 964
964 
Содержание
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant.
5 способов резервного копирования в Apache HBase
Apache HBase — это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой системы Hadoop HDFS. При ее высокой надежности, резервное копирование данных никогда не будет лишним. Репликация на отдельный носитель критически важна для защиты от потери или повреждения первичных данных. Инкрементное резервное копирование обеспечивает более быстрый метод резервного копирования данных, чем многократное выполнение полных резервных копий. При инкрементном резервном копировании последующие копии данных содержат только ту часть, которая изменилась с момента создания предыдущей резервной копии. Такой подход помогает обеспечить сохранность данных, экономя дисковое пространство.
Сегодня в качестве резервного хранилища чаще всего используются облачные сервисы типа Google Cloud Storage или AWS S3, чтобы файлы и данные оставались доступными в случае сбоя системы, локального или стихийного бедствия. Также это экономит деньги и физическое пространство ИТ-инфраструктуры, независимо от ее вида: полностью в облаке или гибридный вариант.
Поэтому в международной ИТ-компании Clairvoyant процесс инкрементного резервного копирования данных из экосистемы Apache Hadoop стал обязательной процедурой. Реализовать резервное копирование в HBase можно следующими базовыми способами:
- Репликация (Replication) данных в другой кластер HBase, поддерживает инкрементный подход;
- Копирование таблиц (CopyTable) в другой кластер HBase, поддерживает инкрементный подход;
- Моментальные снимки (Snapshot) – не требует кластера NoSQL-хранилища в месте назначения, но и не поддерживает инкрементное резервное копирование;
- Создание резервных копий (hbase backup) — не требует кластера HBase в месте назначения, поддерживает инкрементный подход, но подходит только для дистрибутива Cloudera Data Platform (CDP);
- Экспорт (Export) — не требует кластера NoSQL-хранилища в месте назначения, поддерживает инкрементный подход, поддерживает как CDP, так и дистрибутив Hadoop от Cloudera (CDH, Cloudera’s Distributionincluding Apache Hadoop)
Поскольку утилита Export поддерживает любую версию NoSQL-хранилища, именно ее и выбрали администраторы кластера Hadoop в компании Clairvoyant. Как это выглядит на практическом примере, мы рассмотрим далее.
Практический пример инкрементного резервирования в AWS S3
Синтаксис команды экспорта таблицы HBase в AWS S3 выглядит так:
hbase org.apache.hadoop.hbase.mapreduce.Export -Dfs.s3a.access.key=
<access-key> -Dfs.s3a.secret.key=<secret-key> <table-name>
<S3-location> <version> <starttime-in-epoch-format>
Предположим, требуется экспортировать данные таблицы под названием person в AWS S3. Просмотрим, какие данные изначально содержатся в этой таблице с помощью команды scan ‘person’:

Итак, изначально в таблице всего 2 строки и 3 столбца. Экспортируем данные в AWS S3 из этой таблицы с помощью следующей команды, с момента Starttime=1626784250177:
hbase org.apache.hadoop.hbase.mapreduce.Export -Dfs.s3a.access.key=
<access-key> -Dfs.s3a.secret.key=<secret-key> person
s3a://clairvoyant-hadoop-test-bucket/person/date1 1 1626784250177
Добавим в таблицу person больше записей, пусть теперь там будет 4 строки:
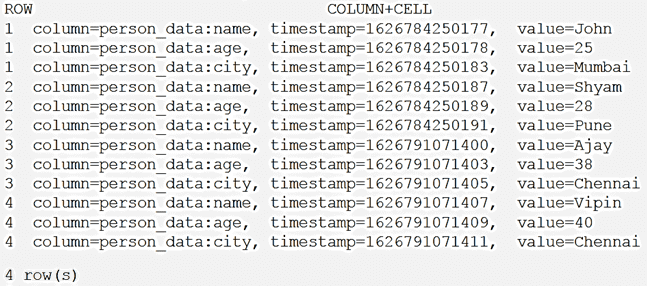
Экспортируем данные в S3 с момента Starttime= 1626791071400:
hbase org.apache.hadoop.hbase.mapreduce.Export -Dfs.s3a.access.key= <access-key> -Dfs.s3a.secret.key=<secret-key> person s3a://clairvoyant-hadoop-test-bucket/person/date2 1 1626791071400
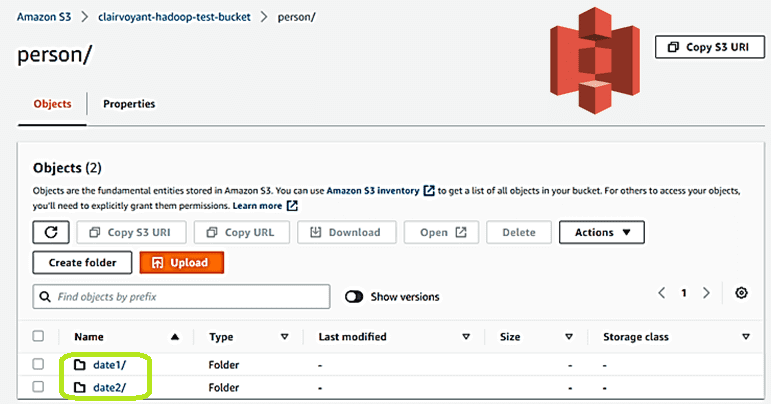
В результате этого в AWS S3 появились 2 объекта, что можно увидеть в веб-интерфейсе:
Чтобы сымитировать восстановление данных, например, после сбоя, рассмотрим, как импортировать таблицы из AWS S3. Сперва следует удалить все записи из таблицы person с помощью команды truncate. После того, как в локальном NoSQL-хранилище экосистемы Apache Hadoop таблица станет пустой, т.е. содержит 0 строк, что легко проверить с помощью команды scan, в нее можно залить данные из S3. Синтаксис команды выглядит так:
hbase org.apache.hadoop.hbase.mapreduce.Import -Dfs.s3a.access.key=
<access-key> -Dfs.s3a.secret.key=<secret-key> <table-name> <S3-location>
Применим эту команду, подставив нужные значения:
hbase org.apache.hadoop.hbase.mapreduce.Import -Dfs.s3a.access.key=
<access-key> -Dfs.s3a.secret.key=<secret-key> person
s3a://clairvoyant-hadoop-test-bucket/person/*
В результате выполнения все записи из S3 снова появятся в NoSQL-хранилище экосистемы Apache Hadoop. Таким образом, потеря данных больше не страшна. Можно автоматизировать эту процедуру, написав скрипт и запланировав его как CRON-задание по расписанию, чтобы ежедневно загружать инкрементные данные из Hbase в AWS S3. Читайте в нашей новой статье, как подобную задачу резервного копирования и восстановления данных реализовали дата-инженеры индийской компании Myntra.
Освойте администрирование и эксплуатацию Apache HBase и других компонентов экосистемы Hadoop для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

