 973
973 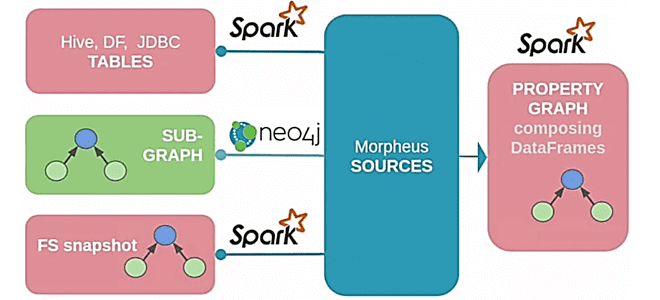
Содержание
В рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как язык запросов Cypher должен был появиться в Apache Spark 3.0, зачем это нужно и почему до сих пор не реализовано. Краткая история проекта Morpheus, его связь с Neo4j, а также модулями Spark GraphX и GraphFrames.
Что такое Morpheus и при чем здесь Apache Spark с Cypher
Изначально язык запросов Cypher графовой NoSQL-СУБД Neo4j, не поддерживался в Apache Spark. Однако, в 2019 году, перед выпуском 3-й версии Спарк сообщество разработчиков проголосовало за включение Cypher для обработки графов в этот релиз вычислительного фреймворка. Это предполагало добавление Morpheus, модель графа свойств и графовые алгоритмы в набор инструментов анализа данных Spark.
Morpheus – это историческое название решения для обработки графов в Спарк от Neo4j с помощью проекта Cypher. Изначально Morpheus работал как стороннее дополнение к экосистеме Apache Spark, а начиная с релиза 3.0 его планировали добавить к фреймворку. Некоторые идеи Morpheus получили воплощение в модулях Спарк GraphX и GraphFrames как реализация парадигмы Pregel, о чем мы писали здесь и здесь.
Предполагалось, что Morpheus будет расширять Apache Spark с помощью языка запросов Cypher, который активно используется в графовой NoSQL-СУБД Neo4j для разработки и анализа графа свойств, где данные представлены помеченными вершинами ориентированного мультиграфа и отношениями между ними. По сути, Cypher выполняет роль SQL для графового анализа данных. Cypher для Apache Spark позволяет выполнять запросы Cypher к графам свойств в кластере Спарк аналогично как SQL позволяет запрашивать табличные данные.
Еще в 2017 году разработчики Neo4j представили первый релиз Cypher для Apache Spark, который позволяет выполнять запросы Cypher в Spark и предоставляет программный API для работы с графами по типу Спарк-API. Далее эта идея продолжила развиваться в проекте Morpheus на базе Cypher, который преобразует обработанный граф свойств в датафреймы Spark, позволяя создавать конвейеры аналитики больших данных с графовыми алгоритмами.
Morpheus основан на Spark SQL DataFrame API, предлагая интеграцию со стандартной обработкой Spark SQL и с GraphX. Начиная с версии 0.3.0, проект Morpheus перешел на Scala 2.12 и Spark 2.4. Но, поскольку только Spark 2.4.2 использует Scala 2.12 для своих предварительно созданных вспомогательных двоичных файлов, для использования Morpheus с более поздней версией Spark его необходимо собрать вручную.
Однако, несмотря на практическую необходимость анализа данных с помощью графовых алгоритмов, сегодняшний статус проекта Morpheus вызывает вопросы. В частности, в официальной документации последний версий Apache Spark 3.0+ названия Morpheus и Cypher даже не упоминаются. Все описание графовых вычислений в Спарк сведено к GraphX Programming Guide, где подробно рассмотрена концепция графа свойств, Pregel API, а также графовые операторы и алгоритмы. А осенью 2021 года разработчики Cypher и Neo4j выпустили новую версию коннектора к Apache Spark, основными новинками которой стала доступность потоковой передачи Spark, как источника, так и приемника. Подробнее об этом мы недавно рассказывали в этой статье.
Тем не менее, Morpheus и Cypher для Apache Spark не совсем забыты. На какой стадии сегодня находятся эти проекты и будут ли они полностью интегрированы в Спарк , мы рассмотрим далее.
Проблемы графовых вычислений в GraphX и GraphFrames
Напомним, сперва именно модуль GraphX был одним из основных компонентов Спарк для графового анализа. Но он основан на структуре данных RDD, имеет достаточно низкоуровневый API и не использует оптимизатор запросов Catalyst. Кроме того, GraphX доступен только пользователям Scala. Поэтому вместо GraphX сегодня все чаще используется модуль GraphFrames – пакет Спарк , который реализует графовые алгоритмы через структуру данных DataFrame, а также включает простое сопоставление с образцом графа с образцами фиксированной длины (motifs).
Однако, GraphFrames имеет семантически слабую модель данных графа на основе нетипизированных ребер и вершин, а его возможность сопоставления с motifs-образцами очень ограничена по сравнению с языком Cypher. Кроме того, модель графа свойств отлично зарекомендовала себя во многих задачах анализа, а потому пользователи транзакционных графовых СУБД хотят работать с неизменяемыми графами в Спарк.
Идея внедрения Morpheus в Спарк и состояла в том, чтобы определить тип графа свойств, совместимый с Cypher, на основе датафреймов, и заменить запросы GraphFrames на Cypher, а также переопределить алгоритмы GraphX/GraphFrames для типа PropertyGraph.
Предполагалось, чтоб в 3-ей версии фреймворка для этого будет применяться базовое подмножество Cypher для Apache Spark (CAPS), повторно используя существующие проверенные конструкции и код. Этот графовый процессор запросов, как и CAPS, будет накладываться на механизм запросов Spark SQL с оптимизатором Catalyst и управлять им, используя планировщик графовых запросов CAPS.
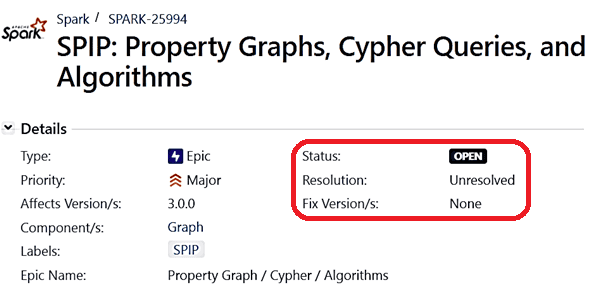
Однако, на текущий момент статус этого предложения по улучшению фреймворка Спарк до сих пор является открытым, с высоким приоритетом и отсутствием реализации. Впрочем, возможно в новых версиях этот SPIP будет реализован.
Узнайте больше подробностей про возможности Apache Spark и Cypher для графовой аналитики больших данных в бизнес-приложениях на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

