Мы уже писали о сложностях развертывания Apache Kafka на платформе управления контейнерами Kubernetes. Некоторые из этих проблем отлично решает KubeMQ – брокер очередей сообщений на Kubernetes. Зачем нужна очередная служба обмена данными, как она устроена и при чем здесь Kafka.
Проблемы Kafka на Kubernetes и не только
Сложная архитектура современных программных решений предполагает множество различных компонентов, которые должны взаимодействовать друг с другом независимо от центрального модуля или доступности других сервисов. Поэтому обмен данными между разными системами с помощью очереди сообщений становится стандартом де-факто. Очередь сообщений действует как посредник между различными сервисами одной системы или отдельными приложениями, позволяя гарантировать, что обработка данных будет происходить вне зависимости от локальной доступности получателя сообщения. На практике это используется в следующих случаях:
- асинхронная обработка между отдельными приложениями;
- микросервисные системы, где важна надежная связь между разными компонентами;
- упорядочивание и регулирование транзакций;
- оптимизация пакетной обработки данных;
- масштабирование распределенных приложений с неустойчивыми изменениями характера запросов;
- обеспечение устойчивости приложений в средах с большой вероятностью неожиданных сбоев;
- регулирование потребления ресурсов длительными процессами.
Существует множество брокеров сообщений: RabbitMQ, Apache Kafka, Pulsar, Redpanda, а также облачные платформы типа AWS Simple Queue Service, Azure Service Bus, Google Pub/Sub, DataCater и пр. Apache Kafka считается наиболее востребованной платформой потоковой передачи событий и активно используется во множестве компаний. Будучи open-source проектом, Kafka может интегрироваться с различными источниками и потребителями данных с помощью коннекторов и платформе Connect от Confluent. Наконец, Kafka достаточно хорошо масштабируется и поддерживает сложные функции обработки потоковых данных.
Однако, несмотря на широкое распространение, Kafka имеет ряд ограничений и специфических проблем, о которых мы упоминали здесь. Поэтому далеко не всегда эта платформа является лучшим вариантом в качестве системы очередей сообщений. В частности, ее монолитная архитектура больше подходит для локальных кластеров или высокопроизводительных облачных конфигураций с несколькими виртуальными машинами. А с учетом того, сколько памяти и места в постоянном хранилище нужно для Kafka, быстрое развертывание многоузлового кластера на автономной рабочей станции, например, при тестировании, становится непростой задачей. Иначе говоря, интегрировать Kafka с ИТ-инфраструктурой не всегда просто, особенно если основой такой архитектуры является платформа контейнерной виртуализации Kubernetes.
Совместное использование Apache Kafka и Kubernetes сопровождается целым рядом проблем, а сам процесс развертывания требует от администратора отличного знания обеих технологий. В частности, помимо предоставления базовой инфраструктуры вычислений, сети и хранения для локального кластера Kubernetes, потребуется установить и интегрировать все компоненты Kafka с помощью диспетчера пакетов Helm. К таким компонентам относится внешний сервис синхронизации метаданных Apache ZooKeeper для управления брокерами и топиками Kafka. Справедливости ради стоит отметить, что с выходом версии 2.8 в апреле 2021 года служба Zookeeper заменяется внутренним Quorum Controller с протоколом KRaft. Однако, это решение пока имеет статус экспериментального и не рекомендуется для использования в production. Впрочем, сложность развертывания Kafka на Kubernetes обусловлена не только наличием ZooKeeper или его альтернатив. Необходимо корректно настроить все зависимости, журналы, разделы и прочие элементы как самой Kafka, так и Kubernetes: поды, контейнеры, конфигурации, внутренние сервисы и пр.
При этом стоит помнить, что Apache Kafka работает на JVM, что добавляет Kubernetes значительные накладные расходы ресурсов, т.к. для каждого запущенного контейнера нужен большой объем памяти. А добавление нового узла Kafka в кластер Kubernetes требует сложной ручной балансировки для поддержания оптимального использования ресурсов. Также требуется обеспечить способы управления и реализации надежной стратегии резервного копирования и восстановления, чтобы защитить от сбоев кластер на большом количестве узлов. В отличие от кластеров Kubernetes, где данные сохраняются вне пода, а оркестратор автоматически запускает отказавший модуль, в Kafka нет такого встроенного механизма защиты от сбоев. Наконец, для эффективного мониторинга работы Kafka на Kubernetes нужны сторонние инструменты типа Saamsa, Lenses, Confluent Control Centre и других инструментов администратора, о которых мы писали здесь.
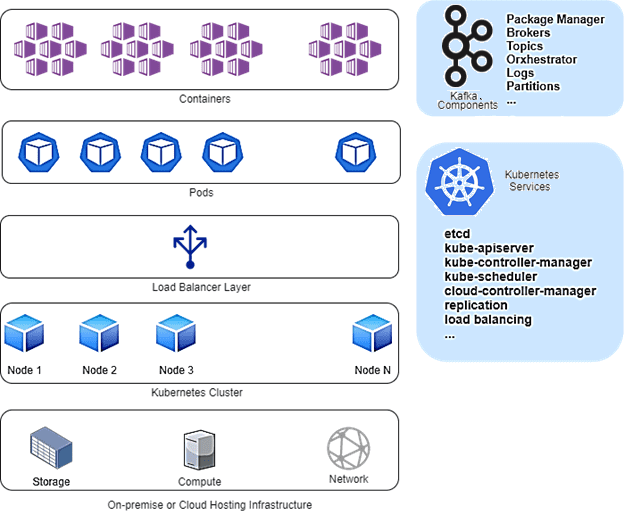
Таким образом, запуск Kafka на Kubernetes – не самая простая задача, что подтверждает опыт логистической компании Sixfold, о чем мы рассказываем здесь. Решить эту проблему можно обходным путем, используя вместо платформы потоковой передачи событий альтернативное решение, разработанное специально для K8s. Именно таким продуктом является KubeMQ, о котором мы поговорим далее.
