
Как работает исполнитель Celery в Apache AirFlow, зачем ему очередь сообщений и каким образом это помогает масштабировать параллельное выполнение задач. Как работает исполнитель Celery в Apache AirFlow Именно исполнитель (Executor) в Apache Airflow отвечает за выполнение задач в рабочих процессах, определяя их локацию и последовательность, а также использование ресурсов. Хотя...

Как реализовать концепцию обратного давления (backpressure) в потоковой обработке событий с Apache Kafka: настройка конфигураций на стороне приложений-продюсеров и потребителей, а также мониторинг системных метрик. Обратное давление при публикации событий в Kafka Мы уже писали о том, зачем нужна концепция обратного давления (backpressure) в потоковой передаче событий и как она...
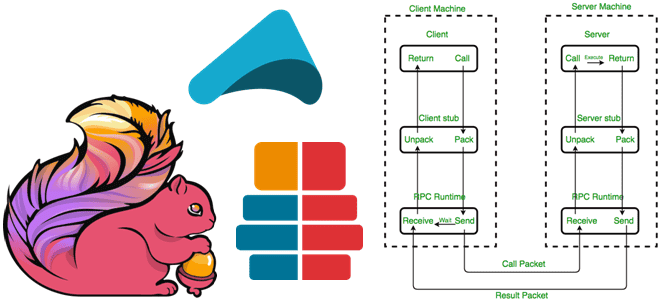
Зачем и как Apache Flink использует удаленный вызов процедур, с помощью каких технологий реализуется это RPC-взаимодействие и почему в 2023 году Akka заменен на Pekko. Удаленный вызов процедур в Apache Flink Мы уже рассказывали, как RPC-вызовы используются для коммуникации между компонентами Spark. Удаленный вызов процедур используется и в Apache Flink,...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...
Зачем Trino статистика таблиц, как MPP-движок создает план выполнения SQL-запросов к разным источникам данных, применяя CBO-оптимизацию, а также полную или частичную передачу обработки предикатов в базовое хранилище. Внутренние оптимизации Trino В отличие от MapReduce с материализацией промежуточных результатов на диске, в массово-параллельной архитектуре Trino промежуточные результаты передаются между рабочими узлами...
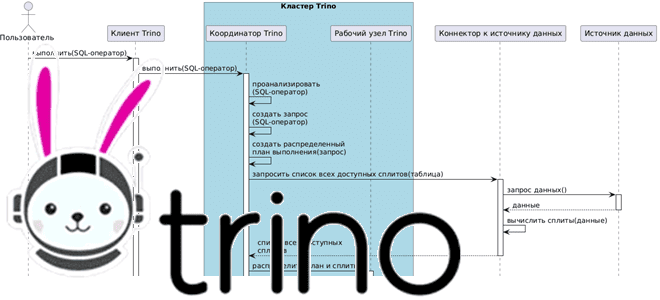
Как взаимодействуют рабочие узлы Trino между собой и с координатором кластера, а также с клиентскими приложениями и драйверами при выполнении SQL-запросов к данным из внешних источников без их фактического копирования. Последовательность выполнения запросов в кластере Trino Продолжая разбираться с Trino, сегодня рассмотрим, как этот аналитический движок с массово-параллельной архитектурой (MPP,...
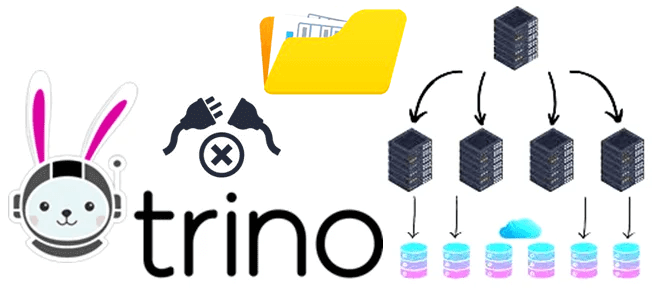
Как без копирования анализировать данные из разных источников в реальном времени с помощью SQL-запросов: каталоги и коннекторы Trino. Коннекторы Trino: как они работают и что настроить в каталоге Вчера мы разобрали, как устроен кластер Trino – аналитического движка с массово-параллельной архитектурой (MPP, Massively Parallel Processing), который обрабатывает данные на нескольких...
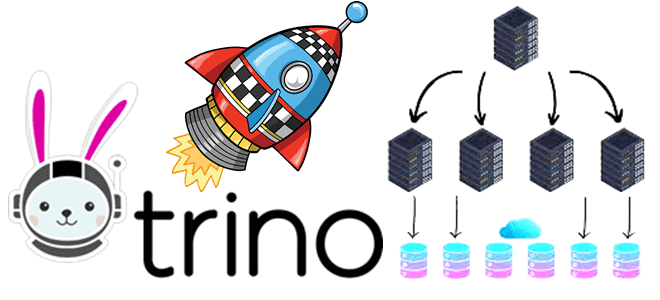
Как с помощью SQL-запросов анализировать огромные объемы данных из множества источников в реальном времени без их фактического копирования. Архитектура и принципы работы MPP-движка Trino. Что такое Trino и зачем он нужен Массово-параллельная архитектура (MPP, Massively Parallel Processing) с разделяемой памятью, когда система состоит из отдельных узлов, которые вместе выполняют одну...
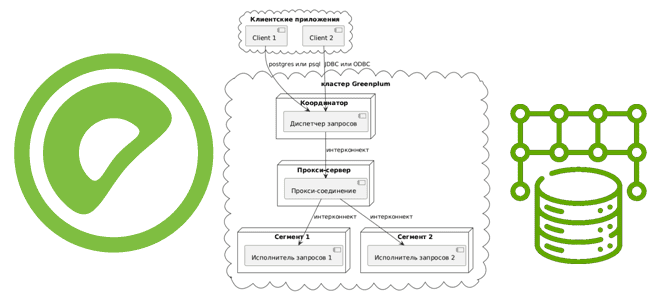
Как сегменты Greenplum взаимодействуют друг с другом для выполнения распределенных SQL-запросов, чем UDPIFC-режим интерконнекта лучше TCP-протокола, зачем проксировать межсетевые соединения и какими командами это сделать. Что такое интерконнекты в Greenplum Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных. Точкой входа в...