 1159
1159 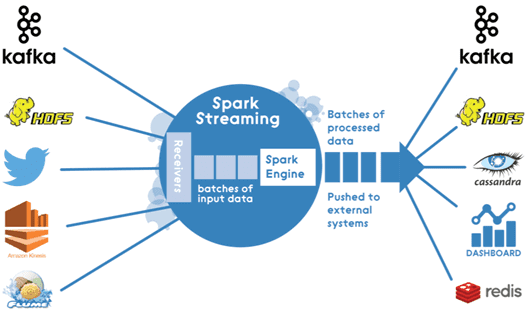
Содержание
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming.
Что такое Spark Streaming и для чего он нужен
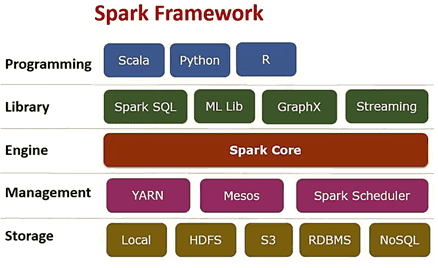
Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых данных. Спарк входит в экосистему проектов Hadoop и позволяет осуществлять распределённую обработку неструктурированной и слабоструктурированной информации. Изначально Спарк был написан на языке программирования Scala, затем добавилась часть компонентов на Java. Дополнительно к этим языкам, фреймворк также предоставляет API для Python и R [1].
Apache Spark – это многокомпонентная система из следующих элементов:
- Ядро (Spark Core), которое использует специализированные примитивы для рекуррентной обработки в оперативной памяти, что значительно ускоряет многократный доступ к загруженным в память пользовательским данным [1];
- Spark SQL – модуль, который позволяет выполнять SQL-запросы над данными, сочетая реляционную обработку с процедурным API [2];
- Spark Streaming — надстройка для обработки потоковых данных, о которой мы расскажем подробнее дальше;
- Spark MLlib – набор библиотек машинного обучения (Machine Learning);
- GraphX – библиотека для распределённой обработки графов.
Спарк может работать как в среде кластера Hadoop под управлением YARN, так и без компонентов ядра хадуп. Спарк поддерживает несколько распределённых систем хранения (HDFS, OpenStack Swift, NoSQL-СУБД Cassandra, Amazon S3) и, в отличие от классического обработчика ядра Hadoop, который реализует двухуровневую концепцию MapReduce с дисковым хранилищем, Спарк работает с оперативной памятью, что существенно ускоряет вычисления [1].
Зачем нужна интеграция Apache Kafka и Spark Streaming
Как мы уже рассказывали в статье про основы Кафка для начинающих, Apache Kafka позволяет собирать и агрегировать непрерывные потоки Big Data от разных источников: устройств Internet of Things, приложений и сервисов. Однако, чтобы эти большие данные были полезны в прикладном смысле, их необходимо обрабатывать и анализировать. Apache Kafka не предназначена для интеллектуальной обработки данных, поэтому необходимы другие средства Big Data. В таком случае целесообразно использовать Spark Streaming, который будет обрабатывать потоки сообщений Кафка и записывать результат обработки в облачное хранилище, базу данных или распределенную файловую систему типа HDFS.
Подобная задача актуальна, например, для банков и других финансовых организаций, которым необходимо обрабатывать потоки входящих транзакций в режиме реального времени по всем своим филиалам. Это может быть сделано с целью оперативного расчета открытой валютой позиции для казначейства, лимитов или финансового результата по сделкам и т.д.
Несмотря на позиционирование Spark Streaming в качестве средства потоковой обработки, на практике он реализует «микропакетный» подход (micro-batch), когда поток данных интерпретируется как непрерывная последовательность небольших пакетов информации. Spark Streaming принимает данные из разных источников и объединяет их в небольшие пакеты через регулярные интервалы времени.
В начале каждого интервала (batch interval) создается новый пакет, и любые данные, поступившие в течение этого времени, включаются в пакет. В конце интервала увеличение пакета прекращается. Размер batch interval определяется заранее и называется интервалом пакетирования. Для повышения отказоустойчивости приложения используются контрольные точки (checkpoints). Благодаря этому, когда Spark Streaming требуется восстановить утраченные данные, нужно только вернуться к последней контрольной точке и возобновить вычисления от нее [3]. Входящий в состав Apache Спарк движок Spark Engine передает пакеты обработанной информации в базу данных, облачные сервисы или файловые хранилища, а набор библиотек для машинного обучения Spark MLlib позволяет использовать эти данные в моделировании Machine Learning. Также средствами Spark SQL можно выполнять различные аналитические запросы. Таким образом, интеграция Apache Kafka и Spark Streaming обеспечивает непрерывный конвейер (pipeline) сбора и интеллектуальной обработки потоков Big Data в режиме реального времени. А как технически реализуется обмен данными между Apache Kafka и Spark Streaming, читайте в нашей следующей статье.
Еще больше знаний об Apache Kafka, Спарк и других технологиях больших данных на наших практических курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники

