 605
605 
Содержание
Мы уже рассказывали, зачем нужна интеграция Apache Kafka и Spark Streaming. Сегодня рассмотрим, как технически организовать такой Big Data конвейер по непрерывной обработке потоковых данных в режиме реального времени.
Способы интеграции
Наладить двустороннюю связь между Apache Kafka и Spark Streaming возможны следующими 2-мя способами:
- получение сообщений через службу синхронизации Zookeeper с помощью высокоуровневого API Кафка;
- непосредственная передача данных путем отслеживания смещений в разделах (partition) топика (topic) Кафка через контрольные точки (checkpoints).
Эти подходы существенно отличаются друг от друга особенностями реализации, производительностью и семантикой. Второй подход считается более эффективным благодаря отсутствию посредников в передаче данных между двумя системами. Далее мы рассмотрим каждый вариант более подробно. В обоих случаях, прежде всего, необходимо задать конфигурацию связи Kafka – Spark Streaming [1].
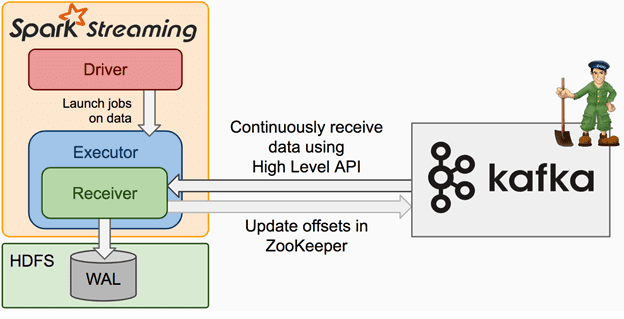
Интеграция Apache Kafka и Spark Streaming через получателей сообщений и Zookeeper
В 1-м варианте интеграции Кафка создает поток входящих сообщений, отправляя данные получателю (Receiver) на обработку в Спарк. В Spark Streaming запускаются задания (jobs) на исполнение (Executor), в рамках которых обрабатываются данные. Для исключения потери данных необходимо дополнительно подключить журнал опережающей записи (WAL, Write-Ahead Log), который синхронно сохраняется всю информацию от Kafka в распределенной файловой системе, например, HDFS. Благодаря этому даже при сбое все данные можно восстановить [1].
WAL считается популярным методом обеспечения целостности информации в базах данных, суть которого в предварительном логгировании изменений файлов с данными. Модифицированные данные сохраняются только после того, как изменения занесены в журнал. Таким образом, можно восстановить информацию: любые изменения, которые не были применены к страницам с данными, могут быть воссозданы из записей журнала путем операции повтора (наката), REDO.
На практике журналирование может снизить производительность, если данные файловой системы, а не базы данных, сохраняются на диск. Тем не менее, журналируемые файловые системы увеличивают степень надежности и сокращают время восстановления в случае сбоя [2].
Итак, Kafka создает множество входных потоков Big Data, отправляя их получателю в Spark Streaming и по API сохраняя в Zookeeper потребленные считываемые фрагменты. При этом информация реплицируется дважды: сначала в Kafka, а затем — в журнале опережающей записи. Такая цепочка надежно исключает риски потери данных, но провоцирует вероятность, что отдельные записи могут быть потреблены дважды из-за несогласованности между механизмом передачи данных Kafka – Spark Streaming и считыванием фрагментов в Zookeeper [1].
Kafka Consumer: что такое потребитель Кафка
В вышеописанном случае передача сообщений от Kafka в Spark Streaming выполняется через API потребления. Поясним, что под потребителем Кафка (Consumer) подразумевается приложение, которое считывает данные из топика Kafka. Как правило, Kafka Consumer подписывается на 1 или несколько топиков в кластере Кафка, чтобы считывать оттуда токены или сообщения. При установке связи для определения работоспособности кластерного узла используется механизм сердцебиений (Heartbeat). В случае отсутствия таких периодических сигналов Kafka Consumer не подключается к узлу, а балансировщик нагрузки должен перераспределить ресурсы [3].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
15 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
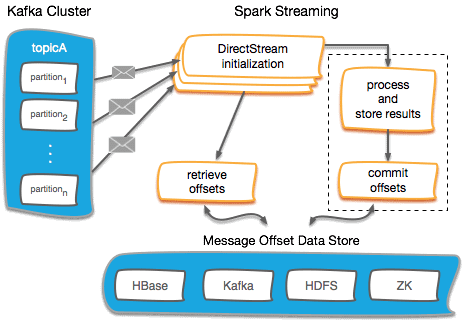
Непосредственная интеграция Apache Kafka и Spark Streaming: прямой подход
Прямой метод интеграции Кафка и Спарк, доступный в Spark 1.3 для Scala и Java API, а также в Spark 1.4 для Python API, считается более эффективным и дает надежные сквозные гарантии. В этом случае выполняется периодический опрос Kafka о смещениях вычитанных данных (offsets) по каждому разделу или топику, а не доставка данных через получателей. Для правильной обработки каждого пакета определяется размер считываемого фрагмента. А считывание диапазонов смещения из Kafka реализуется через вышеописанный API потребления. Таким образом, весь процесс напоминает считывание файлов из файловой системы [1].
Такой метод, в отличие от вышеописанного варианта с получателями, обладает следующими преимуществами:
- Упрощенный параллелизм: не требуется создавать множество входных потоков Kafka и объединять их. Все операции обработки информации в Спарк выполняются через специальные структуры данных – распределенные RDD-таблицы (Resilient Distributed Datasets), неизменяемые коллекции объектов, которые могут быть как виртуальными, так и материальными (в памяти или на диске). Каждый набор данных в RDD разделен на логические разделы (partitions), которые являются минимальными объемами для обработки на узле кластера [4]. Прямая интеграция Kafka – Spark Streaming создаст RDD-сегменты по количеству потребителей Kafka, обеспечивая параллельное считывание данных. Таким образом, реализуется соответствие «один к одному» между сегментами Kafka и RDD, что понятнее понятнее и проще в настройке [1]. Подробнее о том, что такое RDD и чем эта структура данных отличается от dataset и dataframe, читайте здесь.
- Эффективность за счет отсутствия двойного реплицирования. Напомним, в случае с получателями для исключения рисков потери данных используется хранение информации в журнале опережающей записи (WAL). Прямая интеграция Kafka – Spark Streaming в случаае сбоев и отказов системы предполагает непосредственное восстановление информации прямо из кластера Кафка [1].
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
96 000
- Исключение дублирования сообщений за счет стратегии «строго однократная доставка» — считываемые фрагменты отслеживаются в Kafka – Spark Streaming с помощью механизмов контрольных точек (checkpoints), устраняя несогласованность между Spark Streaming и Zookeeper/Kafka. Таким образом, даже при отказах системы, Spark Streaming получает каждую запись строго однократно. Отметим, что в этом случае нужна гарантия атомарности транзакции, когда во внешнем хранилище (HDFS, HBase, S3 и других сторонних системах хранения информации) сохраняются сами результаты и смещения топика Кафка. Автоматически эти смещения (offset) в Zookeeper не обновляются, поэтому требуется самостоятельно обращаться к каждому пакету, обновляя Зукипер [1].
Освойте искусство администрирования Apache Kafka, Spark и другие технологии больших данных на наших практических курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
[elementor-template id=»13619″]
Источники

