 1307
1307 
Содержание
Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров.
Основные концепции Spark-приложений
Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим фреймворком кластере. Это может быть скрипт PySpark, приложение Java или Scala, сеанс SparkSession, запущенный командой spark-shell или spark-sql, AWS EMR Step и пр. Приложение состоит из контейнера драйверов и исполнителей. Драйвер (driver) — это процесс, в котором выполняется метод main() Spark-приложения. Драйвер создает объекты SparkSession и SparkContext и преобразует код в операции преобразования и действия. Напомним, фреймворк предполагает, что над датафреймами можно следующие типы операций:
- преобразования (transformations) – отложенные или ленивые вычисления, которые фактически не выполняются сразу, а после материализации запроса и вызове какого-либо действия. При этом создается план запроса, но сами данные все еще находятся в хранилище и ожидают обработки.
- действия (actions) – функции, запрашивающие вывод. При этом не только создается план запроса, но и оптимизируется оптимизатором Catalyst, а также физический план компилируется в DAG распределенной коллекции данных (RDD), который делится на этапы (stages) и задачи (tasks), выполняемые в кластере. Оптимизированный план запроса генерирует высокоэффективный Java-код, который работает с внутренним представлением данных в формате Tungsten.
Также драйвер создает логические и физические планы, а также планирует и координирует задачи с помощью Cluster Manager. За запуск задач на узлах кластера отвечает исполнитель (executor) — это JVM на одном физическом узле кластера, где могут работать несколько исполнителей.
Когда Spark-приложение вызывает действие, например, collect() или take() над датафреймом, это создает задание (job). Одно задание приводит к одному или нескольким этапам (stage), результатом каждого является одна или несколько задач (task). Одна задача работает на одном разделе и обрабатывается одним исполнителем. Один исполнитель может выполнять одну или несколько задач.
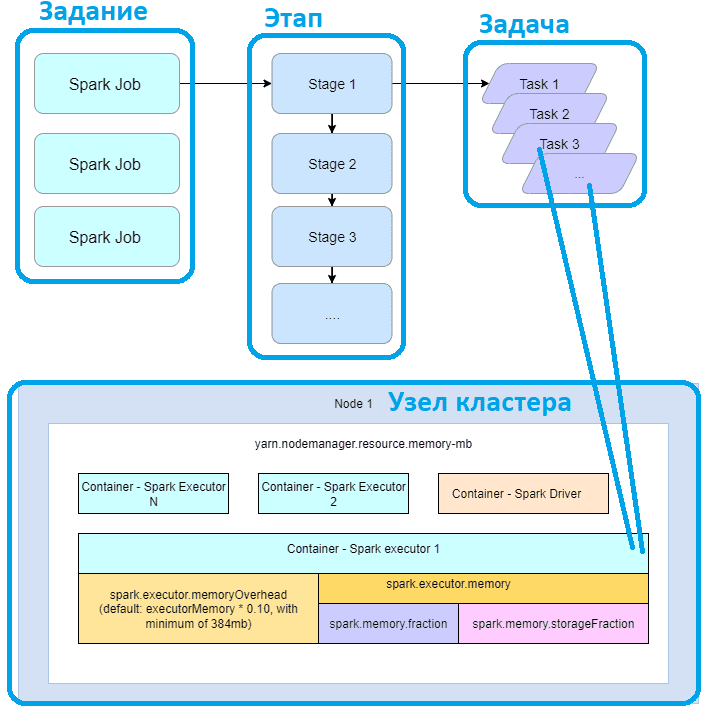
Таким образом, задача — это наименьшая исполнительная единица в Spark, которая выполняет серию инструкций, например, чтение данных, фильтрацию и сопоставление. Задачи выполняются внутри исполнителя. Несколько задач объединяются в этап, в котором каждая задача выполняет один и тот же набор инструкций. Это обеспечивает распараллеливание обработки данных. Можно сказать, что задача – это модуль параллелизма в Spark. Каждая задача сопоставляется с одним ядром и разделом в наборе данных.
Каждое задание преобразуется в направленный ациклический граф (DAG), который включает один или несколько этапов. Этап — это небольшие наборы задач, которые зависят друг от друга. Этапы создаются для каждого задания на основе границ перемешивания, т. е. какие операции могут выполняться последовательно или параллельно. Не все операции или действия могут выполняться на одном этапе без перетасовки данных, поэтому их можно разделить на несколько этапов. Например, операция, связанная с перетасовкой данных, приведет к созданию нового этапа. Если для задания нет перетасовки данных, обычно создается один этап.
Когда в Spark-приложении запускается функция, требующая перетасовки данных, например, reduceByKey(), Join(), создается новый этап. Этапы также создаются при чтении датасета. Приложение состоит из нескольких заданий. Задание создается каждый раз при выполнении действия, например, write(). Как фреймворк планирует и запускает задания в кластере, читайте в нашей новой статье.
Чтобы понять смысл всех этих концепций на практическом примере, рассмотрим следующий сценарий из жизни. Допустим, необходимо организовать поездку в отпуск. Это цель приложения, задание, которое состоит из следующих этапов:
- выбрать место отдыха;
- купить билеты туда и обратно;
- оплатить отель;
- собрать вещи.
На каждом этапе есть несколько задач, например. Выбрать место отдыха включает задачи выбора страны и города, в т.ч. чтение отзывов; покупка билетов включает поиск наиболее оптимального по времени и стоимости способа перемещения (авиа, ж/д, авто), а также оплату этого перемещения и пр. В этом примере этап 3 зависит от этапов 1 и 2.
Освойте все возможности Apache Spark для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
[elementor-template id=»13619″]
Источники
- https://sprinkle-twinkles.medium.com/spark-job-vs-stage-vs-task-in-simple-terms-with-cheat-sheet-fa9fae40c3ed
- https://www.hadoopinrealworld.com/what-are-applications-jobs-stages-and-tasks-in-spark/
- https://kontext.tech/article/1166/spark-basics-application-driver-executor-job-stage-and-task-walkthrough

