
Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта – платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов.
Работать нельзя остановиться: простои в платежных системах
Экосистема онлайн-платежей имеет незапланированные колебания на всех уровнях, начиная от источника платежного запроса и до получения клиентом уведомления об окончательном статусе платежа. Их нельзя полностью избежать, но можно попытаться выявить и проинформировать всех участников онлайн-транзакции, чтобы предупредить возможные сбои в финансовых переводах. Поскольку основным видом бизнеса Razorpay является предоставление шлюза онлайн-оплаты, компании необходимо быстро обнаруживать простои платежной системы. Под простоем понимается отключение или частичная деградация платежной системы, сбой в работе банка или интеграции, которые могут повлиять на выполнение клиентом транзакции.
Изначально дата-инженеры Razorpay реализовали быстрое решение поверх существующего хранилища данных, которое опрашивало базу через регулярные промежутки времени и определяла показатель успешности (SR, Success Rate). Если значение SR ниже определенного порога, это считается простоем и система генерирует уведомления. Хотя решение оказалось рабочим, оно имело следующие проблемы:
- зависимость – будучи компонентом основной платежной системы, приложение мониторинга простоев не работает при отказе базовой части;
- длительное время обнаружения – чтобы снизить нагрузку на БД, частота расчета SR составляла каждые 2 минуты, что много для платежной системы;
- отсутствие расширяемости – система обнаружения простоев работала только на уровне Razorpay и не охватывает сбои онлайн-оплаты по причине конкретного интернет-магазина;
- низкая точность из-за задержки репликации базы данных определение времени простоя не всегда было точным, и возникали ложные срабатывания.
Поэтому для оперативного и надежного определения простоев нужно новое решение со следующими возможностями:
- быстрое определение простоев;
- классификация простоя по степени серьезности и фактора возникновения – способ оплаты, эмитент, тип карты, проблемы на стороне получателя и пр.
- настройка правил обнаружения простоев для интернет-магазинов и платежного шлюза;
- непрерывный мониторинг и улучшение стратегий обнаружения простоев;
- автоматические проверки точности с устранением ложноположительных и истинно отрицательных ошибок по матрице ошибок;
Реализовать все эти требования могут следующие варианты дизайна:
- решение на основе БД, что требует нового хранилища с конвейером для записи данных, cron-заданий для вычисления SR, очистки старых данных и обнаружения простоев. Недостатками этого варианта являются низкая частота выполнения заданий, задержка репликации и много возможных точек отказа.
- система потоковой передачи событий. В качестве вычислительного движка в подобных решениях часто используется Apache Spark, но в данном случае команда Razorpay выбрала Flink. По функциональным возможностям и набору компонентов он похож на Spark, но Flink более привлекателен из-за действительно потоковой, а не микропакетной, передачи, высокой пропускной способности и богатых API-интерфейсов с набором специализированных библиотек.
Как именно Razorpay построили собственный сервис обнаружения простоев в платежной системе на базе Apache Flink, мы рассмотрим далее.
Сервис обнаружения простоев на базе Apache Flink и Kafka
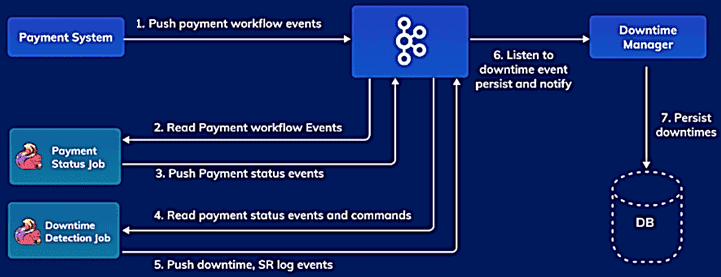
Новый сервис является независимым и самостоятельным приложением из следующих компонент:
- задание определения состояния платежа (Payment Status Job), которое считывает данные о платежных событиях из Apache Kafka;
- задание по обнаружению простоев (Downtime Detection Job), которое прослушивает события состояния платежа и обнаруживает простои согласно заданным периодам времени и правилам.
Задание по обнаружению простоев периодически выбирает определенное количество платежей – когорту и вычисляет SR-коэффициент как долю успешных платежей от общего количества. При этом типовой набор платежей для расчета SR зависит от метода оплаты, банка, онлайн-магазина и прочих аспектов финансового перевода. А стратегия обнаружения простоев зависит от множества факторов, что необходимо отразить в правилах. Поэтому команда Razorpay решила разработать систему, которая сохраняет настраиваемые правила обнаружения и может масштабироваться.
Во-первых, следует соединить два потока, Платежные события и Правила обнаружения простоев с порогами успеха. Далее следует обеспечить контроль над агрегацией платежных событий, то есть платежами по времени или счету для расчета SR с возможностью вариативной настройки периодов времени, т.к. время существования платежных событий не является постоянным для разных когорт. Apache Flink обеспечивает это с помощью механизма оконных функций. Любое обнаруженное время простоя сохраняется в функции и разрешается только тогда, когда SR превышает пороговые значения. Состояние платежного события в задании по обнаружению простоев очищается через регулярные промежутки времени с помощью настраиваемой стратегии очистки без использования встроенной функции Flink – StateTtl, которая чрезмерно загружает ЦП.
Чтобы оценить эффективность системы обнаружения простоев и используемых стратегий, необходимо рассчитать точность этого решения, сравнив вычисленный SR с фактическим SR платежей во время реальных простоев. Такая проверка выполняется на огромных объемах данных, а потому была автоматизирована и реализована с обращением в корпоративное озеро данных Razorpay.
После ввода в эксплуатацию новый сервис на базе Apache Flink и Kafka обнаруживает простои более 50 платежных когорт на уровне Razorpay и охватывает более 200 платежных когорт интернет-магазинов. В перспективе разработчики Razorpay планируют снизить время простоя своих платежных сервисов до нуля и создать Canary-процесс для развертывания обновлений в рабочей среде, а также реализовать систему рассылки уведомлений.
Узнайте больше, как использовать Apache Flink и Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

