 1035
1035 
Содержание
Недавно мы писали про сравнения технологий потоковой аналитики больших данных и аналитических баз данных реального времени на примере сравнения ksqlDB и Rockset. Продолжая этот разговор про архитектуру данных и приложений, сегодня рассмотрим сходства и отличия потоковых баз данных со stateful-приложениями обработки событий в реальном времени.
2 технологии потоковой обработки: stateful-приложения и OLAP базы данных
Приложение потоковой обработки представляет собой направленный ациклический граф (Directed Acyclic Graph, DAG), узлами которого являются отдельные функции. Они выполняют операции, когда поток данных проходит через них. Эти функции могут быть stateless-операциями без сохранения состояния, такими как преобразования или фильтрация, или stateful-операциями с отслеживанием состояния, такими как агрегаты, запоминающие результат предыдущего выполнения. Потоковая обработка с отслеживанием состояния используется для получения информации из потоковых данных.
Потоковые базы данных могут принимать данные из источников потоковых данных и немедленно делать их доступными для запросов. Они расширяют потоковую stateful-обработку и привносят дополнительные функции баз данных, включая поддержку колоночных форматов файлов, индексирование, материализованные представления и выполнение сложных SQL-запросов. Потоковые базы данных можно разделить на 2 категории: материализованные представления с инкрементным обновлением и аналитические базы данных (OLAP) в реальном времени, которые мы рассматривали здесь на примере Rockset.
Чтобы сравнить эти stateful-приложения потоковой обработки с потоковыми базами данных, оценим их по следующим критериям:
- прием потоковых данных и сохранение состояния;
- запрос состояния;
- размещение логики управления состоянием;
- реализация логики манипулирования состоянием;
- размещение на конвейере потокового ETL
- сценарии использования.
Прием потоковых данных и сохранение состояния
Обе технологии могут получать данные из потоковых источников данных, таких как Kafka, Pulsar, Redpanda, Kinesis и пр., и анализировать их «на лету». У них также есть надежные стратегии водяных знаков для обработки запаздывающих данных. Однако, когда дело доходит до сохранения состояния, stateful-приложения и потоковые базы данных ведут себя по-разному.
Потоковые процессоры разбивают состояние и материализуют его на локальный диск для повышения производительности. Это локальное состояние периодически реплицируется на удаленный сервер состояния для обеспечения отказоустойчивости, что называется созданием контрольной точки (checkpoint) в большинстве технологий потоковой передачи с отслеживанием состояния. Яркими примерами этого являются stateful-приложения Apache Spark и Flink, о чем мы упоминали здесь и здесь.
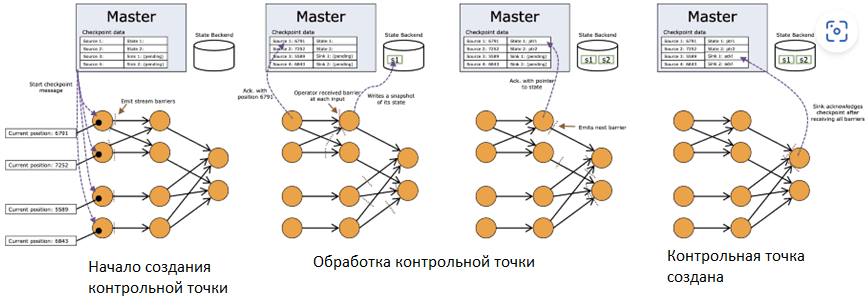
Потоковые базы данных используют другой подход, сначала записывая принятые данные в сегменты – колоночные файлы на диске колоночных форматов, оптимизированных для аналитических SQL-запросов в реальном времени (OLAP). Сегменты реплицируются по всему кластеру для обеспечения масштабируемости и отказоустойчивости.
Запрос состояния
В потоковых stateful-приложениях из-за разделения состояния на несколько экземпляров, один узел потокового процессора содержит только подмножество всего состояния. Необходимо связаться с несколькими узлами, чтобы выполнить интерактивный запрос для полного состояния. При этом не всегда точно известно, к каким узлам надо обратиться.
Впрочем, многие потоковые процессоры предоставляют конечные точки для выполнения интерактивных запросов к состоянию, например, хранилища состояний в Kafka Streams. Однако, они не очень хорошо масштабируются. В качестве альтернативы потоковые процессоры могут записывать агрегированное состояние в оптимизированное для чтения NoSQL-хранилище типа «ключ-значение», чтобы снизить сложность запросов.
