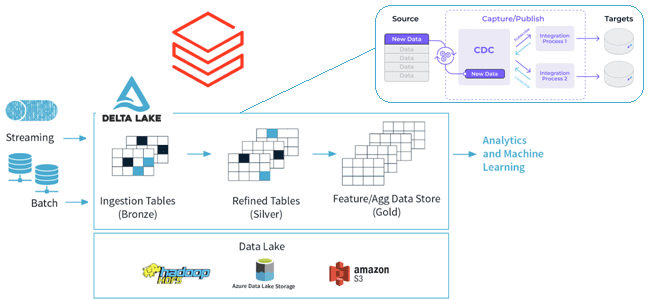
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...
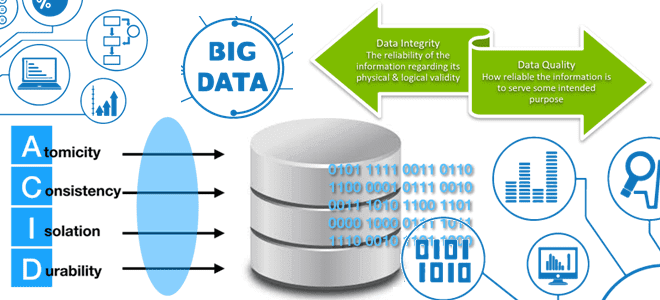
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...
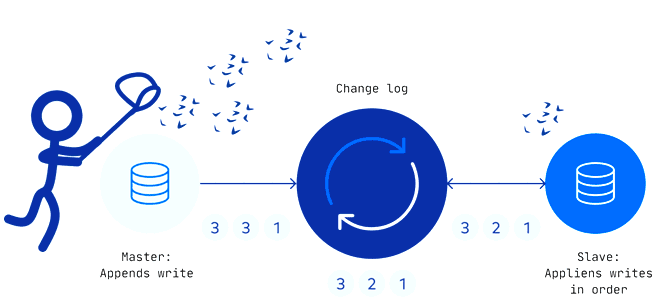
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...
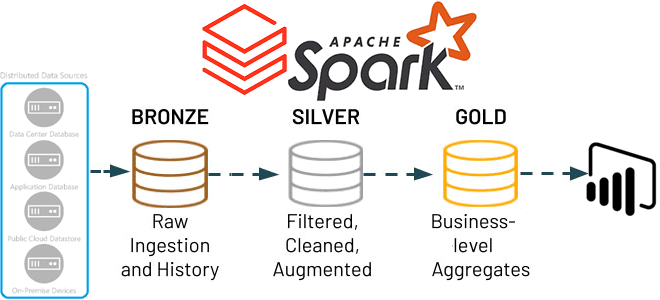
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...
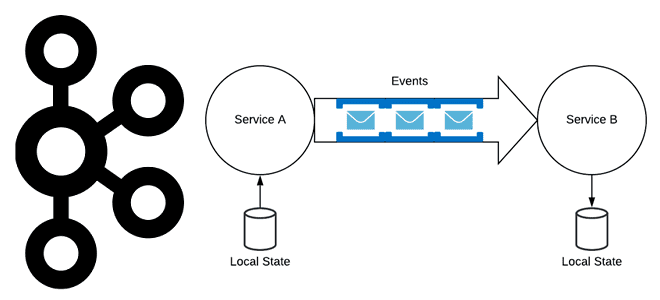
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...
Недавно мы писали про сравнения технологий потоковой аналитики больших данных и аналитических баз данных реального времени на примере сравнения ksqlDB и Rockset. Продолжая этот разговор про архитектуру данных и приложений, сегодня рассмотрим сходства и отличия потоковых баз данных со stateful-приложениями обработки событий в реальном времени. 2 технологии потоковой обработки: stateful-приложения...