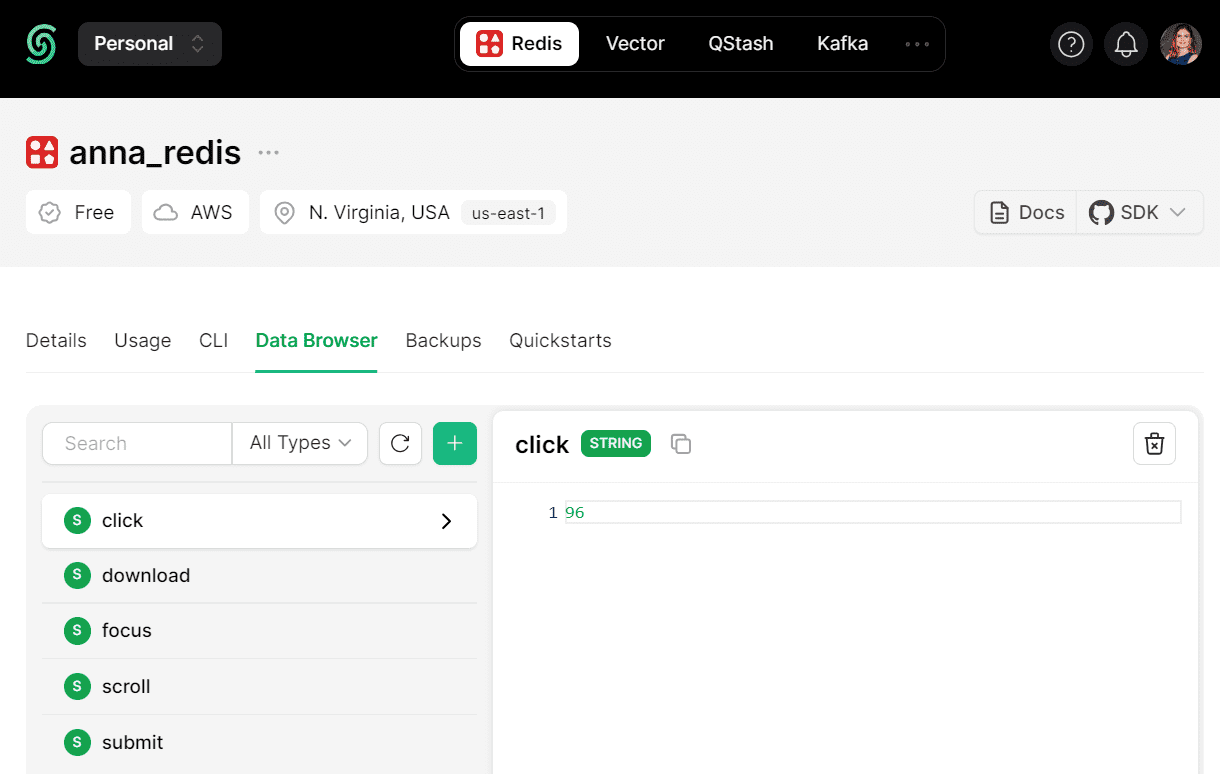
Агрегированные данные успешно передаются в Redis, что также можно увидеть в GUI этой СУБД, которая, как и Kafka, у меня развернута на serverless-платформе Upstash.
В следующий раз я покажу другой пример потоковой обработки событий из Kafka с помощью SQL-инструкций на платформе RisingWave, выполнив соединение нескольких потоков.
Узнайте больше про применение Apache Kafka в проектировании надежных конвейеров потоковой обработки данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

