 1022
1022 
Содержание
Читайте в нашей сегодняшней статье, как Apache Kafka Streams помогает быстро создавать приложения для обработки потоков Big Data без кластера Кафка, работать с состояниями распределенных программ без базы данных, эффективно тестировать и разворачивать потоковые микросервисы согласно DevOps-подходу, а также реальные кейсы практического применения этой технологии.
Что такое Apache Kafka Streams и зачем она нужна
Apache Kafka Streams – это клиентская библиотека для разработки приложений и микросервисов, в которых входные и выходные данные хранятся в кластерах Кафка. Она сочетает в себе простоту написания и развертывания типовых приложений Java и Scala на стороне клиента с преимуществами кластерной технологии Kafka на стороне сервера [1] в соответствии с DevOps-подходом. Подробнее о том, как API-интерфейс Кафка Стримс помогает DevOps-Инженеру и разработчику Big Data систем, читайте в нашей новой статье.
Apache Kafka Streams отлично подходит для решения следующих прикладных задач:
- разработка распределенных приложений без кластеров с возможностью последующего масштабирования [2];
- получение доступа к состоянию приложения без использования традиционных хранилищ (баз данных, кэшей и пр.) [2];
- взаимодействие с клиентами в режиме реального времени, например, для оперативного оповещения о наступлении каких-либо событий [3] или построения прогнозных моделей предиктивной аналитики с минимальной задержкой [4];
- многократные и непрерывные агрегация, группировка и свертка отфильтрованных результатов в определенном временном промежутке – к примеру, при вычислении количества произведенных биржевых операций с акциями конкретной компании за последние 10 минут или числа пользователей, кликнувших на новый рекламный баннер в течение только что прошедшей четверти часа [5];
- DevOps-реализация потоковых микросервисов с разделяемым состоянием, каждый из которых является отказоустойчивым и высокодоступным источником достоверной информации о состоянии объектов в системе Big Data – например, для анализа устойчивости сервиса к хакерским атакам [6].
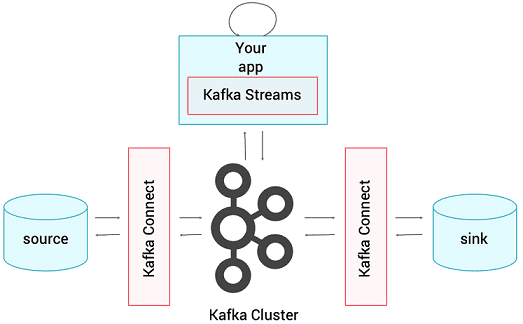
Где в Big Data применяется Кафка Стримс: практические примеры использования
Итак, главным образом, Apache Kafka Streams нужен для управления запросами о состоянии приложений в режиме реального времени и безкластерной разработки распределенных сервисов с последующим масштабированием. По этим прикладным направлениям можно отметить следующие наиболее яркие кейсы применения библиотеки Кафка Стримс [1]:
- американская ежедневная газета The New York Times использует Apache Kafka Streams для хранения и распространения в реальном времени опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей (сервисы подписки, мобильные приложения, новостные агрегаторы и пр.);
- социальная сеть фотоизображений Pinterest с помощью Apache Kafka и Кафка Стримс смогла масштабировать собственную предиктивную систему бюджетирования своей рекламной инфраструктуры в режиме реального времени, повысив точность прогнозов по финансовым расходам.
- один из крупнейших банков Нидерландов, Rabobank применяет Кафка Стримс для оповещения клиентов в режиме реального времени о финансовых событиях.
- крупная японская ИТ-компания Line Corporation использует Кафка Стримс для надежного преобразования и фильтрации топиков Кафка, позволяя потребителям эффективно использовать подтопики (sub topics), сохраняя простоту обслуживания благодаря своей сложной, но минимальной базе кода.
- глобальная веб-платформа для поиска отелей Trivago с помощью Apache Kafka, Kafka Connect и Кафка Стримс обеспечивает свободный доступ к корпоративным данным для всех своих разработчиков. Кафка Стримс поддерживает некоторые участки такого DevOps-конвейера, позволяя использовать различные источники данных.
В России библиотека Кафка Стримс активно используется в корпоративных Big Data системах, которые применяются в крупных data-driven компаниях (Сбербанк, Альфа-Банк, Яндекс, Авито и множество других частных и государственных организаций).
Подробности применения Apache Kafka Streams в реальных проектах больших данных разбираются на наших практических курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники
- https://kafka.apache.org/23/documentation/streams/
- https://www.meetup.com/ru-RU/Moscow-Kafka-Meetup/events/260976977/
- https://www.confluent.io/blog/real-time-financial-alerts-rabobank-apache-kafkas-streams-api/
- https://medium.com/@Pinterest_Engineering/using-kafka-streams-api-for-predictive-budgeting-9f58d206c996
- https://habr.com/ru/company/piter/blog/457756/
- https://habr.com/ru/company/piter/blog/449928/

