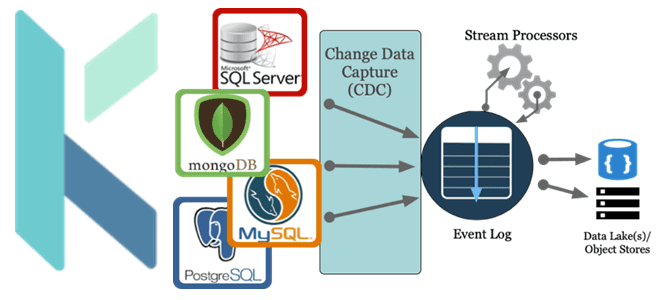
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
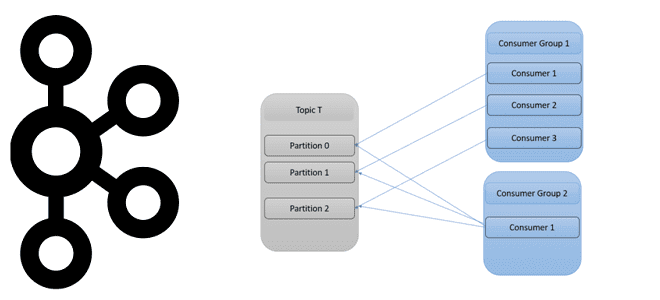
Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем. Как работают группы потребителей в Apache Kafka Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями...
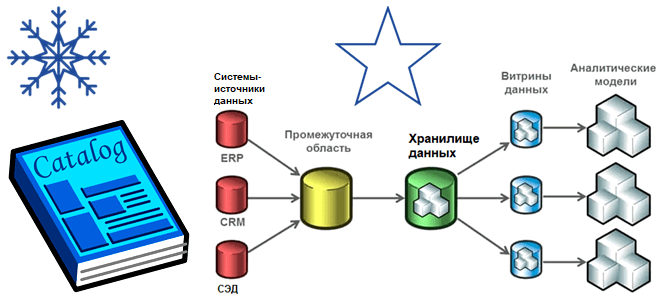
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...
Как использовать мощь Apache Kafka в ИТ-архитектуре корпоративных приложений и интеграции информационных систем: краткий ликбез по ключевым принципам работы этой платформы потоковой передачи событий и важность дата-контрактов для инженера данных, разработчика и архитектора. 9 лучших практик использования Apache Kafka в архитектуре приложений Чтобы успешно применять Apache Kafka в качестве основной...
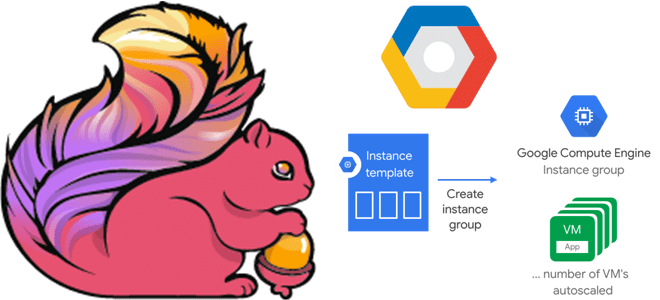
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Сегодня поговорим про основные программные компоненты и принципы работы Apache AirFlow: как DAG состоит из задач, в чем разница между операторами и датчиками, зачем нужны правила триггеров, а также каким образом фреймворк защищает переменные. DAG и задачи: зависимости, состояния, триггеры Основной концепцией Apache AirFlow является DAG – направленный ациклический граф,...

Чтобы добавить в наши курсы по аналитики больших данных еще больше практически примеров, сегодня рассмотрим, как современные технологий Big Data помогают в реальном времени выявлять телекоммуникационные мошенничества. Почему для антифрод-задач особенно подходит Apache Flink с его потоковом движком обработки данных и за счет чего этот фреймворк такой быстрый. Антифрод в...

В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...
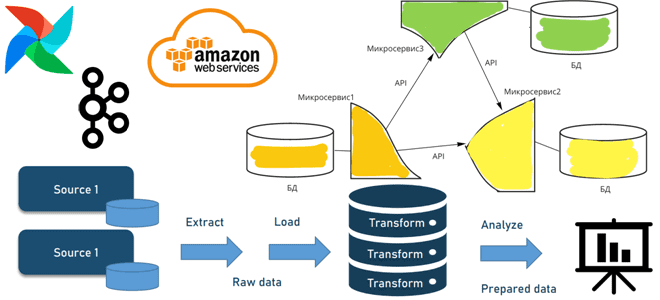
Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka. От пакетов к потокам через микросервисы: архитектура...
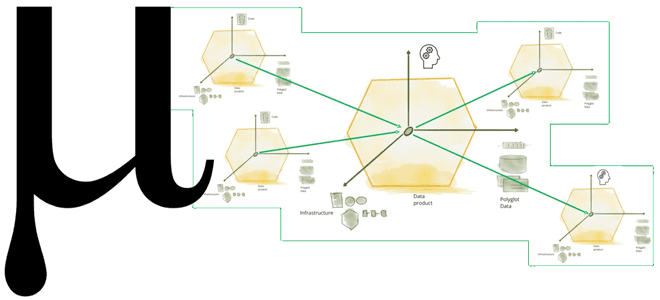
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...