В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks.
Много потоковых сценариев в одном приложении Apache Spark Structured Streaming
Мы недавно писали, что архитектуры, управляемые событиями, отлично подходят для микросервисных систем. Тем более, когда речь идет о больших данных, где может быть огромное количество событий (миллионы в минуту), которые нужно хранить, управлять и получать к ним доступ через различные таблицы для использования в автономном и онлайн-режиме. Кроме того, в таких ситуациях обычно работают несколько команд над развитием множества сервисов.
Когда данных и микросервисов немного, справиться с ними может одно приложение Spark на Kubernetes с общим кодом для запуска нескольких потоков в одном развертывании. Каждый поток имеет один и тот же источник и место назначения, но выполняет разные вычисления в зависимости от бизнес-логики и требований команды реализации. Чтобы унифицировать использование одного приложения для разных сценариев, необходим набор предопределенных универсальных преобразований, которые можно использовать для новых потоков по запросу и хранить конфигурации для всех потоков в большом JSON-файле.
Такое решение перестает быть удобным по мере роста бизнеса: количество запросов на создание, изменение и удаление потоков увеличивается. Каждый объект в массиве JSON представляет собой один поток, и каждое изменение в этом файле требует ручного перезапуска кластера приложений Apache Spark, чтобы перезагрузить их. Это приводит к прерыванию текущих заданий, выполняемых активными потоками и повторным вычислениям с последней контрольной точки. А кластер Kubernetes должен перераспределить огромное количество ресурсов во время планирования подов из-за удаления и создания приложения.
Чтобы управлять возросшим объемом запросов, необходимо модернизировать и регламентировать процесс, определяющий, как команды могут запрашивать изменения потоков. В общем случае шагами этого процесса будут следующие:
- создать шаблон заявки со всей необходимой информацией;
- обсудить предлагаемые изменения с одной или несколькими командами, чтобы дата-инженеры могли проверить и одобрить запрос.
На эти организационные моменты уходит много времени, чтобы просто выровнять поток со всеми остальными и создать нужные интеграции данных. Поэтому целесообразно сделать изменение сценариев использования потоковой обработки данных самообслуживаемой услугой, которая может запрашиваться пользователями в любое время и выполняться автоматически без привлечение дата-инженеров. Как это сделать, имея озеро данных в облачном объектном хранилище AWS S3, рассмотрим далее.
Самообслуживаемое озеро данных с Delta таблицами Databricks
В микросервисной архитектуре все сервисы управляются структурированными событиями, валидацию которых можно реализовать через реестр схем Apache Kafka. Если озеро данных на AWS S3 хранит колоночные Parquet-файлы в виде дельта-таблиц, выход каждого потока представляет собой такую таблицу изменений, которые отражаются в корпоративном хранилище данных через внешние таблицы. Чтобы поддерживать ACID-транзакции и масштабируемую обработку метаданных, объединяя потоковые и пакетные операции с большими данными, поверх озера данных можно развернуть Delta Lake — коммерческую платформу Databricks, способную работать на базе любого озера данных (на HDFS, S3 или Azure Data Lake Storage) и полностью совместимую со всеми API Apache Spark. Подробнее о преимуществах и принципах работы Delta Lake мы писали здесь.