KubeMQ: архитектура и принципы работы
KubeMQ – это служба обмена сообщениями, созданная для Kubernetes. Следуя лучшим практикам в области контейнерной архитектуры, KubeMQ не имеет состояния, т.е. каждый его узел остается неизменным, предсказуемым и воспроизводимым на протяжении всего жизненного цикла системы. А если необходимы изменения конфигурации, узлы отключаются и заменяются. Такая воспроизводимость KubeMQ означает, что он поставляется с нулевой конфигурацией и, в отличие от Kafka, не требует сложной настройки параметров после установки. KubeMQ разработан для поддержки широкого спектра шаблонов сообщений. Будучи одновременно брокером и очередью сообщений, он поддерживает возможности:
- публикацию и потребление сообщений с сохранением или без;
- синхронные и асинхронные запросы/ответы;
- 2 семантики доставки сообщений – хотя бы 1 раз (at least once) и не более одного раза (at most once);
- шаблоны потоковой передачи;
- RPC-вызовы;
- SDK для .Net, Java, Python, Go и NodeJS;
- RESTful-API с веб-сокетами для двунаправленного обмена;
- контроль доступа по аутентификации и авторизации;
Ключевыми преимуществами KubeMQ по сравнению с Kafka являются следующие:
- более широкие возможности – Kafka поддерживает только Pub/Sub с сохранением и потоковой передачей, а шаблоны RPC-вызовов и запрос/ответа вообще не поддерживает;
- экономия ресурсов – Docker-контейнер KubeMQ занимает всего 30 МБ;
- простота развертывания – KubeMQ просто добавить в среду разработки Kubernetes на локальной рабочей станции или масштабировать для развертывания в гибридной среде на сотнях локальных и размещенных в облаке узлов с помощью CLI-инструмента kubemqctl, аналогичному kubectl в Kubernetes;
- скорость – Kafka написан на Java и Scala, а KubeMQ – на Go, который работает быстрее, будучи языком системного программирования с оптимизацией использования памяти;
- самодостаточность – с KubeMQ можно забыть о брокерах и оркестраторах благодаря встроенному протоколу достижения консенсуса в распределенной среде Raft;
- удобство мониторинга – встроенная интеграция Prometheus и Grafana облегчает ежедневную работу администратора. Также можно просто и быстро подключить сторонние решения логирования и мониторинга, такие как Loggly, Fluentd, Elastic, Datadog, Jaeger и Open Tracing.
- интеграция в облачную инфраструктуру – поскольку Kafka не является встроенной частью ландшафта Cloud Native Computing Foundation (CNCF), интеграция с CNCF-инструментами часто не поддерживается и ее приходится настраивать вручную. В KubeMQ подключение может осуществляться через систему удаленного вызова процедур gRPC, отлично совместимую с Kubernetes. Собственный проприетарный механизм подключения в Кафка более сложен и требует дополнительной настройки.
Важно, что переход с Kafka на KubeMQ выполняется достаточно просто благодаря коннектору. Коннекторы приемника и источника KubeMQ настроены для преобразования сообщений из Kafka. Source-коннекторы принимают сообщения из исходного топика в качестве подписчика, конвертируют данные в формат сообщения KubeMQ и затем отправляют их во внутренний журнал. Target-коннекторы подписываются на выходной журнал, который содержит преобразованное сообщение, а затем отправляет сообщения в целевой топик Kafka.
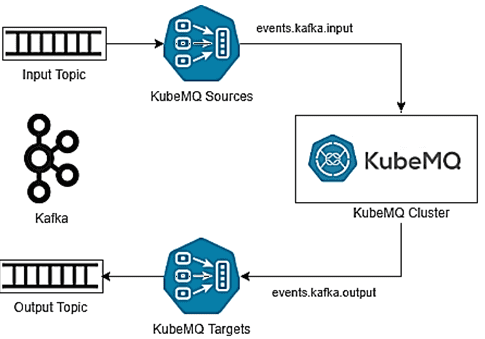
Важно, что KubeMQ поддерживает все шаблоны обмена сообщениями, что и Kafka. Поэтому при переходе с Kafka на KubeMQ нет необходимости в рефакторинге кода приложения и внесении сложных изменений в логику. Загрузить KubeMQ можно бесплатно с шестимесячной пробной версией для разработки. Для пользователей OpenShift, KubeMQ доступен в Red Hat Marketplace и облачных средах, включая Google Cloud Platform, AWS, Azure и DigitalOcean. Подробнее о сравнении Kafka с KubeMQ и важности операторов Kubernetes в этой платформе читайте в нашей новой статье.
Подробнее о том, как KubeMQ работает с операторами Kubernetes, мы поговорим в следующий раз. А освоить все тонкости администрирования и эксплуатации Apache Kafka для потоковой аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники