
В этой статье для разработчиков распределенных приложений разберем проблему с производительностью Apache Spark из-за неоптимальной стратегии переброса данных между оперативной и постоянной памятью. Что такое spill-эффект, почему он случается, как его идентифицировать и устранить.
Что такое spill и почему он случается: под капотом Spark-приложений
При том, что spill можно рассматривать как встроенный в Apache Spark способ устранения ошибки нехватки памяти (OutOfMemory, OOM), он сам может стать причиной снижения производительности приложения. Каждой задаче назначается раздел памяти для обработки данных. Если данных слишком много, и они не помещаются в выделенный для задачи раздел памяти, чтобы не потерять вычисления, данные записываются (переливаются) на диск.
Таким образом, переброс или spill – это термин для обозначения процесса перемещения RDD из RAM на диск, а затем снова обратно в RAM. Это происходит, когда RDD слишком большой для размещения в памяти и фреймворк вынужден выполнять дорогостоящие операции чтения и записи на диск, чтобы освободить локальную оперативную память и избежать OOM-ошибки, которая может привести к сбою приложения. Такая ситуация случается по одной из следующих причин:
- значение параметра spark.sql.files.maxPartitionBytes – количество байтов для упаковки в один раздел при чтении файлов формата Parquet, JSON и ORC. По умолчанию это свойство задано 128 МБ. Если установить раздел, считываемый Spark намного больше, например, 1 ГБ, активное поглощение может не вызвать утечку памяти, но вызовет spill-эффект.
- операция explode() на небольшом массиве данных с соединениями и декартовыми соединениями (CrossJoin) двух таблиц, результат которого может превысить размер раздела;
- агрегации по искаженным данным, которые неравномерно распределены по узлам кластера, также потенциально могут создать очень большой раздел и вызвать перенос данных из памяти на диск и обратно. Подробнее о том, как возникают перекосы и как с ними бороться, читайте в нашей новой статье.
Разобрав, что такое spill-эффект и чем он плох, далее рассмотрим, как его обнаружить.
Как обнаружить переброс данных из памяти на диск: 4 способа в UI
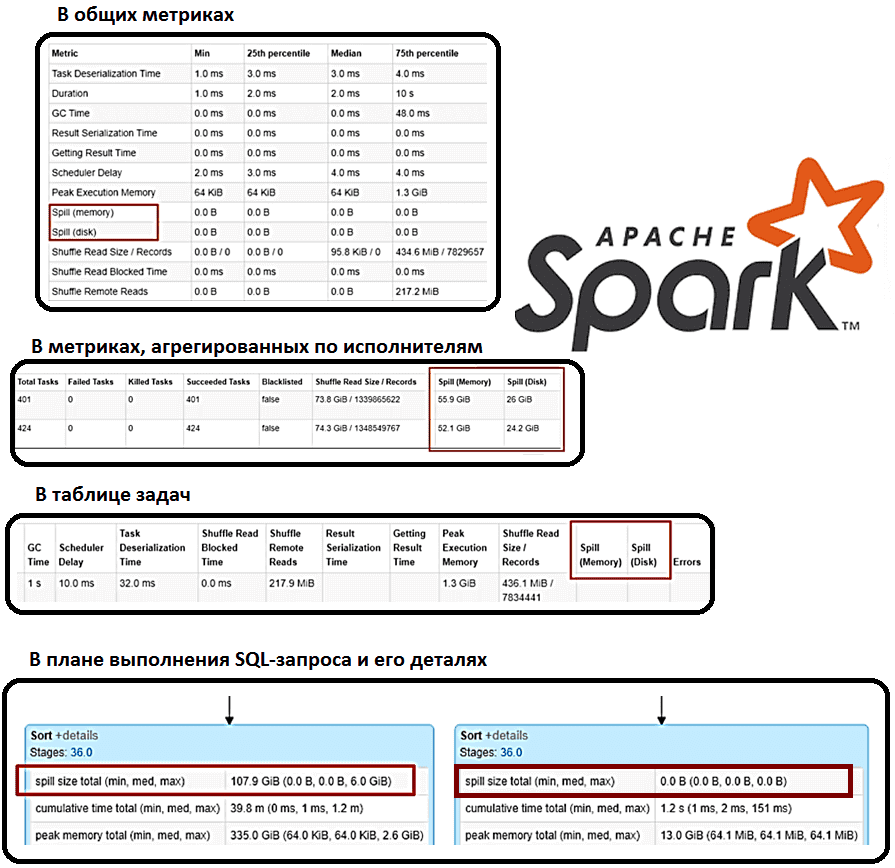
Spill представлен двумя значениями, которые всегда соседствуют друг с другом:
- Memory – размер данных в том виде, в каком они существуют в памяти до того, как они будут переписаны;
- Disk – размер данных, которые перебрасываются на диск, сериализуются, записываются на диск и сжимаются.
С точки зрения данных оба хранят одни и те же данные, но на диске это значение обычно меньше, т.к. данные здесь сжимаются более эффективно, чем в памяти. Отследить переброс данных из памяти на диск можно прямо в пользовательском интерфейсе на странице сведений о конкретном этапе в Spark UI:
- в общих метриках;
- в метриках, агрегированных по исполнителям;
- в таблице задач;
- в плане выполнения SQL-запроса и его деталях.
Как устранить проблему перезаписи данных в Spark-приложениях из памяти на диск и обратно
Прежде всего отметим, что не существует универсального решения проблемы spill-эффекта, т.к. она зависит от множества причин. Причем не каждый вариант решения можно реализовать на практике. Самый простой и дорогостоящий способ – выделить кластер с большим объемом памяти на одного worker’а. Однако, это может не сработать, если нет возможности менять конфигурацию Spark-кластера. Поэтому лучше сперва устранить главную причину, например, если spill вызван перекосом данных, когда они неравномерно распределены по узлам кластера, при устранении этого фактора spill также автоматически прекратится.
Также можно поработать с разделами следующими способами:
- уменьшить размер каждого раздела, увеличив их количество;
- задать значение параметра sql.files.maxPartitionBytes;
- явно перераспределить данные с помощью методов repartition() или coalesce(), о которых мы писали здесь, чтобы устранить перекос и сделать их распределение по кластеру более равномерным. Также можно попробовать криптографический метод модификации хэш-функции, о чем мы рассказываем в новой статье.
- изменить значение параметра spark.sql.shuffle.partitions – количество разделов для использования при перетасовке данных для объединений или агрегатов, по умолчанию равен 200.
Читайте в нашей новой статье, как фильтр Блума помогает снизить число обращений к жесткому диску и где это пригодится при работе Apache Spark с Parquet-файлами. А про spill-файлы в MPP-СУБД Greenplum мы рассказываем здесь.
Больше подробностей эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вам помогут узнать специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- https://medium.com/curious-data-catalog/spill-often-ignored-sparks-performance-problem-9b4c1ea962f
- https://xuechendi.github.io/2019/04/15/Spark-Shuffle-and-Spill-Explained
- https://medium.com/road-to-data-engineering/spark-performance-optimization-series-2-spill-685126e9d21f
- https://spark.apache.org/docs/latest/sql-performance-tuning.html

