
По запросу одного из наших клиентов, этой статьей мы открываем серию публикаций про применение технологий Big Data и Machine Learning в торговле быстрооборачиваемых товаров повседневного спроса (FMCG, Fast moving consumer goods). Сегодня рассмотрим, как большие данные, машинное обучение и прочие методы искусственного интеллекта используются в производстве и продаже газированных напитков...
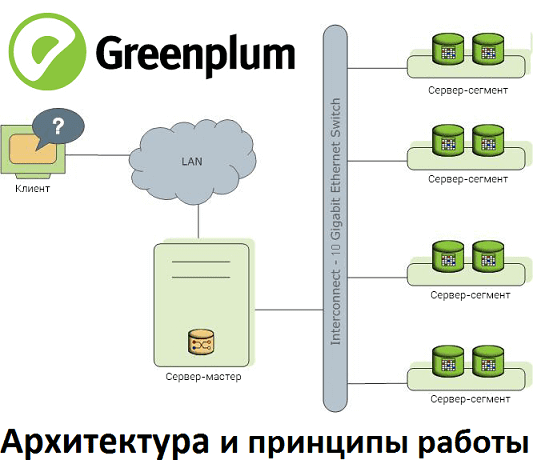
В этом материале рассмотрим реализацию массово-параллельной архитектуры для хранения и аналитической обработки больших данных на примере популярной Big Data СУБД Greenplum. Прочитав эту статью, вы поймете, почему MPP-базы потребляют много ресурсов и как связано число сегментов со скоростью работы кластера. MPP, Greenplum и PostgreSQL Напомним, СУБД Greenplum – это типичный представитель...

Сегодня поговорим про достоинства и недостатки массово-параллельной архитектуры для хранения и аналитической обработки больших данных, рассмотрев Greenplum и Arenadata DB. Читайте в нашей статье, что такое MPP-СУБД, где и как это применяется, чем полезны эти Big Data решения и с какими проблемами можно столкнуться при их практическом использовании. Что MPP-СУБД...

Вчера мы рассказывали про применение Arenadata DB в крупной отечественной сети розничного ритейла. Сегодня рассмотрим еще один Big Data продукт от российской компании Аренадата, который Х5 Retail Group использует для быстрой аналитики больших данных. Читайте в нашей статье, что такое Arenadata QuickMarts и при чем здесь ClickHouse от Яндекса. Что...

Продолжая разговор про успехи применения отечественных Big Data продуктов, сегодня мы рассмотрим пример использования Arenadata DB в одной из ведущих отечественных компаний розничного ритейла. Читайте в нашей статье про особенности внедрения распределенной отказоустойчивой MPP-СУБД для аналитики больших данных в Х5 Retail Group. Зачем ритейлеру еще одно Big Data решение: специфика...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...

Сегодня мы поговорим про продукты компании Arenadata – отечественного разработчика дистрибутива Apache Hadoop (ADH), массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB) и других Big Data платформ. Читайте в нашей статье, где внедрены эти решения и какую пользу они уже успели принести бизнесу. Облака и банк: 3...
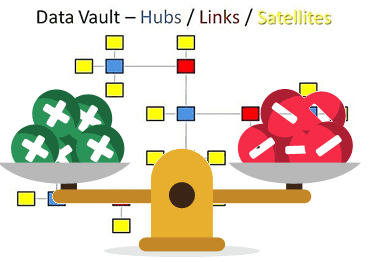
В этой статье мы рассмотрим основные плюсы и минусы Data Vault – популярного подхода к моделированию сущностей при проектировании корпоративных хранилищ данных (КХД). Читайте сегодня, почему промежуточные базы перед витринами данных упрощают ETL-процессы, за счет чего обеспечивается отсутствие избыточности и как много таблиц могут усложнить жизнь архитектора Big Data. Чем...
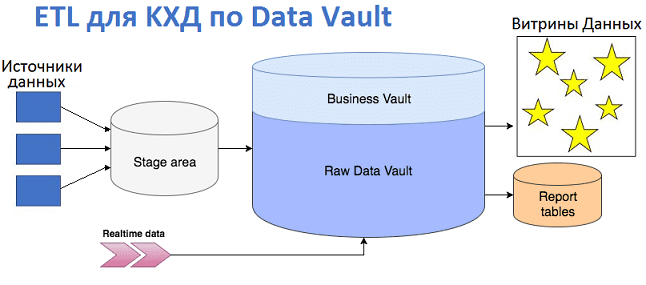
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения...
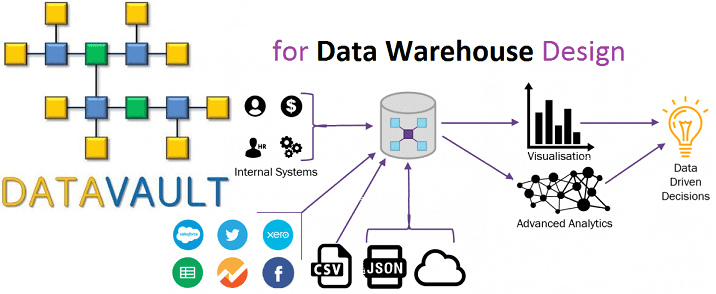
Вчера мы рассмотрели, что такое Data Vault, почему возникла эта модель и чем она полезна при проектировании архитектуры корпоративных хранилищ данных (КХД) и озер данных (Data Lake). Сегодня разберем ключевые понятия Data Vault и поговорим про возможности Data Vault 2.0 для области больших данных (Big Data). Ключевые понятия Data Vault...