
Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand.
4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow
Apache AirFlow считается одним из самых популярных инструментов современной дата-инженерии, позволяя автоматизировать запуск и выполнение процессов обработки данных в рамках связанных конвейеров. Это особенно востребовано в области Big Data, например, для организации ETL/ELT-процессов при работе с корпоративными озерами и хранилищами данных. Даже в рамках одной компании направленные ациклические графы задач (DAG) Airflow охватывают множество бизнес-процессов и структур. Поэтому проблема управления жизненным циклом производственных развертываний Airflow актуальна для дата-инженеров.
Обработка нескольких сред Airflow становится сложной, если необходимо настроить локальную среду для разработки новых производственных DAG’ов. Например, требуется разработать новый фрагмент Python-кода, который обогащает данные во время процесса загрузки. Но код является частью более широкого конвейера с различными типами задач и вызывается из Python-оператора. В свою очередь, Python-оператор является частью DAG, который еще включает JVM-задание Spark, вызываемое из SparkSubmitOperator, и некоторые аналитические запросы к базе данных.
К таким DAG, где задействовано несколько разных систем, возникает множество вопросов:
- как убедиться, что наш Python-код работает должным образом в процессе разработки;
- как определить работоспособность кода в реальной среде, прежде чем запускать его в production;
- как быстро обнаруживать и устранять проблемы;
- как убедиться, что отличная работа в средах разработки и тестирования, будет аналогичной и в производственной среде?
Ответить на эти вопросы и автоматизировать развертывания сложных DAG’ов помогут технологии контейнерной виртуализации, т.е. Docker и Kubernetes. Как это работает, посмотрим на примере лучших практик управления конвейерами обработки данных в Apache AirFlow от дата-инженеров израильской компании Databand, которая специализируется на продуктах и сервисах в области DataOps.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
2 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Цикл разработки конвейера обработки данных от дата-инженеров Databand
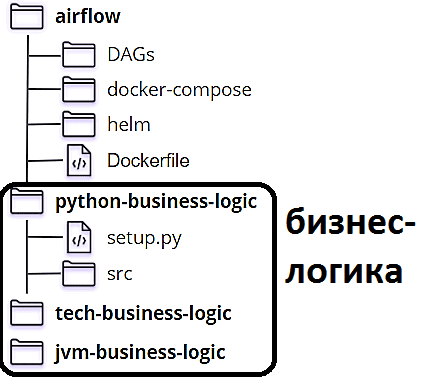
Прежде всего покажем структуру папок в репозитории Databand, где хранятся конвейеры AirFlow:
- папка DAG, которая содержит всю логику планирования и организации конвейеров обработки данных. Здесь находятся только DAG с операторами, но нет ни исходного кода вызываемых Python-файлов.
- папка docker-compose для развертывания локальной среды разработки. Напомним, Compose – это инструмент для создания и запуска многоконтейнерных Docker-приложений, который позволяет создать несколько изолированных сред на одном хосте и обеспечивает защиту данных при создании контейнеров.
- папка Helm – пакетного менеджера Kubernetes, который помогает установить приложения Kubernetes и управлять их жизненным циклом. Helm как установщик пакетов для Kubernetes, включает инструменты для создания, отладки, компоновки и сопровождения конфигураций K8s-ресурсов.
- Папка бизнес-логики с Python-файлами и файлом setup.py, чтобы его можно было импортировать как модуль
- Папка бизнес-логики с SQL-запросами к БД;
- Папка бизнес-логики для JVM, включая файлы Java/Scala и конфигурацию Gradle.
Бизнес-логика, распределенная по 3-м папкам, представляет собой код, который фактически выполняет загрузку и обогащение данных. Вынос бизнес-логики в отдельные папки позволяет запускать эти задачи отдельно от AirFlow, если их нужно протестировать локально или запускать их в других оркестраторах (Luigi, Hop, Dagster и прочих альтернативах) или как задания CRON.
В цикле разработки AirFlow-конвейеров дата-инженеры Databand выделили 4 этапа:
- локальная разработка кода – разработать Python-код локально и убедиться, что он работает в локальной среде Airflow;
- запуск разработанных DAG’ов в среде docker-compose после локальной разработки конвейеров и проверки их работоспособности с использованием того же Docker-образа, что в промежуточной (staging) и производственной (production) средах. Этот шаг помогает тестировать, находить и устранять проблемы в конвейере, с которыми дата-инженеры не сталкивались в процессе разработки, без необходимости ждать развертывания Kubernetes или запуска CI/CD-инструментов.
- запуск в промежуточной среде, аналогичной производственной. Staging работает в кластере Kubernetes, развернутом с helm3 и ветвлением в Git. После того, как разработка завершена и все работает должным образом в среде создания Docker-образов, разработчик помещает свой код в репозиторий GitLab и открывает запрос на слияние, а CI/CD создает свой образ с новым кодом и развертывать его в кластере с определенным пространством имен. Благодаря синхронизации Git с папкой, где хранятся DAG’и для этой среды, можно быстро исправить обнаруженные здесь проблемы, не дожидаясь CD-задания для повторного развертывания Docker-образа. После объединения веток кода, промежуточная среда очищается.
- выпуск в производство – публикация DAG-файлов в production-среде. Разработчик объединяет изменения в мастер-ветку, где их принимает CI/CD-процесс и разворачивает в production.
Такой четырехэтапный процесс снижает вероятность возникновения ошибок в production и гарантирует, что даже в случае редких сбоев их можно будет быстро обнаружить и исправить до проявления критических последствий. Также корректно настроенные среды (dev, stage, prod) помогут сократить накладные расходы на тестирование, сводя длительность прогона тестов к нескольким минутам. Читайте в нашей новой статье, как организовать мониторинг batch-конвейеров Apache AirFlow через Slack с помощью веб-перехватчиков. А как автоматически масштабировать поды Kubernetes с Apache AirFlow в зависимости от метрик рабочей нагрузки, мы рассказываем здесь.
Код курса
ADH-AIR
Ближайшая дата курса
в любое время
Продолжительность
ак.часов
Стоимость обучения
0
Узнайте больше про администрирование и эксплуатацию Apache AirFlow для эффективной по организации ETL/ELT-процессов в аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