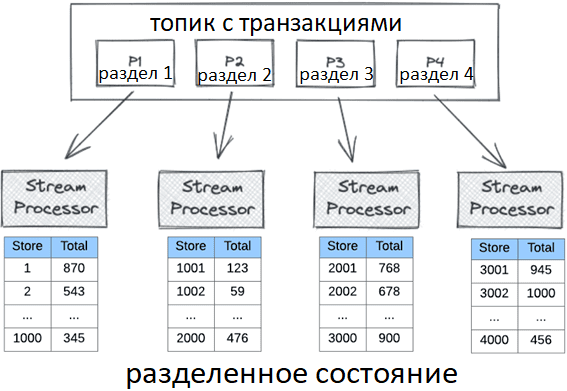
Потоковые базы данных ведут себя аналогично классическим OLAP-хранилищам, используя планировщики запросов, индексы и интеллектуальные методы сокращения запросов для повышения пропускной способности и сокращения задержек обработки данных. Как только потоковая база данных получает запрос, брокер запросов распределяет его по узлам, на которых размещены соответствующие сегменты. Запрос выполняется локально для узла. Брокер собирает результаты, агрегирует их и возвращает вызывающей стороне.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
15 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Размещение логики управления состоянием
Потоковые процессоры в stateful-приложениях требуют, чтобы логика манипулирования состоянием была заранее известна и встроена в поток обработки данных. Например, чтобы вычислить промежуточную сумму событий, следует сперва написать логику в виде задания потоковой обработки, скомпилировать ее, упаковать и развернуть во всех экземплярах потокового процессора.
Потоковые базы данных переносят логику манипулирования состоянием в приложение-потребитель, которое манипулирует принятым состоянием так, как это требуется в конкретный момент времени, «по месту».
Реализация логики манипулирования состоянием
Потоковые процессоры в stateful-приложениях предоставляют множество интерфейсов для реализации логики доступа к состоянию и управления им. Разработчик пишет поток данных, используя любой язык программирования (Java, Scala, Python, Go и пр.), а потоковый процессор преобразует этот код в оптимизированный DAG и распределяет по кластеру. Можно также использовать язык SQL-запросов, однако, «классические» языки программирования дают больше контроля и гибкости.
В потоковых базах данных SQL является основным интерфейсом для доступа к состоянию, обеспечивая универсальный, декларативный и лаконичный подход и плавную интеграцию с нижестоящими потребителями, такими как инструменты бизнес-аналитики и отчетности, т.е. BI-системы.
Размещение на потоковом ETL-конвейере
С помощью потоковых процессоров в stateful-приложениях разработчик определяет логику обработки в виде DAG-графа, который имеет источник и приемник потока данных. Когда этот DAG выполняется, вход потокового процессора может оказаться в другом месте, включая другой узел кластера или среду выполнения. Таким образом, потоковые процессоры могут выполнять потоковые ETL-операции, которые предварительно обрабатывают данные перед записью на диск или в другую систему. Например, можно соединять потоки для обогащения, фильтрации нежелательных данных и выполнения оконных агрегаций перед записью окончательного вывода.

Потоковые базы данных не очень хорошо выполняют предварительную обработку данных. Хотя они по-прежнему могут выполнять поисковые соединения с небольшими статическими таблицами и некоторые упрощенные преобразования во время приема данных, в целом эти технологии не предназначены для сложной обработки массовых потоков. Таким образом, потоковые stateful-приложения на самом деле располагаются в середине потокового ETL-конвейера, а потоковые базы данных размещаются на стороне обслуживания, т.е. в точке окончания этого конвейера.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что и когда выбирать: варианты использования
Обычно после развертывания логики управления состоянием потоковые stateful-приложения работают автоматизировано или автоматически, без ручного вмешательства. Поэтому эта технология идеально подходит для случаев, когда нужно принимать быстрые решения с минимальным человеческим участием. Например, обнаружение аномалий, генерация персональных предложений в режиме реального времени, мониторинг и оповещение — в этих случаях принятие решений может быть максимально автоматизировано.
Потоковые базы данных подходят для сценариев с меньшей автоматизацией, к примеру, для систем поддержки принятия управленческих решений, когда решения принимают люди, запрашивая состояние через приложение, BI-дэшборды или API.
Потоковые stateful-приложения позволяют заранее определить, как управлять состоянием. Они идеально подходят для таких сценариев использования, где необходимо принимать решения с малой задержкой и минимальным вмешательством человека. Также эта теънология подходит, если потоковые данные нуждаются в дополнительной очистке и обработке перед принятием окончательного решения, т.е. нужно организовать потоковый ETL-конвейер. Если же нужен быстрый доступ к материализованному состоянию, можно записать его в базу данных, оптимизированную для чтения, и выполнять к ней SQL-запросы.
Потоковые базы данных идеально подходят для случаев, когда нельзя заранее определить шаблоны доступа к данным или не нужны сложные преобразования входящих данных, а ETL-конвейер заканчивается на уровне обслуживания. О том, как выбрать потоковую СУБД, читайте в нашей новой статье.
Впрочем, сегодня четкие границы между потоковыми stateful-приложениями и базами данных начали стираться: обе эти технологии пытаются решить одну и ту же проблему разными способами. Выбор должен определяться сценарием использования, особенностями инфраструктуры и компетенциями команды. Кроме того, можно попробовать совместить их в рамках одного развертывания. Например, использовать потоковое stateful-приложение для запуска ETL-сценариев, оконных операций и обнаружения аномалий на потоковом процессоре. А база данных потоковой передачи пригодится для сбора обогащенных и очищенных выходных данных из потокового процессора, чтобы предоставить их для запросов извне масштабируемым образом. Именно такой комбинированный вариант предлагают некоторые современные платформы самообслуживания, такие как Materialise, RisingWave и DeltaStream. Практический пример работы с RisingWave показан в нашей новой статье.

Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей
Источники

