 741
741 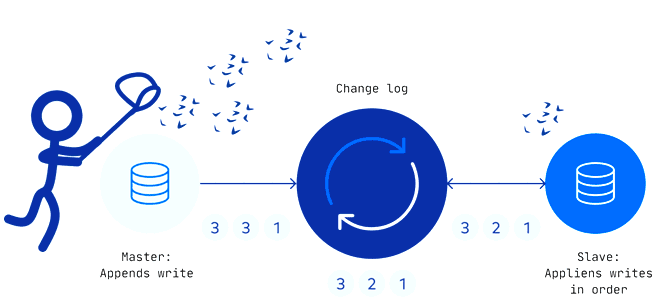
Содержание
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture.
Паттерны и принципы реализации захвата измененных данных
Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных продолжают стремительно расти, а бизнес-пользователям нужен непрерывный доступ к аналитической информации. Поэтому извлечение всех базовых данных в режиме реального времени становится нецелесообразным из-за долгой передачи большого объема данных по сети. Поэтому вместо полного копирования данных из систем-источников в корпоративное хранилище или озеро более выгодно применять решения идентификации и репликации журнала изменений для поддержки приложений аналитики в режиме, близком к реальному времени.
Технически такая стратегия реализуется с помощью технологии захвата измененных данных (Change Data Capture, CDC) с помощью готовых или самописных решений. Примерами готовых CDC-решений можно назвать Debezium, Oracle Change Data Capture, PowerExchange CDC от Informatica, Hevo Data, IBM Infosphere, Qlik Replicate, Talend, Oracle GoldenGate, StreamSets, а также прочие вендорские и open-source продукты. Пример репликации измененных данных в реальном времени с Apache Kafka и Debezium в Confluent Cloud мы рассматривали здесь.
Впрочем, некоторые дата-инженеры разрабатывают собственные CDC-решения, используя следующие подходы для вычисления измененных данных:
- временные метки, которые отмечают события создания, обновления и истечения срока действия данных в исходных таблицах. Любой процесс, который вставляет, обновляет или удаляет строку, должен также обновлять соответствующий столбец отметки времени, а полные удаления не допускаются. Хотя реализация этого способа проста, очень мало таблиц в типичной базе данных имеет такие временные метки. Также этот шаблон создает тесную связь между исходной таблицей и кодом ETL-процессов, повышая связность между разными компонентами системы, что усложняет ее развитие.
- минус-запрос, когда между исходной и целевой базой данных создается ссылка, и выполняется SQL-запрос c оператором MINUS для расчета журнала изменений. Этот шаблон приводит к тому, что между исходной и целевой базой данных передается большой объем данных, а потому считается антипаттерном. Более того, этот шаблон работает только в том случае, если исходная и целевая базы данных совпадают по типу и другим параметрам, что часто встречается лишь в линейке продуктов одного вендора, например, Oracle и пр.
Оба вышеописанных шаблона CDC вызывают значительную нагрузку на исходную базу данных. Чтобы снизить ее и сократить нагрузку на сеть, инструменты CDC анализируют логи базы данных для расчета журнала изменений. Каждая база данных, поддерживающая транзакции, сперва записывает любые изменения (вставки, обновления и удаления) в лог для обеспечения целостности транзакций от любых сбоев, пока транзакция все еще находится в процессе выполнения.
Логирование переключаются между активным журналом (журналом повторов) и архивными журналами в зависимости от размера файла или событий временного интервала. В зависимости от требований к задержке данных целевой базы CDC-инструмент может получить доступ к активному или архивным журналам для исходной базы. Чтение только логов исходной базы данных не увеличивает нагрузку на нее, т.к. журнал изменений обычно намного меньше, чем сами таблицы.
Коммерческие CDC-инструменты позволяют синхронизировать источники транзакционных данных с аналитическими базами данных практически в реальном времени, сводя к минимуму воздействие на системы-источники, и поэтому лучше всего подходят для приема данных из часто обновляемых реляционных СУБД. Также они имеют высокую отказоустойчивость, поддерживают облегченные преобразования на лету и устраняют сильную связанность между исходной базой и кодом приема данных. Несмотря на эти преимущества, и готовые, и самописные CDC-решения имеют такой недостаток, как дрейф изменений. Что это такое и чем опасно, мы рассмотрим далее.
Проблема дрейфа изменений в CDC-решениях и способы ее решения
Дрейф изменений происходит, когда несколько внесенных изменений не попадают в историю изменений. Это может произойти по множеству причин, от сбоя CDC-инструмента до неправильной записи события. Чтобы избежать ошибок из-за неверного представления текущем состоянии данных, при любом CDC-приеме необходимо обнаружить дрейф, а затем выполнить согласование с источником, чтобы скорректировать реплику. Для этого нужно реализовать следующие шаги:
- определить, до какого момента времени будет производиться сверка, например, по расписанию или по событию, чтобы создать файл моментов времени для сверки данных;
- определить стратегию обнаружения дрейфа. Проще всего сравнить таблицы в исходной и целевой базе, но извлечение полного набора данных часто занимает много времени, а также создает высокую нагрузку на систему-источник и сеть. Быстрее сравнивать какой-то отдельный показатель, например, количество строк или хэшированную сумму значений в каком-то столбце. Этот способ оперативно покажет наличие проблемы, но потребует дополнительных усилий для поиска конкретных несовпадений на уровне отдельных строк. Альтернативой являются построчные проверки значений или хэша строки, если исходная система может его создать.
Обычно коммерческие CDC-инструменты используют наиболее эффективные способы обнаружения изменений в системах-источниках, используя триггеры (особые хранимые процедуры) БД. Возможность работы со множеством систем-источников обеспечивают коннекторы. В случае самописного решения все это необходимо реализовывать самостоятельно. Чтобы выбрать наиболее подходящий CDC-инструмент, важно помнить про следующие особенности и ограничения готовых и самописных решений:
- репликация измененных данных — это не одноразовая задача, а регулярно выполняемая операция, которая не так-то просто реализуется из-за различий между вендорами СУБД, разных форматов записей и сложностям доступа к логам;
- CDC требует регулярного технического обслуживания. Нужно не просто написать сценарий отслеживания и исправления изменений, но и постоянно корректировать его в зависимости от эволюции систем-источников. Это создает дополнительную нагрузку на дата-инженеров и разработчиков, отвлекая их от других проектов.
Читайте в нашей новой статье, как реализовать потоковый CDC-конвейер на Apache NiFi. А практически освоить проектирование и поддержку современных дата-архитектур в проектах аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей
[elementor-template id=»13619″]
Источники

