 1445
1445 
Содержание
Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data.
Что такое Apache Parquet и как он работает: краткий ликбез
Напомним, что Apache Parquet — это бинарный, колоночно-ориентированный (столбцовый) формат хранения больших данных. Созданный специально для экосистемы Hadoop, он позволяет эффективно сжимать информацию и считывать файлы частично, по мере необходимых столбцов. Паркет предоставляет возможность задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их изобретения и реализации [1]. Наряду с Apache Avro, Parquet – это весьма популярный формат хранения файлов Big Data, который на практике очень часто используется в Kafka, Spark и Hadoop.
Паркет поддерживает наиболее распространенные типы данных (boolean, int32, int64, int96, float, double, byte_array) и реализует многоуровневую систему разбиения файлов на части (группы строк, блок данных столбца и разбиение столбцов по страницам), благодаря чему обеспечивается высокая скорость работы с данными [2].
Достоинства и недостатки Паркет
Колоночная специфика хранения данных и многоуровневая система разбиения файлов на части обеспечивает следующие преимущества формата Parquet:
- экономия места для хранения данных за счет эффективного сжатия информации по столбцам – в частности, по сравнению с Apache Avro, другим популярным форматом Big Data, Паркет сжимает данные примерно в 3,5 раза лучше [3];
- высокая скорость чтения данных и отработки запросов, извлекающих определенные значения столбцов вместо считывания всего большого файла, что значительно ускоряет работу аналитика Big Data [1];
- возможность реализации собственных схем данных и применения различных методов кодирования к различным столбцам [1];
- поддержка нескольких языков программирования (C++, Java, Python, PHP и т.д.), а также популярных фреймворков, например, Apache Thrift, что повышает гибкость формата [1];
- возможность хранения данных не только в HDFS, для которой Parquet и был создан изначально, но и в других файловых системах (GlusterFs, NFS и пр.) [1];
- простота и удобство работы с файлами с помощью операций перемещения, резервного копирования и реплицирования [1];
- поддержка Apache Spark «по умолчанию» (из коробки) обеспечивает возможность сохранить файл Big Data в другое облачное или локальное хранилище данных [1].
Поскольку недостатки являются продолжением достоинств, отметим следующие минусы формата Apache Parquet [2]:
- строгая типизация данных – в связи с колоночной ориентацией файл формата Паркет ведёт себя как неизменяемая таблица или база данных, когда для столбца четко определён тип данных, при этом невозможно его изменить или скомбинировать, например, объединив вложенный json с простым строковым значением.
- отсутствие встроенной (нативной) поддержки в других фреймворках Big Data, кроме Apache Spark;
- отсутствие возможности отслеживать изменение данных и эволюцию схемы, в отличие от, например, Avro, другого популярного форматом Big Data, изменение схемы данных которого легко прослеживается через графический интерфейс Sсhema Registry в Apache Kafka Confluent (об этом мы писали здесь). Отметим, что Apache Spark позволяет объединять схемы данных при изменении их со временем, но для этого требуется указать специальную опцию при чтении. А, чтобы что-то изменить в уже существующим файле, его придется перезаписать или добавить новую колонку.
- не поддерживаются транзакции, поскольку, несмотря на некоторую схожесть с базой данных (в части строгой типизации), файлы формата Паркет – это частично размеченная информация.
- сложность частичной потоковой передачи данных – необходимо передавать всю «группу строк»;
- сильная привязка к метаданным – при повреждении, потере метаданных или изменении контрольной суммы группы строк, блока данных столбца или страницы данных, вся смысловая информация будет утеряна. Отметим, что, отключив в файловой системе вычисления контрольных сумм на каждом из уровней разбиения, можно значительно повысить производительность;
- Паркет не является человекочитаемым форматом, в отличие, например, от JSON или CSV.
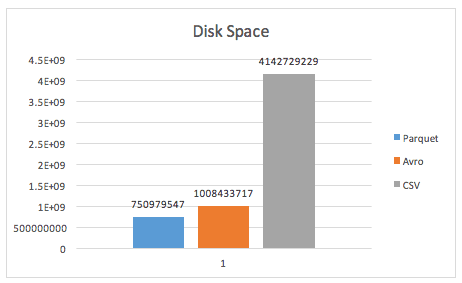
Сравнение Parquet с другими форматами хранения больших данных
Проанализировав результаты сравнения формата Паркет с Авро, детально представленные в [3], можно сделать выводы, что Apache Parquet значительно быстрее Avro. Было проведено тестирование со следующими наборами данных:
- широкий датасет в виде CSV-файла размером 194 ГБ, содержащего 103 столбца и 694 миллиона строк;
- узкий датасет в виде CSV-файла размером 3,9 ГБ (3 столбца и 82,8 миллиона строк).
Сравнение выполнялось в рамках Apache Spark 1.6, который в своей базовой поставке поддерживает Parquet, а для Avro и CSV были установлены соответствующие плагины. Для тестирования использовался кластер на основе Cloudera Distribution Hadoop (CDH) 5.5.x, состоящий из более чем 100 узлов. Производительность каждого формата оценивалась путем выполнения операций записи набора данных в файл, обработок простых и сложных SQL-подобных запросов, подсчета количества строк, обработки полного набора данных и расхода дискового пространства [3].
В рамках этого тестирования были получены следующие результаты [3]:
- запись данных в файл и подсчет количества строк в узком датасете занимают примерно одинаковое время в форматах Паркет и Авро, а в широком наборе данных Parquet работает значительно быстрее;
- в случае сложных запросов к подмножеству столбцов, в частности, GROUP BY, а также при обработке полного набора данных с помощью функции MAP() информация в формате Паркет обрабатывается за гораздо меньшее время по сравнению с Apache Avro и CSV – это характерно как для узкого, так и для широкого датасета;
- особенно впечатляют итоги тест на сжатие данных, когда Parquet сжал CSV-файл размером 194 ГБ до 4,7 ГБ, а Avro – до 16,9 ГБ, что соответствует высокой степени сжатия: 97,56% и 91,24% соответственно.
Таким образом, Apache Parquet в очередной раз подтвердил звание наиболее производительного формата хранения файлов Big Data и удобство работы с такими файлами с помощью фреймворка Apache Spark. О других популярных форматов больших данных, Apache AVRO, ORC, Sequence и RCFile читайте в нашей следующей статье.
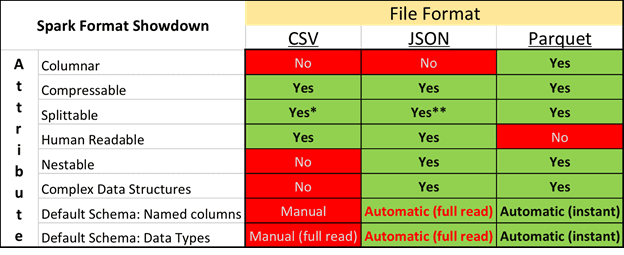
Как работать с Apache Parquet и другими форматами больших данных, вы узнаете на наших практических курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
- INTR: Основы Hadoop
- HDDE: Hadoop для инженеров данных
- HADM: Администрирование кластера Hadoop
- KAFKA: Администрирование кластера Kafka
- SPARK: Администратор кластера Apache Spark
Источники

