 630
630 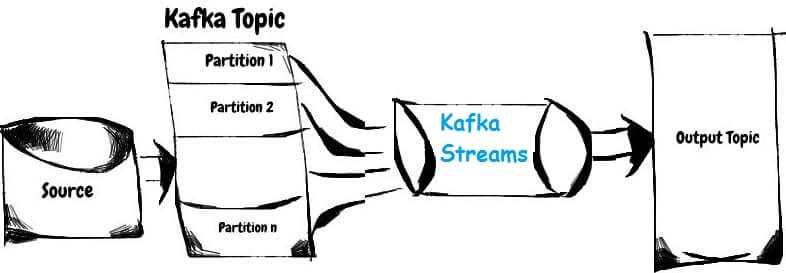
Сегодня мы поговорим про базовые понятия Apache Kafka Streams: потоки, таблицы и топики Кафка. Читайте в нашей статье, как Stream, Table и Topic связаны между собой, чем они похожи, когда таблица становится потоком и почему это обеспечивает эластичность и отказоустойчивость распределенных потоковых приложений Big Data.
Что такое таблица, топик и поток Kafka
Напомним, что одним из ключевых достоинств Apache Kafka является возможность отслеживания каждого произошедшего события, т.е. эта платформа обработки информационных потоков является объективным источником исторических данных. На этом основаны следующие базовые концепции Кафка, суть которых отличаются от аналогичных терминов реляционных баз данных [1]:
- Топик (Topic) – неограниченная последовательность пар «ключ-значение» (key-value), где ключи и значения — это обычные массивы байтов (<byte[], byte[]>);
- Поток (Stream) – конструкция 1-го порядка, полная история всех случившихся событий, топик со схемой данных (schema), где ключи и значения уже не байтовые массивы, а имеют определённые типы;
- Таблица (Table) – конструкция 2-го порядка, агрегация событий на текущий момент, агрегированный поток данных.
|
Понятие |
Есть разделы (partition) |
Ограничения на размер |
Есть порядок |
Изменчивость |
Уникальный ключ |
Есть схема |
|
Topic |
+ |
— |
+ |
— |
— |
— |
|
Stream |
+ |
— |
+ |
— |
— |
+ |
|
Table |
+ |
— |
— |
+ |
+ |
+ |
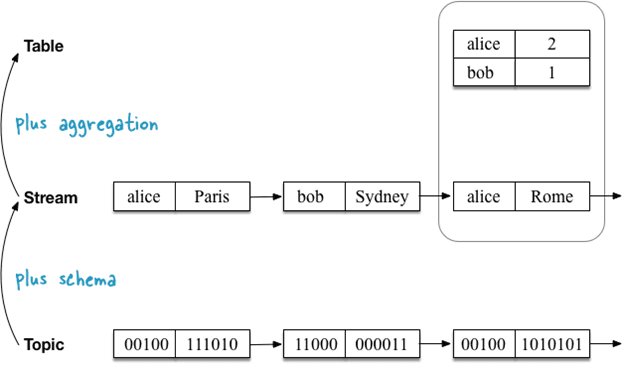
Таблично-поточный дуализм Apache Kafka Streams
Аналогично известному всем со школьных времен кванто-волновому дуализму в физике, когда материальные микроскопические объекты могут при одних условиях проявлять свойства классических волн, а при других — вести себя, как типовые частицы [2], в Кафка и Apache Kafka Streams присутствует двойственность таблиц и стримов. При этом поток можно рассматривать как таблицу и наоборот, что позволяет сделать приложения более гибкими, реализовать отказоустойчивую обработку с отслеживанием состояния и выполнять интерактивные запросы к последним результатам обработки [3].
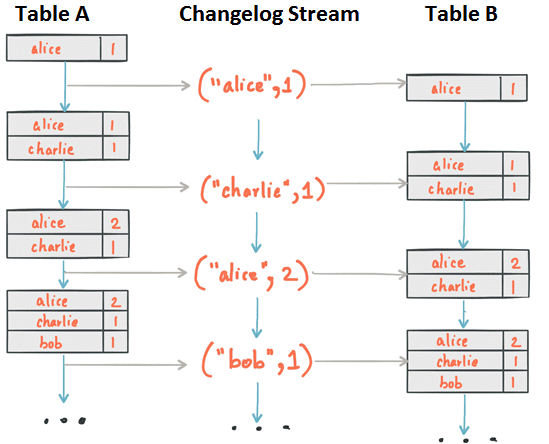
В частности, каждое изменение таблицы Кафка заносится во внутренний поток изменений (changelog stream), в котором фактически выполняется множество вычислений в Apache Kafka Streams и KSQL. Это позволяет Kafka Streams и KSQL правильно перерабатывать исторические данные в соответствии с семантикой обработки времени события. Отметим, что в Kafka Streams таблицу можно явно преобразовывать в поток изменений (changelog stream) с помощью функции KTable#toStream(). При этом, как и в KSQL, понятие топика в Кафка Стримс отсутствует, концепции Stream соответствует абстракция KStream, а Table – KTable [1].
Потоки изменений Кафка Стримс непрерывно резервируются (back up) и сохраняются в виде топиков Kafka, обеспечивая эластичность и отказоустойчивость. Это позволяет перемещать задачи между узлами кластера, виртуальными машинами или контейнерами без потери данных в течение всех операций, независимо от необходимости сохранения состояний (stateful) или ее отсутствия (stateless). Таблица является частью состояния (state) потокового приложения Kafka Streams или запроса KSQL, благодаря чему Кафка переносит между узлами кластера не только код обработки, но и само состояние приложения с помощью changelog stream. Например, когда требуется переместить таблицу с клиентской машины A на машину B, то на узле B таблица реконструируется из её потока изменений в состояние, идентичное исходному (на машине A) [1].
Как именно понятия Stream, Table и Topic помогают распараллелить задачи потоковой обработки больших данных, читайте в нашей следующей статье. А прикладные тонкости работы с Apache Kafka Streams вы сможете освоить на наших специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
[elementor-template id=»13619″]
Источники
- https://habr.com/ru/company/skbkontur/blog/353204
- https://ru.wikipedia.org/wiki/Корпускулярно-волновой_дуализм
- https://kafka.apache.org/23/documentation/streams/core-concepts

