
Вчера мы рассматривали коннектор Neo4j к Apache Spark, который позволяет строить конвейеры аналитики больших данных с применением графовых алгоритмов. Продолжая эту тему, сегодня разберем варианты интеграции Neo4j с Apache Kafka с помощью шаблонных запросов Cypher в плагине и коннектора от Confluent, а также от каких конфигурационных параметров зависит пропускная способность этого обмена данными.
Способы интеграции Neo4j и Apache Kafka
Задача интеграции Neo4j с Apache Kafka возникает в следующих сценариях:
- нужен графовый анализ событий из множества источников, данные из которых агрегируются в потоковом режиме в топиках Kafka;
- захват изменения данных (CDC, Change Data Capture), когда требуется отправлять события обновления, т.е. измененные данные в лог с целью дальнейшего использования.
Технически интеграция Neo4j с Apache Kafka реализуется одним из следующих способов:
- плагин Neo4j, который поддерживает источники и приемники потоковых данных, а также потоковые процедуры;
- коннектор Kafka-Connect для платформы Confluent, который позволяет загружать данные в Neo4j из топиков Kafka через запросы Cypher, реализуя функцию приемника.
В один момент может работать только один способ, при одновременном использовании они будут генерировать ошибки. Плагин Neo4j чаще всего выбирают опытные пользователи этой NoSQL-СУБД. А разработчики и администраторы Kafka обычно предпочитают коннектор платформы Connect от Confluent. Что под капотом каждого способа, каковы его основные преимущества и недостатки, мы рассмотрим далее.
Коннектор Kafka Connect
Коннектор Kafka Connect к Neo4j развертывается отдельно от этой графовой СУБД. Это подходит для передачи данных из Kafka в Neo4j, которая выступает в качестве потребителя. При этом не поддерживается сбор измененных данных (CDC) из Neo4j. Основными достоинствами этого метода интеграции являются следующие:
- обработка данных осуществляется за пределами Neo4j, поэтому влияние памяти и ЦП не влияет на графовую СУБД;
- для опытных пользователей Kafka этот вариант проще – экосистема Confluent позволяет управлять всей платформой, в т.ч. подключение REST API для управления коннекторами, централизованное администрирование и мониторинг;
- возможность перезапуска приемника и источника без простоя Neo4j;
- обновление Neo4j-Streams без перезапуска кластера;
- повышенная безопасность благодаря улучшенному управлению действиями внешнего плагина.
Обратной стороной этих достоинств является ряд ограничений и недостатков Kafka Connect к Neo4j:
- при использовании Confluent Cloud, пока нет возможности разместить коннектор в облаке. Понадобится дополнительный компонент архитектуры Confluent Cloud, Neo4j и Connect Worker, который обычно размещается на отдельной виртуальной машине.
- снижение пропускной способности из-за задержки обработки и накладных расходов, связанных с передачей данных по сети. Код коннектора выполняет обычное подключение к Neo4j по протоколу bolt, что является источником дополнительных накладных расходов.
При использовании коннектора Kafka Connect Neo4j, рекомендуется работать с его самой последней версией, которая будет совместима со всеми релизами Neo4j.
При использовании коннектора важно, сколько данных извлекается из Kafka за раз и как они превращаются в пакет записей. Neo4j-Streams использует официальный клиент Java для Kafka для взаимодействия с очередью сообщений и запускает операцию poll() в Kafka. К этому клиенту применяются следующие конфигурационные настройки Kafka и Neo4j:
- Размер пакета (neo4j.batch.size) – количество сообщений, которые нужно включить в один транзакционный пакет. По умолчанию размер пакета составляет 1 МБ. Например, при наличии больших записей размером 200 КБ, в пакет по умолчанию вместится не более 5 записей.
- Максимальное количество записей в транзакции (kafka.max.poll.records) – количество записей, используемых для каждой транзакции в Neo4j;
- Максимальный объем данных, возвращаемых сервером для каждого раздела (kafka.max.partition.fetch.bytes) – записи загружаются партиями. Если первый пакет записей в первом непустом разделе выборки превышает этот предел, пакет все равно будет возвращен, чтобы гарантировать, чтобы потребитель мог продолжить работу.
