
Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand. 4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow Apache AirFlow считается одним из самых популярных...

В этой статье для разработчиков распределенных приложений разберем проблему с производительностью Apache Spark из-за неоптимальной стратегии переброса данных между оперативной и постоянной памятью. Что такое spill-эффект, почему он случается, как его идентифицировать и устранить. Что такое spill и почему он случается: под капотом Spark-приложений При том, что spill можно рассматривать...

7 ноября 2021 года вышел очередной релиз Apache NiFi с новыми фичами, улучшениями и исправлениями ошибок. Краткий обзор самых важных новинок: от постоянного хранилища для stateless-потоков и настроек облачных провайдеров до интеграции процессоров с пользователями Kerberos и улучшения работы с GitHub. Новинки и улучшения Apache NiFi 1.15.0 Свежий выпуск Apache...

Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта - платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов. Работать нельзя остановиться:...
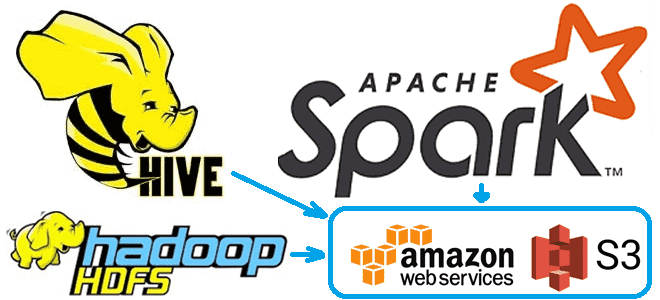
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...
Мы уже писали о сложностях развертывания Apache Kafka на платформе управления контейнерами Kubernetes. Некоторые из этих проблем отлично решает KubeMQ – брокер очередей сообщений на Kubernetes. Зачем нужна очередная служба обмена данными, как она устроена и при чем здесь Kafka. Проблемы Kafka на Kubernetes и не только Сложная архитектура современных...
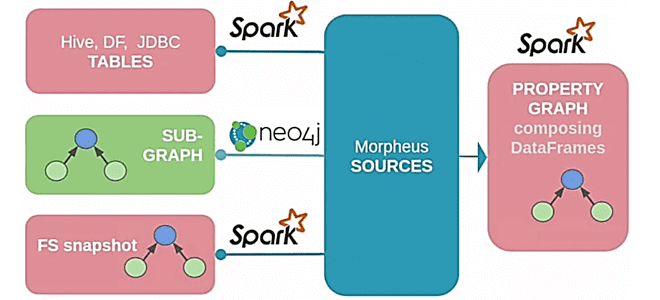
В рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как язык запросов Cypher должен был появиться в Apache Spark 3.0, зачем это нужно и почему до сих пор не реализовано. Краткая история проекта Morpheus, его связь с Neo4j, а также модулями Spark GraphX и GraphFrames. Что такое Morpheus...
Добавляя в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как Airbnb развивает Apache AirFlow и на практике используют эту платформу для создания, планирования и мониторинга конвейеров данных. Что такое Smart Sensor и как умные датчики экономят ресурсы на выполнение долгосрочных легковесных задач. Легкие, долгие и ресурсоемкие: проблемы...
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...

Вчера мы рассматривали коннектор Neo4j к Apache Spark, который позволяет строить конвейеры аналитики больших данных с применением графовых алгоритмов. Продолжая эту тему, сегодня разберем варианты интеграции Neo4j с Apache Kafka с помощью шаблонных запросов Cypher в плагине и коннектора от Confluent, а также от каких конфигурационных параметров зависит пропускная способность...