
Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии.
Почему не стоит использовать СУБД вместо очереди сообщений
Dagster Cloud — это платформа организации конвейеров данных, конкурент Apache AirFlow в реализации Astro, о чем мы писали здесь и здесь. Dagster Cloud включает два основных компонента:
- планировщик, который запускает конвейеры данных;
- система логирования, которая собирает структурированную и неструктурированную информацию о конвейерах и сообщает ее пользователю через GUI.
По мере выполнения конвейер данных выдает множество журналов событий, которые нужно хранить и индексировать для отображения в пользовательском интерфейсе в режиме реального времени. Обычно такая задача реализуется с помощью платформ типа Apache Kafka, где организуется упорядоченная очередь сообщений только для добавления, структурированная по топикам. Когда данных, поступающих от клиентов, много, их следует обрабатывать масштабируемым и экономичным способом. С этим отлично справляется платформа потоковой передачи событий Apache Kafka.
Однако, при всех преимуществах этой технологии, она требует значительных затрат на развертывание и сопровождение инфраструктуры. Поэтому на практике команды реализации часто выбирают более простые способы решения задачи, даже если эти инструменты обычно используются в других сценариях. В случае Dagster Cloud, команда реализации часто использовала PostgreSQL в разных проектах и решила применить эту объектно-ориентированную базу данных как очередь сообщений.
Но использование реляционной базы данных в качестве очереди сообщений считается антипаттерном, поскольку СУБД работают медленнее, а прямой доступ к базе для организации совместной работы нескольких сервисов – плохая практика, о чем мы писали здесь. Рассмотрим эти возражения более подробно. Предположим, необходимо обработать с помощью ряда различных приложений или процессов таблицу с некоторыми данными и столбцом состояния. Каждый процесс предназначен для обработки данных в определенном состоянии. Например, процесс 1 вставляет записи со статусом «Новая», которые выбирает процесс 2 и обновляет статус их на «Завершенный», а процесс 3 далее снова меняет их статус.
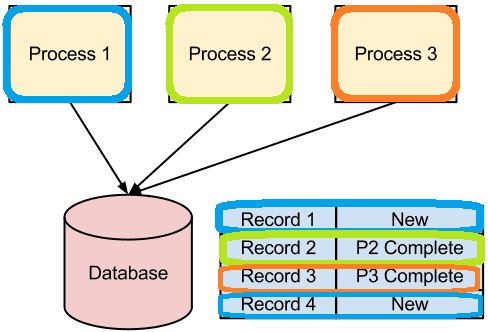
При этом каждый процесс опрашивает базу данных с некоторым интервалом, выполняя оператор SELECT:
SELECT * FROM MyWorkflow WHERE Status = 'New'
Реализация такой очереди сообщений в реляционной СУБД считается антипаттерном из-за периодов опроса. В коротком интервале база данных заполняется слишком быстро, а в длинном – работа получается слишком медленной. Кроме того, сервер реляционной СУБД очень эффективен при вставках, обновлениях или SQL-запросах, но не одновременно в одной таблице. Чтобы выполнять запросы опроса эффективно, нужно поместить проиндексировать состояние, но индексы делают вставки медленными, а блокировки могут стать серьезной проблемой.
Также есть проблема удаления записей после завершения рабочего процесса. Если не очищать таблицу через определенные промежутки времени, она будет продолжать расти, пока не начнет снижать производительность запросов и. Это в итоге не станет серьезной операционной проблемой, т.к. удаления в этой технологии не очень эффективны.
Наконец, как уже было отмечено, совместное использование базы данных между несколькими приложениями на практике затруднительно из-за необходимости передачи учетных данных для доступа в базу. При интеграции с внешними приложениями это просто невозможно: редкая команда даст такие чувствительные данные сторонними сервису.
Распределенная система обмена сообщениями типа Apache Kafka избавляет от всех этих проблем: нет необходимости опросов, удаления завершенных сообщений из очередей и общего состояния. Впрочем, несмотря на это, команда Dagster Cloud все равно предпочла использовать хорошо знакомую PostgreSQL вместо неизвестной им Kafka, изобретя собственный велосипед на других архитектурных паттернах вокруг реляционной СУБД. Как это было сделано, рассмотрим далее.