- batch.parallelize – возможность параллельного выполнения пакетов, которая может повысить пропускную способность, но не гарантирует упорядочение при распараллеливании и имеет риск ошибок блокировки;
- Таймаут выполнения пакета (neo4j.batch.timeout.msecs) влияет на продолжительность выполнения пакетов;
- Время выполнения poll-опроса (kafka.max.poll.interval.ms), которое ограничивает максимальное количество записей опроса.
При интеграции Apache Kafka с Neo4j важно найти баланс между использованием памяти и общими накладными расходами на транзакции. Меньшее количество больших пакетов в целом позволяет быстрее импортировать данные в Neo4j, но требует больше памяти. Чем меньше полезная нагрузка, тем больше пакет. Каждый пакет представляет собой транзакцию в памяти, поэтому произведение размера сообщения на размер пакета определяет, сколько кучи в памяти нужно для транзакций. Неоптимальная конфигурация этих параметров может вызвать серьезные проблемы с производительностью. Например, получение 1 записи в результате опроса и ее пакетная отправка в Neo4j увеличит время транзакционных накладных расходов.
Можно установить максимальное количество записей опроса, равное желаемому размеру пакета транзакций (neo4j.batch.size). Однако, чтобы избежать проблем с памятью, рекомендуется задать параметру kafka.max.partition.fetch.bytes значение, равное произведению максимального количества записей опроса на среднее количество байтов в записи + 10%.
Плагин Neo4j-Streams
Будучи плагином этой графовой СУБД, neo4j-streams работает внутри нее и может как потреблять сообщения из Kafka, так и отправлять записи в топики этой системы с помощью следующих компонентов:
- Streams Source – транзакционный обработчик событий Neo4j, который отправляют данные в топики Kafka;
- Streams Sink – приложение Neo4j, которое принимает данные из топиков Kafka в Neo4j с помощью типовых запросов Cypher;
- потоковые процедуры потоков Neo4j: publish, которая позволяет настраивать поток сообщений из Neo4j в нужную среду, и streams.consume, чтобы получать сообщения из заданного топика.
Плагин neo4j-streams предоставляет следующие преимущества:
- проще для пользователей Neo4j;
- возможность как получать данные из Kafka, так и записывать их в эту систему;
- гибкая настройка потоков сообщений с помощью процедур publish и streams.consume;
- высокая пропускная способность из-за отсутствия задержки обработки данных и накладных расходов на преобразования и сетевую передачу.
Недостатками этого метода интеграции являются следующие:
- потребление памяти и ЦП на сервере Neo4j;
- необходимость отслеживать идентичность конфигурации для всех участников кластера;
- меньше возможностей управлять плагином, т.к. он работает внутри базы данных, а не под определенной учетной записью пользователя.
При выборе этого метода интеграции следует учитывать совместимость между версиями плагина и самой СУБД.
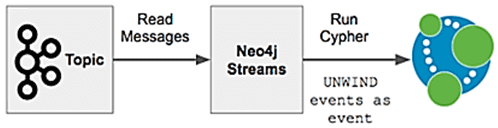
В этом способе интеграции критическим фактором является количество элементов в массиве событий для каждой транзакции. Размер кучи влияет на то, насколько большими могут быть транзакции из Kafka без потери других выполняемых запросов. Размер кэша страницы влияет на количество «горячих» данных и влияет на шифрованные запросы, выполняемые плагином neo4j-streams.
Примечательно, что сами разработчики Neo4j рекомендуют использовать коннектор Kafka Connect от Confluent для интеграции этих систем. С версии Neo4j 4.3 плагин neo4j-streams будет считаться устаревшим и не будет поддерживаться.
Освойте все тонкости администрирования и эксплуатации Apache Kafka и Neo4j для потоковой аналитики больших данных с помощью графовых алгоритмов на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
- Графовые алгоритмы. Бизнес-приложения
- Apache Kafka для разработчиков
- Администрирование кластера Kafka
Источники