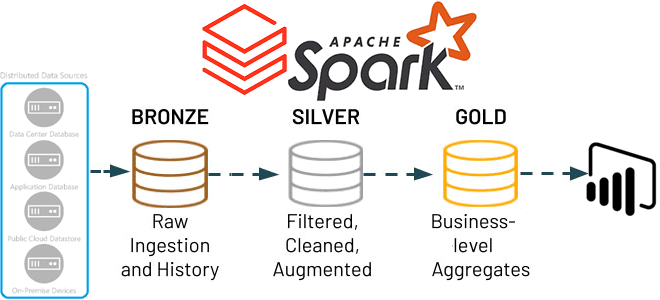
Delta Lake имеет каноническую архитектуру Databricks Medallion, которая использует преимущества реализации Apache Delta в 3 слоя:
- Бронза, где хранятся необработанные (сырые) данные из исходных систем;
- Серебро, где данные с предыдущего слоя отфильтрованы, очищены и обогащены. Прежде, чем использовать необработанные данные в ETL-заданиях или запросах, их следует тщательно подготовить. Проблема с этой очисткой заключается в том, что ее необходимо выполнять в каждом задании перед публикацией данных для последующих потребителей. Таким образом, лучше иметь отдельную таблицу, в которой есть проверенные, спроецированные (требуются только столбцы) допустимые строки для удаления повторяющихся данных, допускающих значение NULL. Можно избежать выполнения операции очистки в каждом задании и внедрения ограничений на уровне строк и столбцов для данных с использованием ключевого слова CONSTRAINT при создании таблиц.
- Золото, где располагаются агрегаты бизнес-уровня. По сути, это окончательные выходные таблицы, которые можно использовать непосредственно для визуализации данных и BI-запросов.
Динамические таблицы, представленные Databricks, упрощают создание конвейеров данных и управление ими, которые доставляют тщательно отобранные высококачественные данные в Delta Lake. Это упрощает создание конвейера данных благодаря декларативной модели конвейера, автоматическому тестированию данных, меньшему количеству подробных сведений, большему количеству информации о мониторинге заданий и восстановлении. Просто указав источник данных, логику преобразования и целевую систему, дата-инженер может построить надежные сквозные конвейеры данных.
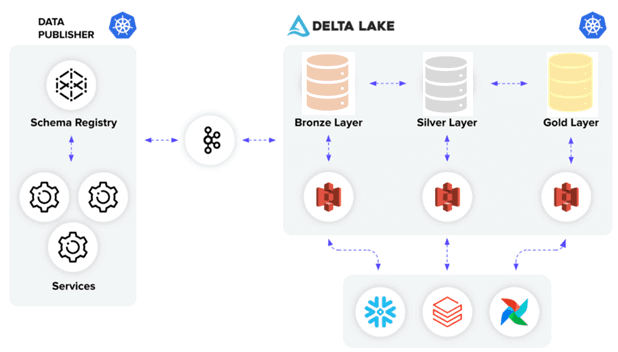
На каждом уровне Delta Lake работает потоковое приложение Spark, которое запускает все потоки пользователей в соответствии с сущностью этого уровня. Каждый поток имеет следующие интеграции:
- запланированные задания AirFlow для оптимизации и очистки каждой дельта-таблицы с целью повышения производительности запросов;
- внешние таблицы Snowflake в озере данных для легкого доступа к дельта-таблицам;
- внешние таблицы Databricks в качестве второго выбора для доступа к дельта-таблицам.
Сделать самообслуживаемый сервис работы с Delta Lake можно, автоматизировав управление конфигурациями потоков в постоянном хранилище через REST API. Такой REST API управляет потоками как ресурсом, позволяя выполнять над ними CRUD-операции. Это позволяет пользователям и командам разработки выполнять свои собственные потоковые запросы, самостоятельно делая простой вызов API к самообслуживаемому сервису, который уже проверяет запрос.
Кроме того, хранение конфигураций потоков в базе данных, а не в огромном JSON-файле позволяет избежать синтаксических ошибок его редактирования, предоставляет возможности аудита и повышает прозрачность сервиса. Уменьшить нагрузку на перезапуск Spark-приложения при каждом изменении конфигурации потока позволяет легкий REST API (на основе Akka HTTP) внутри драйвера Spark. Он прослушивает простые вызовы start/stop и может фактически запускать и останавливать активные потоки через Spark StreamingQuery API.
Читайте в нашей новой статье про проектирование хранилища данных с методологией Data Vault в архитектуре Lakehouse. А здесь вы узнаете, как реализовать слоистую архитектуру данных Medallion на колоночной БД ClickHouse.
Код курса
SPAD
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0
Освойте администрирование и эксплуатацию Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Архитектура данных с Apache Spark
Источники