Но почему команда Dagster Cloud все-таки выбрала этот антипаттерн
Прежде всего, чтобы подтвердить или опровергнуть возможные трудности с производительностью, разработчики ETL-оркестратора сперва измерили показатели своих целей уровня обслуживания (SLO) с помощью системы мониторинга Datadog. А затем определили рабочую нагрузку как максимально возможное количество одновременно работающих пользователей + 10-20%.
Нагрузочные тесты, имитирующие сценарии реального использования на тестовом кластере PostgreSQL определить оптимальный размер экземпляра базы данных и облачного инстанса в AWS. Также в рамках тестирования был найден оптимальный интервал опроса и индексируемые столбцы.
Проблему масштабирования, связанную с неограниченным ростом базы данных, удалось решить с помощью системы архивации журналов с разделением путей записи и чтения согласно CQRS-паттерну (Command and Query Responsibility Segregation):
- специально созданная системная служба выбирает записи журнала старше двух недель, копирует их в файл на AWS S3 и удаляет строки из базы данных;
- веб-приложение просматривает период времени, за который запрашиваются журналы, и динамически решает запросить базу данных или объектное облачное хранилище AWS
Эта система архивирования журналов существенно уменьшила общий размер базы данных, значительно замедлила ее рост и оказала незначительное влияние на работу пользователей. А чтобы сделать процесс логирования более равномерным, сгладив всплески объема базы данных из-за ошибок разработчиков, был введен ограничитель скорости. Когда клиент регистрировал слишком много событий определенного типа в течение короткого промежутка времени, API-серверы начинали возвращать код HTTP-ответа 429: Too Many Requests HTTP, заставляя клиентов ограничивать запросы. Этот ограничитель скорости логирования не зависит от PostgreSQL: его конфигурация хранится в Kubernetes ConfigMap, а счетчики в Redis. Также он поддерживает различные ограничения скорости в зависимости от важности сообщения от клиентов, позволяя приоритизировать их в соответствии с SLA. Ограничитель отклоняет менее важные сообщения до того, как начнет отклонять более важные, а также поддерживает ограничение скорости по стоимости базы данных. Можно выделить развертываниям отдельных клиентов определенную квоту — время, которое клиенты могут потратить на запросы к базе данных. Если этот порог превышен, клиентам ограничивается скорость неправильного развертывания.
Что касается высокой надежности, гарантии доступности и способности быстро восстанавливаться после сбоя, свойственных распределенной системе потоковой передачи событий, такой как Kafka, то очередь сообщения на PostgreSQL, реализованная командой Dagster Cloud, обеспечивает эти свойства за счет инфраструктуры облачного провайдера. В частности, AWS RDS допускает горячее резервирование и быстрое переключение на реплики, сводя простои из-за сбоя к нескольким секундам.
Справедливости ради, стоит отметить, что изобретение собственного велосипеда на PostgreSQL вместо очереди сообщений в команде Dagster Cloud не стало идеальным решением. В частности, не удалось избежать «зоопарка систем», используя только Postgres. Пришлось также развернуть NoSQL-СУБД Redis для некоторых менее важных временных потоков событий, поскольку применяемая Python-библиотека очередей не поддерживала Postgres. Однако, key-value база данных Redis вызвала ряд инцидентов, поэтому в будущем от нее придется отказаться. Кроме того, текущее решение не позволяет поддерживать ряд регионов за пределами США, а некорректно работающая внутренняя служба может отключить базу данных для всех пользователей. Наконец, постоянная настройка PostgreSQL на пиковую нагрузку неэффективна с экономической точки зрения. Таким образом, система логирования Dagster Cloud на реляционной базе данных вместо очереди сообщений носит временный характер и будет заменена на Kafka, другую распределенную очередь или NoSQL-решения типа CockroachDB или DynamoDB.
Завтра мы продолжим разговор про лучшие практики и антипаттерны применения Apache Kafka в микросервисной архитектуре.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей
Источники

